 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
Feb 23, 2024


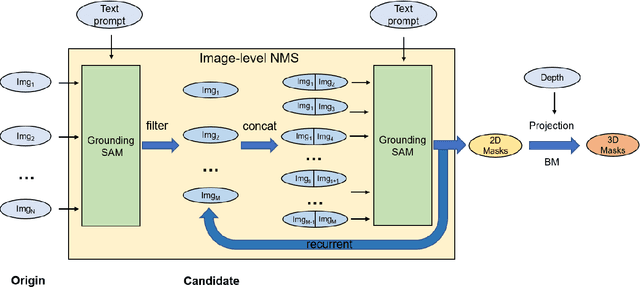
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023. The goal of this workshop series is to provide a platform for exploration and discussion of open-vocabulary 3D scene understanding tasks, including but not limited to segmentation, detection and mapping. We provide an overview of the challenge hosted at the workshop, present the challenge dataset, the evaluation methodology, and brief descriptions of the winning methods. For additional details, please see https://opensun3d.github.io/index_iccv23.html.
Visualizing the Invisible: Occluded Vehicle Segmentation and Recovery
Jul 22, 2019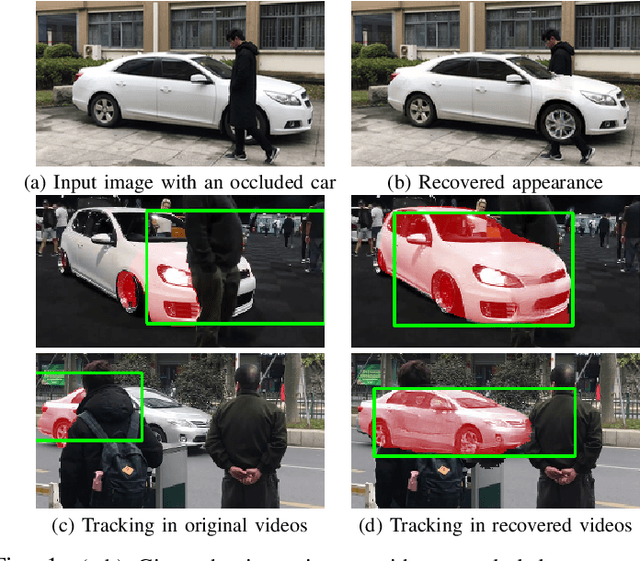
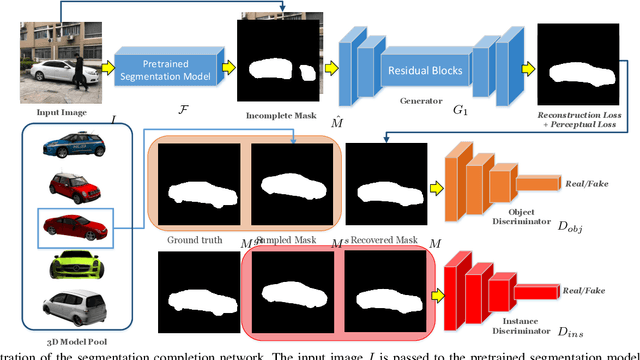
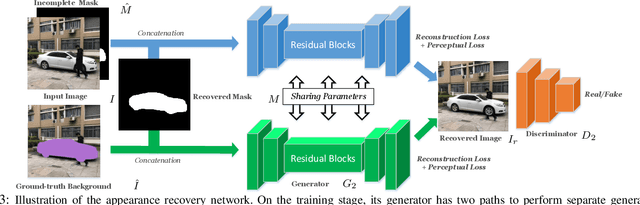

In this paper, we propose a novel iterative multi-task framework to complete the segmentation mask of an occluded vehicle and recover the appearance of its invisible parts. In particular, to improve the quality of the segmentation completion, we present two coupled discriminators and introduce an auxiliary 3D model pool for sampling authentic silhouettes as adversarial samples. In addition, we propose a two-path structure with a shared network to enhance the appearance recovery capability. By iteratively performing the segmentation completion and the appearance recovery, the results will be progressively refined. To evaluate our method, we present a dataset, the Occluded Vehicle dataset, containing synthetic and real-world occluded vehicle images. We conduct comparison experiments on this dataset and demonstrate that our model outperforms the state-of-the-art in tasks of recovering segmentation mask and appearance for occluded vehicles. Moreover, we also demonstrate that our appearance recovery approach can benefit the occluded vehicle tracking in real-world videos.