 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataEvolver: Let Your Data Build and Improve Itself via Goal-Driven Loop Agents
May 03, 2026Constructing controllable visual data is a major bottleneck for image editing and multimodal understanding. Useful supervision is rarely produced by a single rendering pass; instead it emerges through iterative generation, inspection, correction, filtering, and export. We present DataEvolver, a closed-loop visual data engine that organizes this process around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. DataEvolver supports multiple artifact types, including RGB images, masks, depth maps, normal maps, meshes, poses, trajectories, and review traces. In the current release, the system operates through two coupled loops: generation-time self-correction within each sample and validation-time self-expansion across dataset rounds. We validate the framework on an image-level object-rotation setting. With a fixed Qwen-Edit LoRA probe, our final Ours+DualGate model outperforms both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations show a consistent improvement path from scene-aware generation to feedback-driven correction and dual-gated validation. Beyond the released rotation data, our main contribution is a reusable framework for building visual datasets through explicit goal tracking, review, correction, and acceptance loops.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Cross Architecture Distillation for Face Recognition
Jun 26, 2023


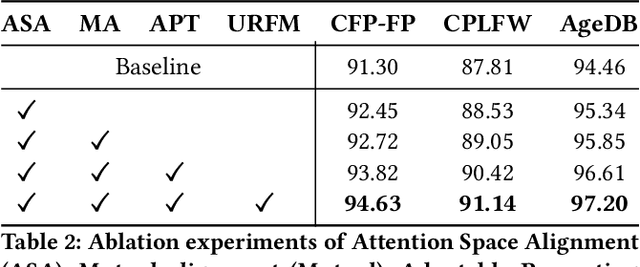
Transformers have emerged as the superior choice for face recognition tasks, but their insufficient platform acceleration hinders their application on mobile devices. In contrast, Convolutional Neural Networks (CNNs) capitalize on hardware-compatible acceleration libraries. Consequently, it has become indispensable to preserve the distillation efficacy when transferring knowledge from a Transformer-based teacher model to a CNN-based student model, known as Cross-Architecture Knowledge Distillation (CAKD). Despite its potential, the deployment of CAKD in face recognition encounters two challenges: 1) the teacher and student share disparate spatial information for each pixel, obstructing the alignment of feature space, and 2) the teacher network is not trained in the role of a teacher, lacking proficiency in handling distillation-specific knowledge. To surmount these two constraints, 1) we first introduce a Unified Receptive Fields Mapping module (URFM) that maps pixel features of the teacher and student into local features with unified receptive fields, thereby synchronizing the pixel-wise spatial information of teacher and student. Subsequently, 2) we develop an Adaptable Prompting Teacher network (APT) that integrates prompts into the teacher, enabling it to manage distillation-specific knowledge while preserving the model's discriminative capacity. Extensive experiments on popular face benchmarks and two large-scale verification sets demonstrate the superiority of our method.