 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Modeling of Joint Deep Feature and Prediction Refinement for Salient Object Detection
Sep 10, 2019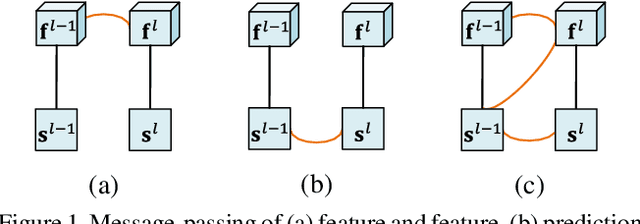
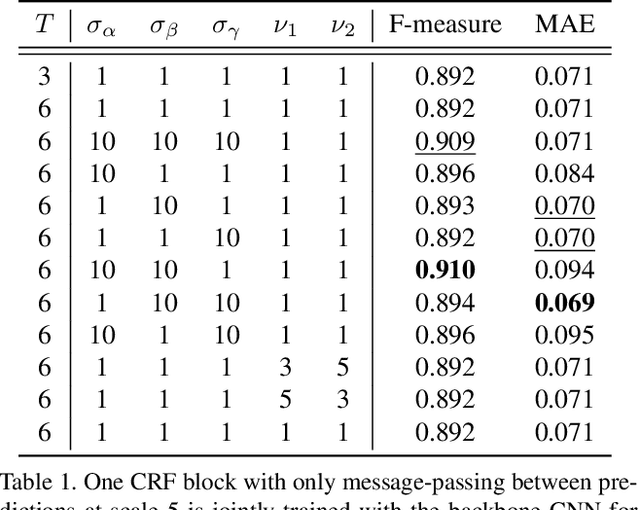
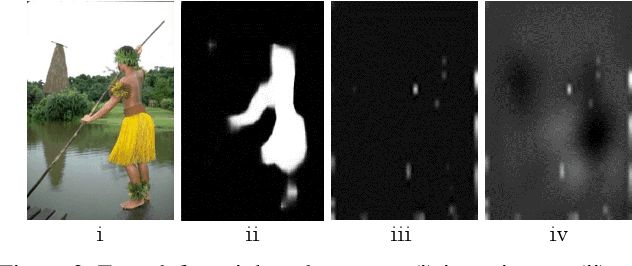
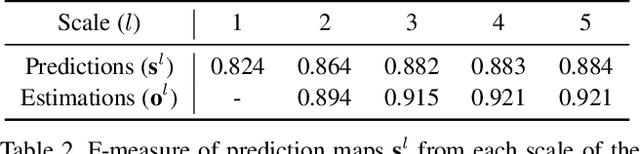
Recent saliency models extensively explore to incorporate multi-scale contextual information from Convolutional Neural Networks (CNNs). Besides direct fusion strategies, many approaches introduce message-passing to enhance CNN features or predictions. However, the messages are mainly transmitted in two ways, by feature-to-feature passing, and by prediction-to-prediction passing. In this paper, we add message-passing between features and predictions and propose a deep unified CRF saliency model . We design a novel cascade CRFs architecture with CNN to jointly refine deep features and predictions at each scale and progressively compute a final refined saliency map. We formulate the CRF graphical model that involves message-passing of feature-feature, feature-prediction, and prediction-prediction, from the coarse scale to the finer scale, to update the features and the corresponding predictions. Also, we formulate the mean-field updates for joint end-to-end model training with CNN through back propagation. The proposed deep unified CRF saliency model is evaluated over six datasets and shows highly competitive performance among the state of the arts.
A Boost in Revealing Subtle Facial Expressions: A Consolidated Eulerian Framework
Jan 23, 2019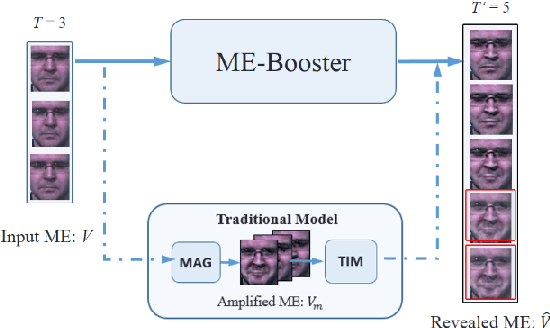
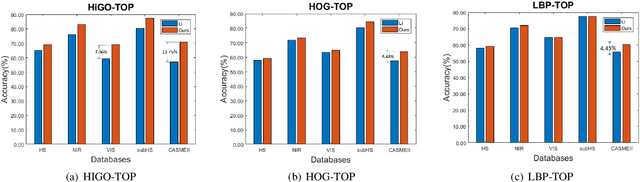
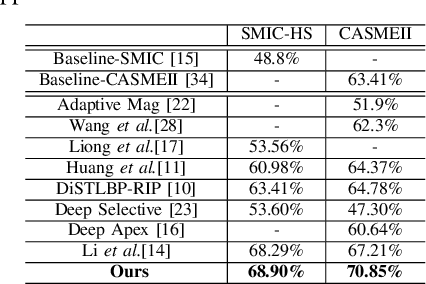
Facial Micro-expression Recognition (MER) distinguishes the underlying emotional states of spontaneous subtle facialexpressions. Automatic MER is challenging because that 1) the intensity of subtle facial muscle movement is extremely lowand 2) the duration of ME is transient.Recent works adopt motion magnification or time interpolation to resolve these issues. Nevertheless, existing works dividethem into two separate modules due to their non-linearity. Though such operation eases the difficulty in implementation, itignores their underlying connections and thus results in inevitable losses in both accuracy and speed. Instead, in this paper, weexplore their underlying joint formulations and propose a consolidated Eulerian framework to reveal the subtle facial movements.It expands the temporal duration and amplifies the muscle movements in micro-expressions simultaneously. Compared toexisting approaches, the proposed method can not only process ME clips more efficiently but also make subtle ME movementsmore distinguishable. Experiments on two public MER databases indicate that our model outperforms the state-of-the-art inboth speed and accuracy.
Saliency Integration: An Arbitrator Model
Jul 27, 2018

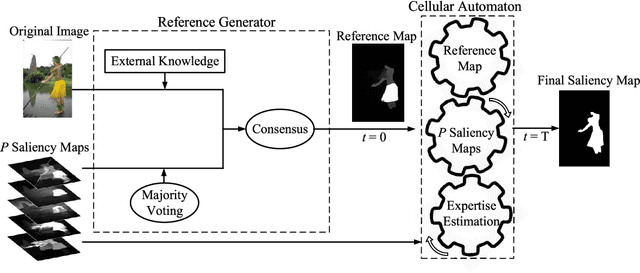
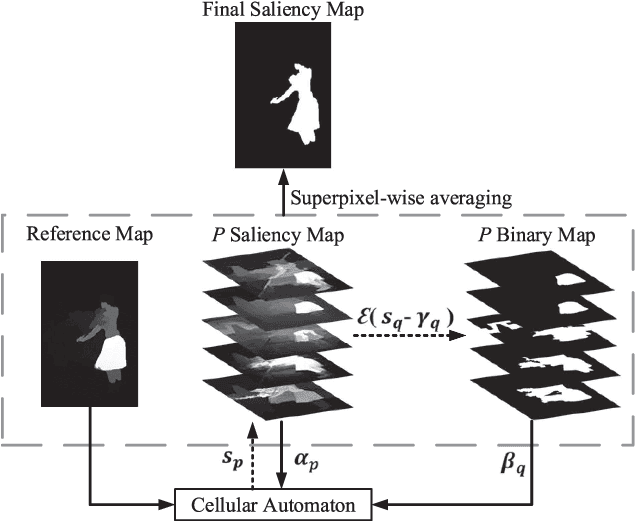
Saliency integration has attracted much attention on unifying saliency maps from multiple saliency models. Previous offline integration methods usually face two challenges: 1. if most of the candidate saliency models misjudge the saliency on an image, the integration result will lean heavily on those inferior candidate models; 2. an unawareness of the ground truth saliency labels brings difficulty in estimating the expertise of each candidate model. To address these problems, in this paper, we propose an arbitrator model (AM) for saliency integration. Firstly, we incorporate the consensus of multiple saliency models and the external knowledge into a reference map to effectively rectify the misleading by candidate models. Secondly, our quest for ways of estimating the expertise of the saliency models without ground truth labels gives rise to two distinct online model-expertise estimation methods. Finally, we derive a Bayesian integration framework to reconcile the saliency models of varying expertise and the reference map. To extensively evaluate the proposed AM model, we test twenty-seven state-of-the-art saliency models, covering both traditional and deep learning ones, on various combinations over four datasets. The evaluation results show that the AM model improves the performance substantially compared to the existing state-of-the-art integration methods, regardless of the chosen candidate saliency models.
* IEEE Transactions on Multimedia (2018)
Analyzing the group sparsity based on the rank minimization methods
Jun 12, 2017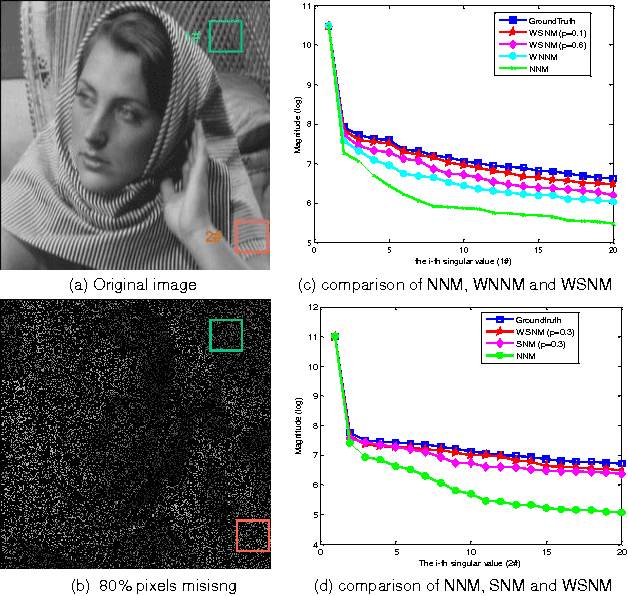
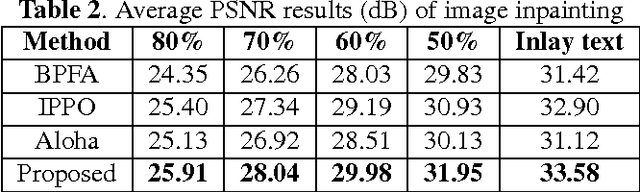

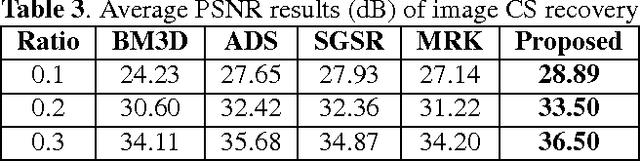
Sparse coding has achieved a great success in various image processing studies. However, there is not any benchmark to measure the sparsity of image patch/group because sparse discriminant conditions cannot keep unchanged. This paper analyzes the sparsity of group based on the strategy of the rank minimization. Firstly, an adaptive dictionary for each group is designed. Then, we prove that group-based sparse coding is equivalent to the rank minimization problem, and thus the sparse coefficient of each group is measured by estimating the singular values of each group. Based on that measurement, the weighted Schatten $p$-norm minimization (WSNM) has been found to be the closest solution to the real singular values of each group. Thus, WSNM can be equivalently transformed into a non-convex $\ell_p$-norm minimization problem in group-based sparse coding. To make the proposed scheme tractable and robust, the alternating direction method of multipliers (ADMM) is used to solve the $\ell_p$-norm minimization problem. Experimental results on two applications: image inpainting and image compressive sensing (CS) recovery have shown that the proposed scheme outperforms many state-of-the-art methods.