 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRunning VLAs at Real-time Speed
Oct 30, 2025In this paper, we show how to run pi0-level multi-view VLA at 30Hz frame rate and at most 480Hz trajectory frequency using a single consumer GPU. This enables dynamic and real-time tasks that were previously believed to be unattainable by large VLA models. To achieve it, we introduce a bag of strategies to eliminate the overheads in model inference. The real-world experiment shows that the pi0 policy with our strategy achieves a 100% success rate in grasping a falling pen task. Based on the results, we further propose a full streaming inference framework for real-time robot control of VLA. Code is available at https://github.com/Dexmal/realtime-vla.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Compound Text-Guided Prompt Tuning via Image-Adaptive Cues
Dec 11, 2023

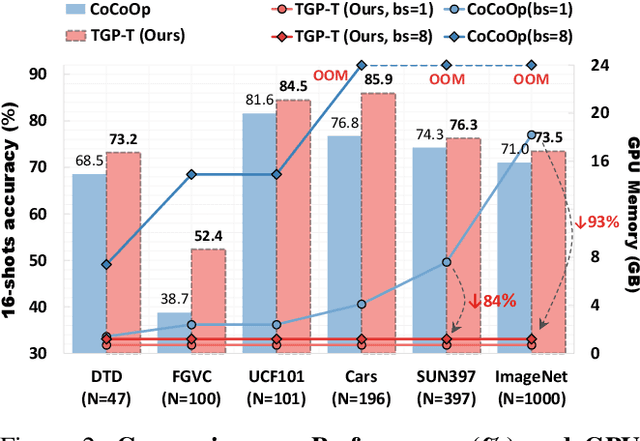

Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable generalization capabilities to downstream tasks. However, existing prompt tuning based frameworks need to parallelize learnable textual inputs for all categories, suffering from massive GPU memory consumption when there is a large number of categories in the target dataset. Moreover, previous works require to include category names within prompts, exhibiting subpar performance when dealing with ambiguous category names. To address these shortcomings, we propose Compound Text-Guided Prompt Tuning (TGP-T) that significantly reduces resource demand while achieving superior performance. We introduce text supervision to the optimization of prompts, which enables two benefits: 1) releasing the model reliance on the pre-defined category names during inference, thereby enabling more flexible prompt generation; 2) reducing the number of inputs to the text encoder, which decreases GPU memory consumption significantly. Specifically, we found that compound text supervisions, i.e., category-wise and content-wise, is highly effective, since they provide inter-class separability and capture intra-class variations, respectively. Moreover, we condition the prompt generation on visual features through a module called Bonder, which facilitates the alignment between prompts and visual features. Extensive experiments on few-shot recognition and domain generalization demonstrate that TGP-T achieves superior performance with consistently lower training costs. It reduces GPU memory usage by 93% and attains a 2.5% performance gain on 16-shot ImageNet. The code is available at https://github.com/EricTan7/TGP-T.
Reversible Column Networks
Dec 22, 2022



We propose a new neural network design paradigm Reversible Column Network (RevCol). The main body of RevCol is composed of multiple copies of subnetworks, named columns respectively, between which multi-level reversible connections are employed. Such architectural scheme attributes RevCol very different behavior from conventional networks: during forward propagation, features in RevCol are learned to be gradually disentangled when passing through each column, whose total information is maintained rather than compressed or discarded as other network does. Our experiments suggest that CNN-style RevCol models can achieve very competitive performances on multiple computer vision tasks such as image classification, object detection and semantic segmentation, especially with large parameter budget and large dataset. For example, after ImageNet-22K pre-training, RevCol-XL obtains 88.2% ImageNet-1K accuracy. Given more pre-training data, our largest model RevCol-H reaches 90.0% on ImageNet-1K, 63.8% APbox on COCO detection minival set, 61.0% mIoU on ADE20k segmentation. To our knowledge, it is the best COCO detection and ADE20k segmentation result among pure (static) CNN models. Moreover, as a general macro architecture fashion, RevCol can also be introduced into transformers or other neural networks, which is demonstrated to improve the performances in both computer vision and NLP tasks. We release code and models at https://github.com/megvii-research/RevCol
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
Apr 02, 2022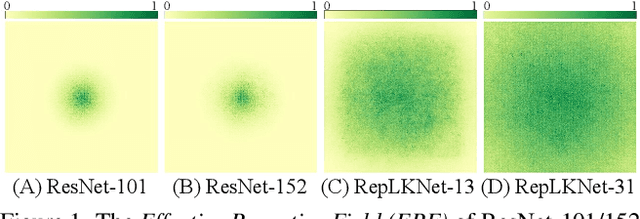
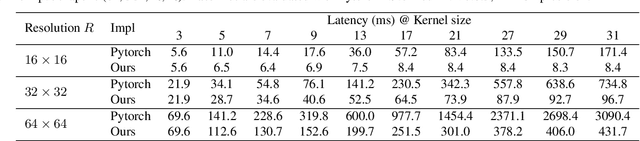


We revisit large kernel design in modern convolutional neural networks (CNNs). Inspired by recent advances in vision transformers (ViTs), in this paper, we demonstrate that using a few large convolutional kernels instead of a stack of small kernels could be a more powerful paradigm. We suggested five guidelines, e.g., applying re-parameterized large depth-wise convolutions, to design efficient high-performance large-kernel CNNs. Following the guidelines, we propose RepLKNet, a pure CNN architecture whose kernel size is as large as 31x31, in contrast to commonly used 3x3. RepLKNet greatly closes the performance gap between CNNs and ViTs, e.g., achieving comparable or superior results than Swin Transformer on ImageNet and a few typical downstream tasks, with lower latency. RepLKNet also shows nice scalability to big data and large models, obtaining 87.8% top-1 accuracy on ImageNet and 56.0% mIoU on ADE20K, which is very competitive among the state-of-the-arts with similar model sizes. Our study further reveals that, in contrast to small-kernel CNNs, large-kernel CNNs have much larger effective receptive fields and higher shape bias rather than texture bias. Code & models at https://github.com/megvii-research/RepLKNet.