 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial and Temporal Mutual Promotion for Video-based Person Re-identification
Paper and Code
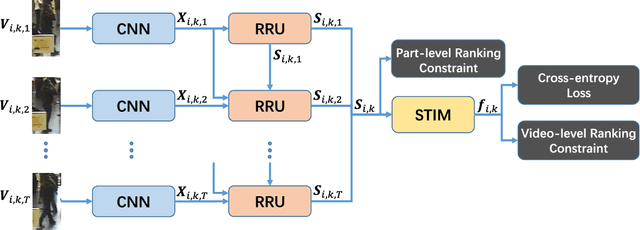
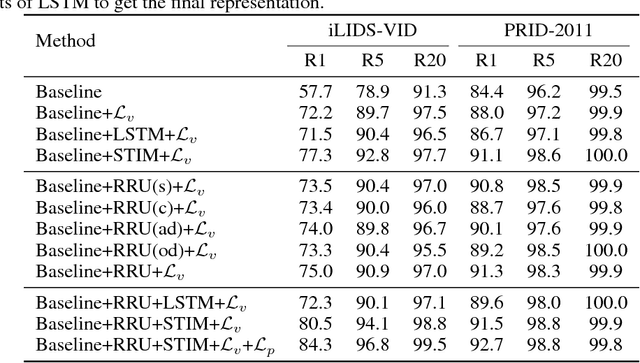
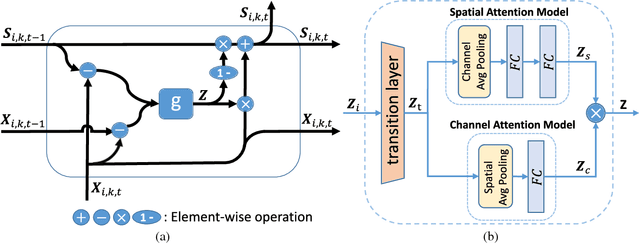
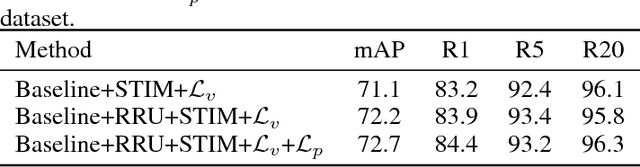
Video-based person re-identification is a crucial task of matching video sequences of a person across multiple camera views. Generally, features directly extracted from a single frame suffer from occlusion, blur, illumination and posture changes. This leads to false activation or missing activation in some regions, which corrupts the appearance and motion representation. How to explore the abundant spatial-temporal information in video sequences is the key to solve this problem. To this end, we propose a Refining Recurrent Unit (RRU) that recovers the missing parts and suppresses noisy parts of the current frame's features by referring historical frames. With RRU, the quality of each frame's appearance representation is improved. Then we use the Spatial-Temporal clues Integration Module (STIM) to mine the spatial-temporal information from those upgraded features. Meanwhile, the multi-level training objective is used to enhance the capability of RRU and STIM. Through the cooperation of those modules, the spatial and temporal features mutually promote each other and the final spatial-temporal feature representation is more discriminative and robust. Extensive experiments are conducted on three challenging datasets, i.e., iLIDS-VID, PRID-2011 and MARS. The experimental results demonstrate that our approach outperforms existing state-of-the-art methods of video-based person re-identification on iLIDS-VID and MARS and achieves favorable results on PRID-2011.