 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWRSeg: Dilation-wise Residual Network for Real-time Semantic Segmentation
Dec 02, 2022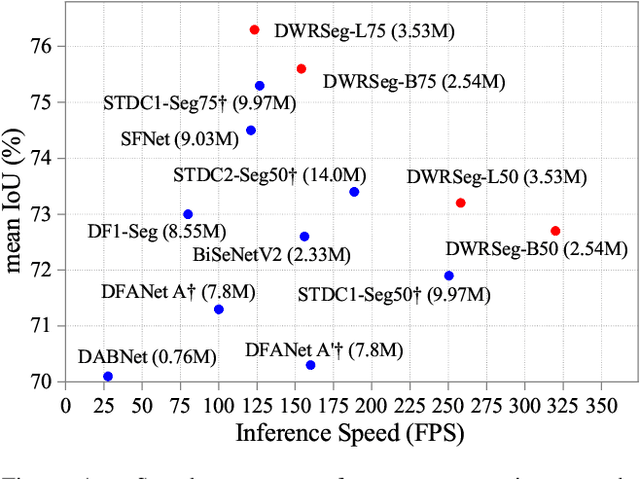
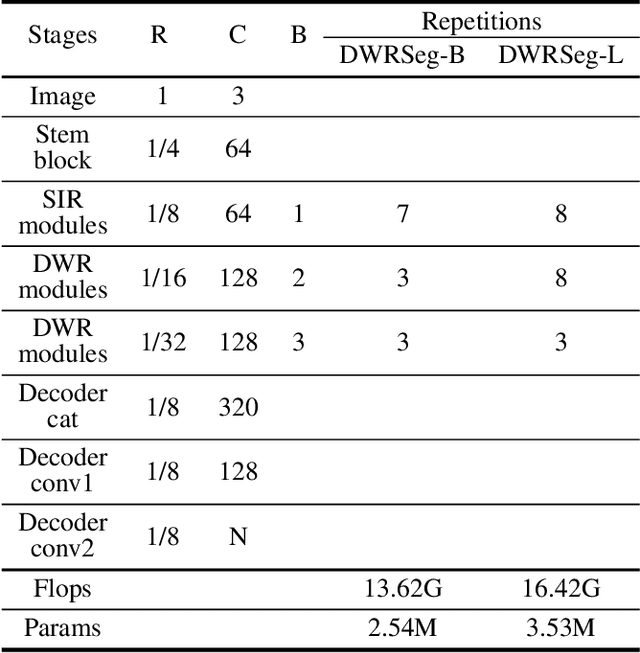
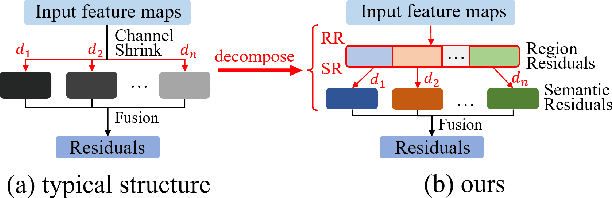
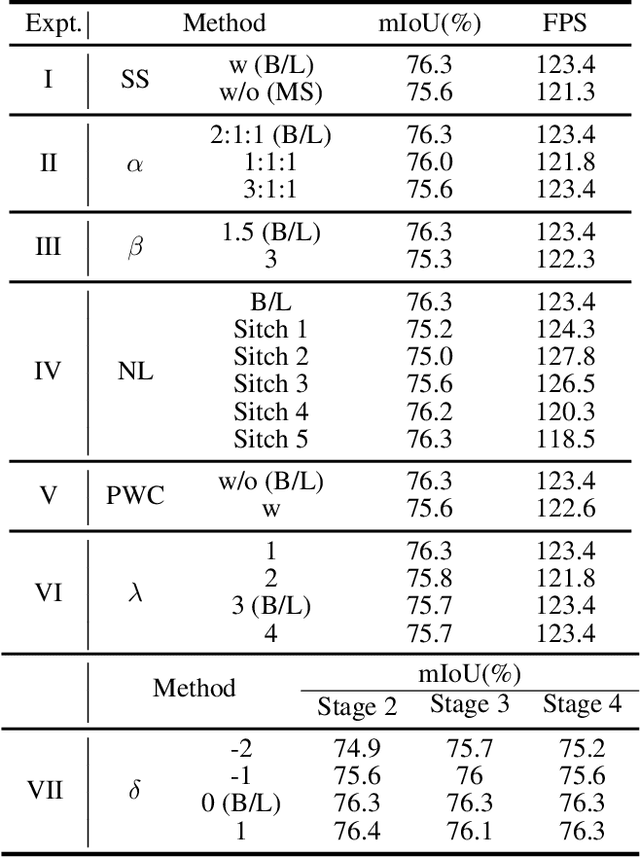
Real-time semantic segmentation has played an important role in intelligent vehicle scenarios. Recently, numerous networks have incorporated information from multi-size receptive fields to facilitate feature extraction in real-time semantic segmentation tasks. However, these methods preferentially adopt massive receptive fields to elicit more contextual information, which may result in inefficient feature extraction. We believe that the elaborated receptive fields are crucial, considering the demand for efficient feature extraction in real-time tasks. Therefore, we propose an effective and efficient architecture termed Dilation-wise Residual segmentation (DWRSeg), which possesses different sets of receptive field sizes within different stages. The architecture involves (i) a Dilation-wise Residual (DWR) module for extracting features based on different scales of receptive fields in the high level of the network; (ii) a Simple Inverted Residual (SIR) module that uses an inverted bottleneck structure to extract features from the low stage; and (iii) a simple fully convolutional network (FCN)-like decoder for aggregating multiscale feature maps to generate the prediction. Extensive experiments on the Cityscapes and CamVid datasets demonstrate the effectiveness of our method by achieving a state-of-the-art trade-off between accuracy and inference speed, in addition to being lighter weight. Without using pretraining or resorting to any training trick, we achieve 72.7% mIoU on the Cityscapes test set at a speed of 319.5 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods. The code and trained models are publicly available.