 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Matching Based Refiner for Molecular Conformer Generation
Oct 06, 2025Low-energy molecular conformers generation (MCG) is a foundational yet challenging problem in drug discovery. Denoising-based methods include diffusion and flow-matching methods that learn mappings from a simple base distribution to the molecular conformer distribution. However, these approaches often suffer from error accumulation during sampling, especially in the low SNR steps, which are hard to train. To address these challenges, we propose a flow-matching refiner for the MCG task. The proposed method initializes sampling from mixed-quality outputs produced by upstream denoising models and reschedules the noise scale to bypass the low-SNR phase, thereby improving sample quality. On the GEOM-QM9 and GEOM-Drugs benchmark datasets, the generator-refiner pipeline improves quality with fewer total denoising steps while preserving diversity.
G2T-LLM: Graph-to-Tree Text Encoding for Molecule Generation with Fine-Tuned Large Language Models
Oct 03, 2024We introduce G2T-LLM, a novel approach for molecule generation that uses graph-to-tree text encoding to transform graph-based molecular structures into a hierarchical text format optimized for large language models (LLMs). This encoding converts complex molecular graphs into tree-structured formats, such as JSON and XML, which LLMs are particularly adept at processing due to their extensive pre-training on these types of data. By leveraging the flexibility of LLMs, our approach allows for intuitive interaction using natural language prompts, providing a more accessible interface for molecular design. Through supervised fine-tuning, G2T-LLM generates valid and coherent chemical structures, addressing common challenges like invalid outputs seen in traditional graph-based methods. While LLMs are computationally intensive, they offer superior generalization and adaptability, enabling the generation of diverse molecular structures with minimal task-specific customization. The proposed approach achieved comparable performances with state-of-the-art methods on various benchmark molecular generation datasets, demonstrating its potential as a flexible and innovative tool for AI-driven molecular design.
DWRSeg: Dilation-wise Residual Network for Real-time Semantic Segmentation
Dec 02, 2022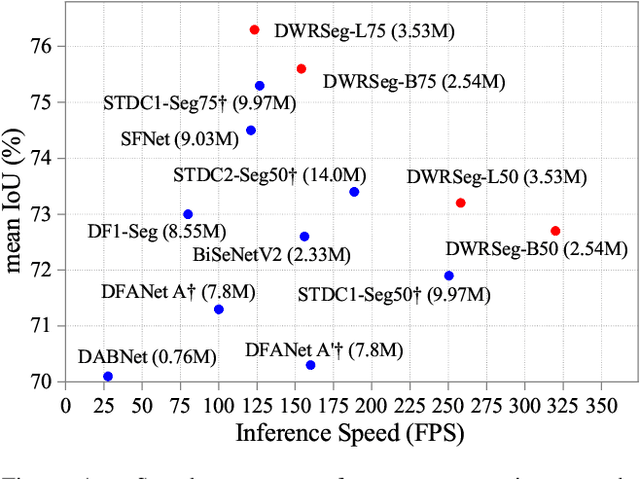
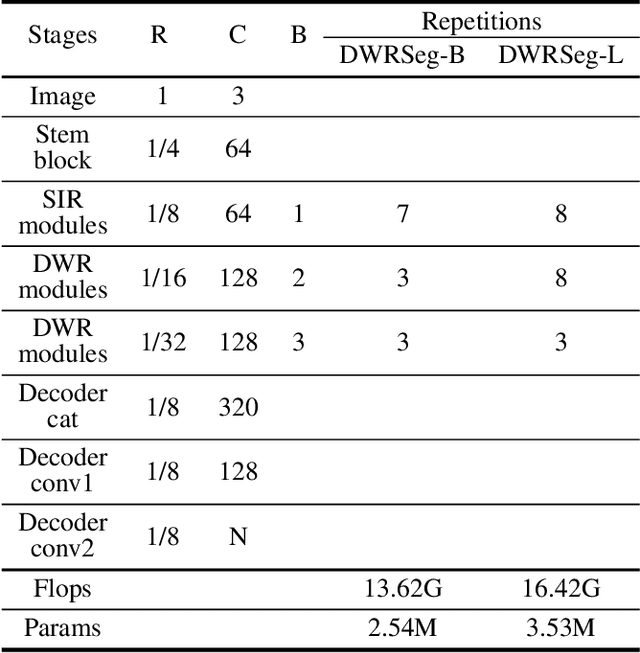
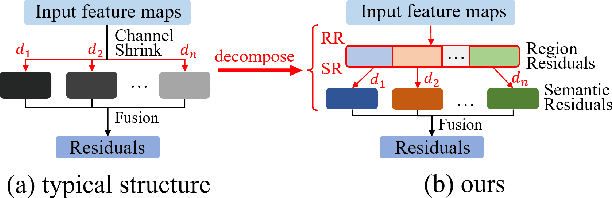
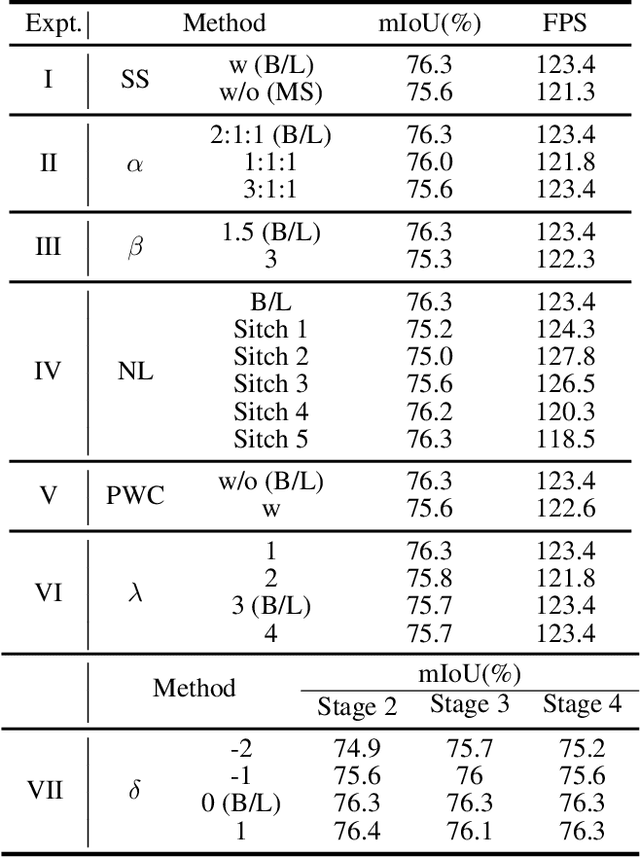
Real-time semantic segmentation has played an important role in intelligent vehicle scenarios. Recently, numerous networks have incorporated information from multi-size receptive fields to facilitate feature extraction in real-time semantic segmentation tasks. However, these methods preferentially adopt massive receptive fields to elicit more contextual information, which may result in inefficient feature extraction. We believe that the elaborated receptive fields are crucial, considering the demand for efficient feature extraction in real-time tasks. Therefore, we propose an effective and efficient architecture termed Dilation-wise Residual segmentation (DWRSeg), which possesses different sets of receptive field sizes within different stages. The architecture involves (i) a Dilation-wise Residual (DWR) module for extracting features based on different scales of receptive fields in the high level of the network; (ii) a Simple Inverted Residual (SIR) module that uses an inverted bottleneck structure to extract features from the low stage; and (iii) a simple fully convolutional network (FCN)-like decoder for aggregating multiscale feature maps to generate the prediction. Extensive experiments on the Cityscapes and CamVid datasets demonstrate the effectiveness of our method by achieving a state-of-the-art trade-off between accuracy and inference speed, in addition to being lighter weight. Without using pretraining or resorting to any training trick, we achieve 72.7% mIoU on the Cityscapes test set at a speed of 319.5 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods. The code and trained models are publicly available.
Dual-branch residual network for lung nodule segmentation
May 21, 2019
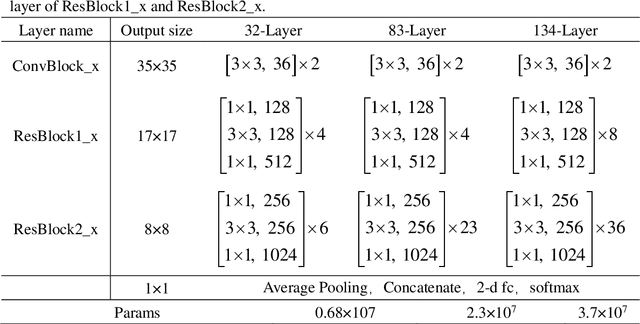
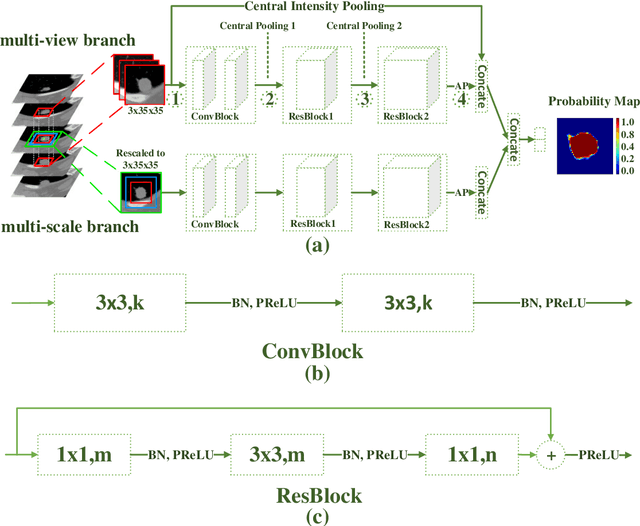
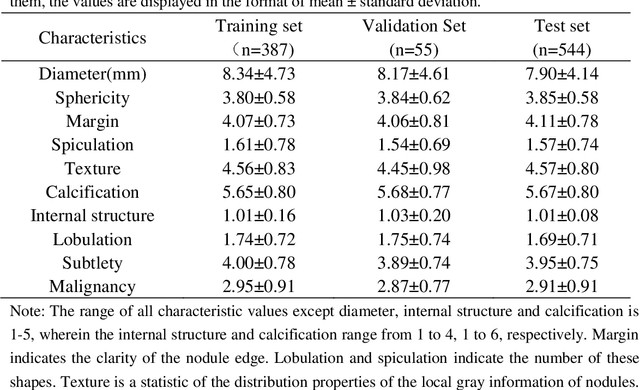
An accurate segmentation of lung nodules in computed tomography (CT) images is critical to lung cancer analysis and diagnosis. However, due to the variety of lung nodules and the similarity of visual characteristics between nodules and their surroundings, a robust segmentation of nodules becomes a challenging problem. In this study, we propose the Dual-branch Residual Network (DB-ResNet) which is a data-driven model. Our approach integrates two new schemes to improve the generalization capability of the model: 1) the proposed model can simultaneously capture multi-view and multi-scale features of different nodules in CT images; 2) we combine the features of the intensity and the convolution neural networks (CNN). We propose a pooling method, called the central intensity-pooling layer (CIP), to extract the intensity features of the center voxel of the block, and then use the CNN to obtain the convolutional features of the center voxel of the block. In addition, we designed a weighted sampling strategy based on the boundary of nodules for the selection of those voxels using the weighting score, to increase the accuracy of the model. The proposed method has been extensively evaluated on the LIDC dataset containing 986 nodules. Experimental results show that the DB-ResNet achieves superior segmentation performance with an average dice score of 82.74% on the dataset. Moreover, we compared our results with those of four radiologists on the same dataset. The comparison showed that our average dice score was 0.49% higher than that of human experts. This proves that our proposed method is as good as the experienced radiologist.
Two-Stage Convolutional Neural Network Architecture for Lung Nodule Detection
May 09, 2019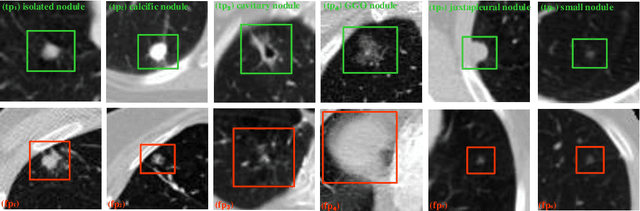
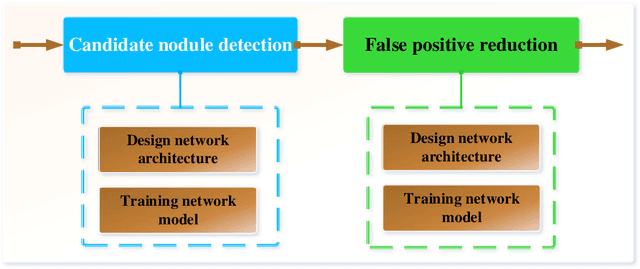

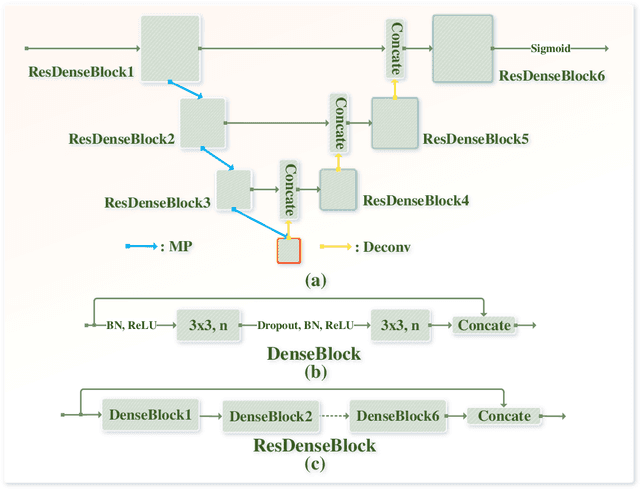
Early detection of lung cancer is an effective way to improve the survival rate of patients. It is a critical step to have accurate detection of lung nodules in computed tomography (CT) images for the diagnosis of lung cancer. However, due to the heterogeneity of the lung nodules and the complexity of the surrounding environment, robust nodule detection has been a challenging task. In this study, we propose a two-stage convolutional neural network (TSCNN) architecture for lung nodule detection. The CNN architecture in the first stage is based on the improved UNet segmentation network to establish an initial detection of lung nodules. Simultaneously, in order to obtain a high recall rate without introducing excessive false positive nodules, we propose a novel sampling strategy, and use the offline hard mining idea for training and prediction according to the proposed cascaded prediction method. The CNN architecture in the second stage is based on the proposed dual pooling structure, which is built into three 3D CNN classification networks for false positive reduction. Since the network training requires a significant amount of training data, we adopt a data augmentation method based on random mask. Furthermore, we have improved the generalization ability of the false positive reduction model by means of ensemble learning. The proposed method has been experimentally verified on the LUNA dataset. Experimental results show that the proposed TSCNN architecture can obtain competitive detection performance.
Do They All Look the Same? Deciphering Chinese, Japanese and Koreans by Fine-Grained Deep Learning
Oct 23, 2016



We study to what extend Chinese, Japanese and Korean faces can be classified and which facial attributes offer the most important cues. First, we propose a novel way of obtaining large numbers of facial images with nationality labels. Then we train state-of-the-art neural networks with these labeled images. We are able to achieve an accuracy of 75.03% in the classification task, with chances being 33.33% and human accuracy 38.89% . Further, we train multiple facial attribute classifiers to identify the most distinctive features for each group. We find that Chinese, Japanese and Koreans do exhibit substantial differences in certain attributes, such as bangs, smiling, and bushy eyebrows. Along the way, we uncover several gender-related cross-country patterns as well. Our work, which complements existing APIs such as Microsoft Cognitive Services and Face++, could find potential applications in tourism, e-commerce, social media marketing, criminal justice and even counter-terrorism.