 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbor-Vote: Improving Monocular 3D Object Detection through Neighbor Distance Voting
Jul 06, 2021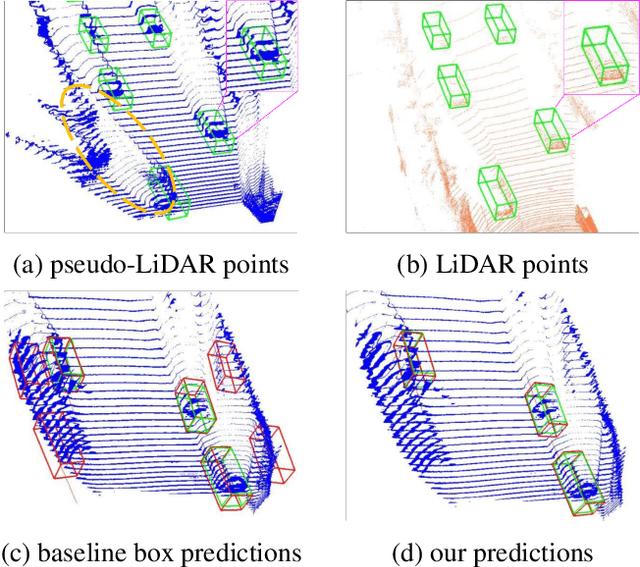



As cameras are increasingly deployed in new application domains such as autonomous driving, performing 3D object detection on monocular images becomes an important task for visual scene understanding. Recent advances on monocular 3D object detection mainly rely on the ``pseudo-LiDAR'' generation, which performs monocular depth estimation and lifts the 2D pixels to pseudo 3D points. However, depth estimation from monocular images, due to its poor accuracy, leads to inevitable position shift of pseudo-LiDAR points within the object. Therefore, the predicted bounding boxes may suffer from inaccurate location and deformed shape. In this paper, we present a novel neighbor-voting method that incorporates neighbor predictions to ameliorate object detection from severely deformed pseudo-LiDAR point clouds. Specifically, each feature point around the object forms their own predictions, and then the ``consensus'' is achieved through voting. In this way, we can effectively combine the neighbors' predictions with local prediction and achieve more accurate 3D detection. To further enlarge the difference between the foreground region of interest (ROI) pseudo-LiDAR points and the background points, we also encode the ROI prediction scores of 2D foreground pixels into the corresponding pseudo-LiDAR points. We conduct extensive experiments on the KITTI benchmark to validate the merits of our proposed method. Our results on the bird's eye view detection outperform the state-of-the-art performance by a large margin, especially for the ``hard'' level detection.
Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection in Autonomous Driving
Nov 27, 2020

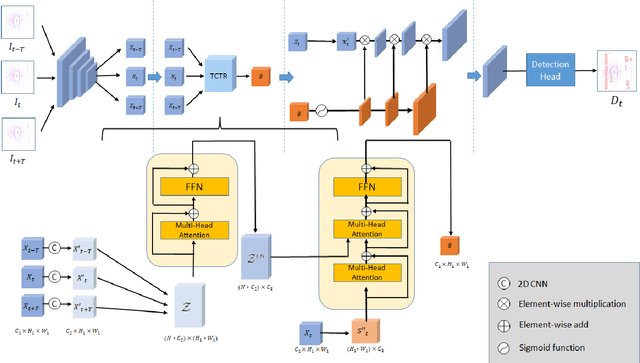

The strong demand of autonomous driving in the industry has lead to strong interest in 3D object detection and resulted in many excellent 3D object detection algorithms. However, the vast majority of algorithms only model single-frame data, ignoring the temporal information of the sequence of data. In this work, we propose a new transformer, called Temporal-Channel Transformer, to model the spatial-temporal domain and channel domain relationships for video object detecting from Lidar data. As a special design of this transformer, the information encoded in the encoder is different from that in the decoder, i.e. the encoder encodes temporal-channel information of multiple frames while the decoder decodes the spatial-channel information for the current frame in a voxel-wise manner. Specifically, the temporal-channel encoder of the transformer is designed to encode the information of different channels and frames by utilizing the correlation among features from different channels and frames. On the other hand, the spatial decoder of the transformer will decode the information for each location of the current frame. Before conducting the object detection with detection head, the gate mechanism is deployed for re-calibrating the features of current frame, which filters out the object irrelevant information by repetitively refine the representation of target frame along with the up-sampling process. Experimental results show that we achieve the state-of-the-art performance in grid voxel-based 3D object detection on the nuScenes benchmark.
Spatial and Temporal Mutual Promotion for Video-based Person Re-identification
Dec 26, 2018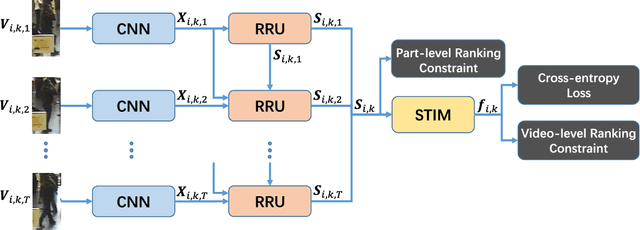
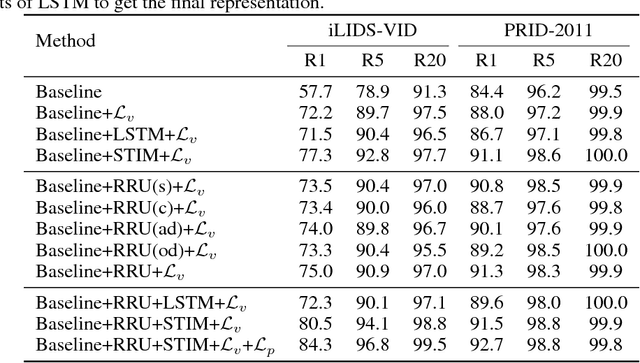
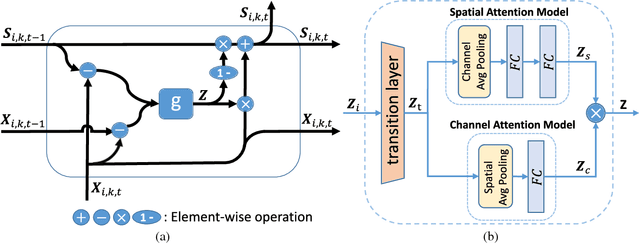
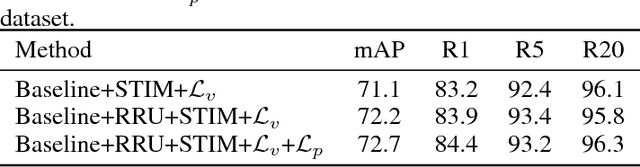
Video-based person re-identification is a crucial task of matching video sequences of a person across multiple camera views. Generally, features directly extracted from a single frame suffer from occlusion, blur, illumination and posture changes. This leads to false activation or missing activation in some regions, which corrupts the appearance and motion representation. How to explore the abundant spatial-temporal information in video sequences is the key to solve this problem. To this end, we propose a Refining Recurrent Unit (RRU) that recovers the missing parts and suppresses noisy parts of the current frame's features by referring historical frames. With RRU, the quality of each frame's appearance representation is improved. Then we use the Spatial-Temporal clues Integration Module (STIM) to mine the spatial-temporal information from those upgraded features. Meanwhile, the multi-level training objective is used to enhance the capability of RRU and STIM. Through the cooperation of those modules, the spatial and temporal features mutually promote each other and the final spatial-temporal feature representation is more discriminative and robust. Extensive experiments are conducted on three challenging datasets, i.e., iLIDS-VID, PRID-2011 and MARS. The experimental results demonstrate that our approach outperforms existing state-of-the-art methods of video-based person re-identification on iLIDS-VID and MARS and achieves favorable results on PRID-2011.