 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Boosting Learning: A Brand-new Cooperative Approach for Image-Text Matching
Apr 28, 2024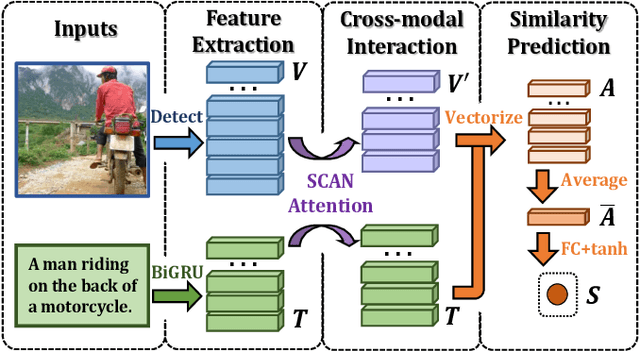
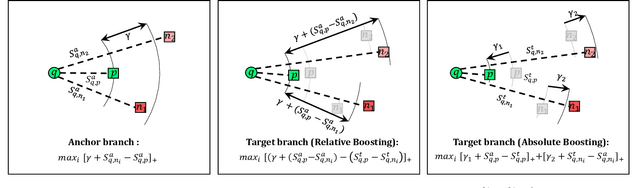
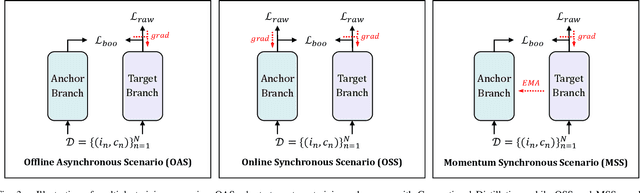
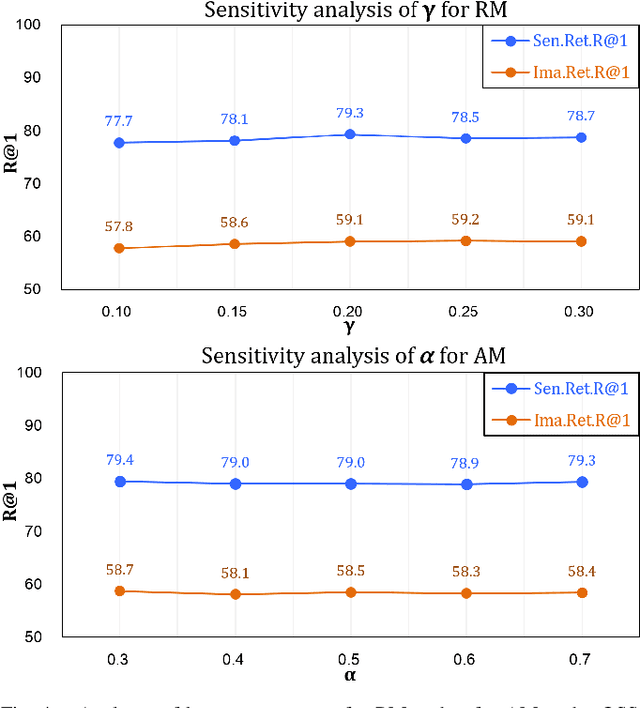
Image-text matching remains a challenging task due to heterogeneous semantic diversity across modalities and insufficient distance separability within triplets. Different from previous approaches focusing on enhancing multi-modal representations or exploiting cross-modal correspondence for more accurate retrieval, in this paper we aim to leverage the knowledge transfer between peer branches in a boosting manner to seek a more powerful matching model. Specifically, we propose a brand-new Deep Boosting Learning (DBL) algorithm, where an anchor branch is first trained to provide insights into the data properties, with a target branch gaining more advanced knowledge to develop optimal features and distance metrics. Concretely, an anchor branch initially learns the absolute or relative distance between positive and negative pairs, providing a foundational understanding of the particular network and data distribution. Building upon this knowledge, a target branch is concurrently tasked with more adaptive margin constraints to further enlarge the relative distance between matched and unmatched samples. Extensive experiments validate that our DBL can achieve impressive and consistent improvements based on various recent state-of-the-art models in the image-text matching field, and outperform related popular cooperative strategies, e.g., Conventional Distillation, Mutual Learning, and Contrastive Learning. Beyond the above, we confirm that DBL can be seamlessly integrated into their training scenarios and achieve superior performance under the same computational costs, demonstrating the flexibility and broad applicability of our proposed method. Our code is publicly available at: https://github.com/Paranioar/DBL.
Plug-and-Play Regulators for Image-Text Matching
Mar 23, 2023



Exploiting fine-grained correspondence and visual-semantic alignments has shown great potential in image-text matching. Generally, recent approaches first employ a cross-modal attention unit to capture latent region-word interactions, and then integrate all the alignments to obtain the final similarity. However, most of them adopt one-time forward association or aggregation strategies with complex architectures or additional information, while ignoring the regulation ability of network feedback. In this paper, we develop two simple but quite effective regulators which efficiently encode the message output to automatically contextualize and aggregate cross-modal representations. Specifically, we propose (i) a Recurrent Correspondence Regulator (RCR) which facilitates the cross-modal attention unit progressively with adaptive attention factors to capture more flexible correspondence, and (ii) a Recurrent Aggregation Regulator (RAR) which adjusts the aggregation weights repeatedly to increasingly emphasize important alignments and dilute unimportant ones. Besides, it is interesting that RCR and RAR are plug-and-play: both of them can be incorporated into many frameworks based on cross-modal interaction to obtain significant benefits, and their cooperation achieves further improvements. Extensive experiments on MSCOCO and Flickr30K datasets validate that they can bring an impressive and consistent R@1 gain on multiple models, confirming the general effectiveness and generalization ability of the proposed methods. Code and pre-trained models are available at: https://github.com/Paranioar/RCAR.
Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline
Apr 08, 2022
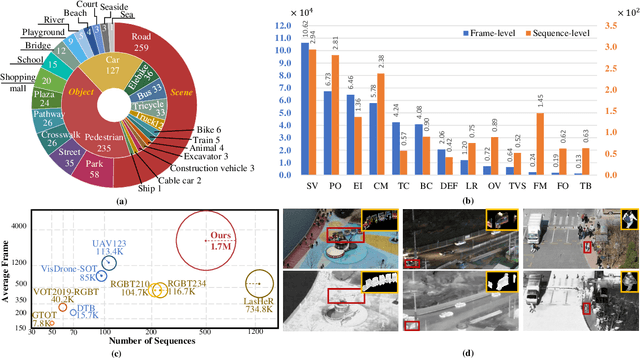
With the popularity of multi-modal sensors, visible-thermal (RGB-T) object tracking is to achieve robust performance and wider application scenarios with the guidance of objects' temperature information. However, the lack of paired training samples is the main bottleneck for unlocking the power of RGB-T tracking. Since it is laborious to collect high-quality RGB-T sequences, recent benchmarks only provide test sequences. In this paper, we construct a large-scale benchmark with high diversity for visible-thermal UAV tracking (VTUAV), including 500 sequences with 1.7 million high-resolution (1920 $\times$ 1080 pixels) frame pairs. In addition, comprehensive applications (short-term tracking, long-term tracking and segmentation mask prediction) with diverse categories and scenes are considered for exhaustive evaluation. Moreover, we provide a coarse-to-fine attribute annotation, where frame-level attributes are provided to exploit the potential of challenge-specific trackers. In addition, we design a new RGB-T baseline, named Hierarchical Multi-modal Fusion Tracker (HMFT), which fuses RGB-T data in various levels. Numerous experiments on several datasets are conducted to reveal the effectiveness of HMFT and the complement of different fusion types. The project is available at here.
Self-Supervised Representation Learning for RGB-D Salient Object Detection
Jan 29, 2021
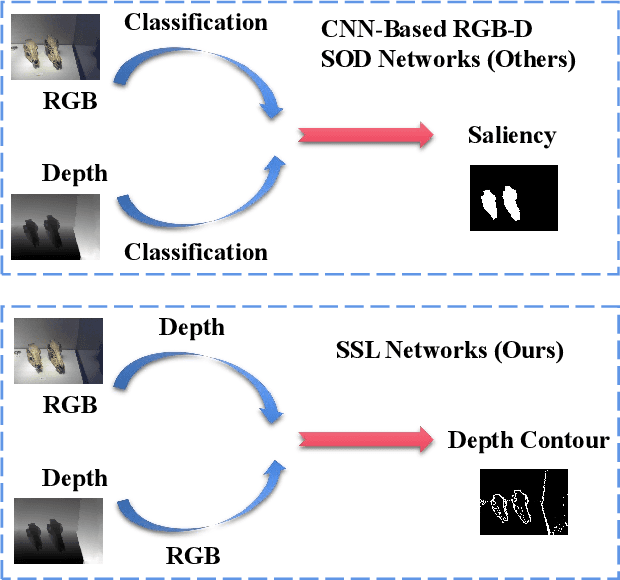
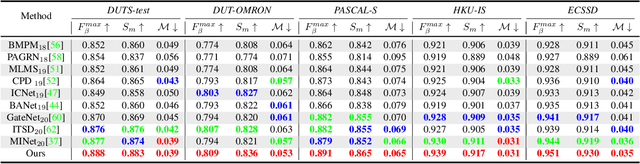
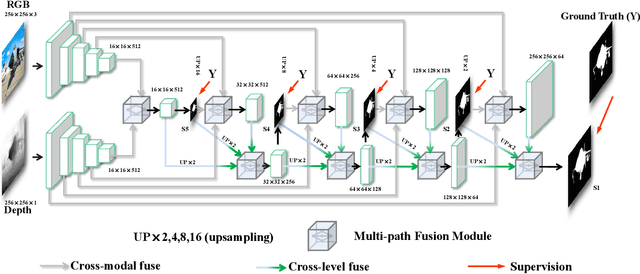
Existing CNNs-Based RGB-D Salient Object Detection (SOD) networks are all required to be pre-trained on the ImageNet to learn the hierarchy features which can help to provide a good initialization. However, the collection and annotation of large-scale datasets are time-consuming and expensive. In this paper, we utilize Self-Supervised Representation Learning (SSL) to design two pretext tasks: the cross-modal auto-encoder and the depth-contour estimation. Our pretext tasks require only a few and unlabeled RGB-D datasets to perform pre-training, which make the network capture rich semantic contexts as well as reduce the gap between two modalities, thereby providing an effective initialization for the downstream task. In addition, for the inherent problem of cross-modal fusion in RGB-D SOD, we propose a multi-path fusion (MPF) module that splits a single feature fusion into multi-path fusion to achieve an adequate perception of consistent and differential information. The MPF module is general and suitable for both cross-modal and cross-level feature fusion. Extensive experiments on six benchmark RGB-D SOD datasets, our model pre-trained on the RGB-D dataset ($6,335$ without any annotations) can perform favorably against most state-of-the-art RGB-D methods pre-trained on ImageNet ($1,280,000$ with image-level annotations).
Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection
Aug 07, 2017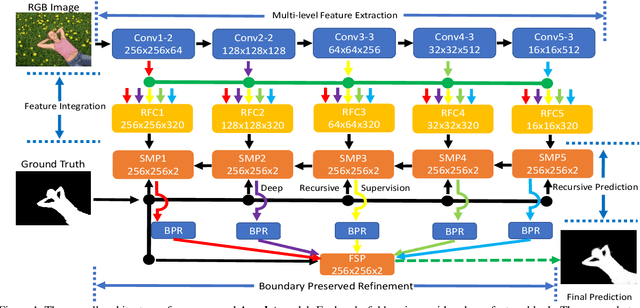
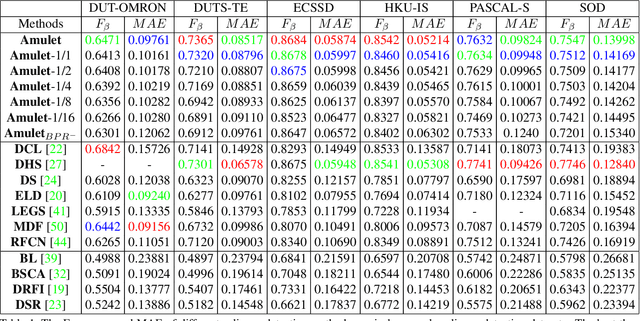
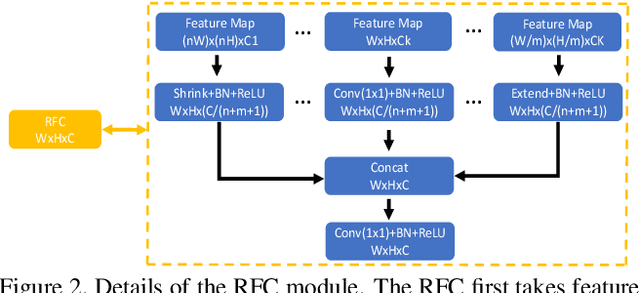
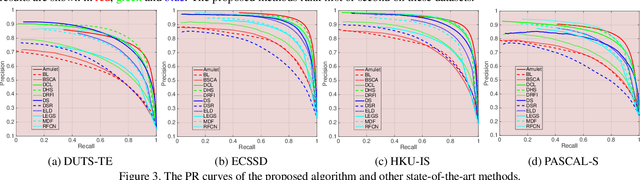
Fully convolutional neural networks (FCNs) have shown outstanding performance in many dense labeling problems. One key pillar of these successes is mining relevant information from features in convolutional layers. However, how to better aggregate multi-level convolutional feature maps for salient object detection is underexplored. In this work, we present Amulet, a generic aggregating multi-level convolutional feature framework for salient object detection. Our framework first integrates multi-level feature maps into multiple resolutions, which simultaneously incorporate coarse semantics and fine details. Then it adaptively learns to combine these feature maps at each resolution and predict saliency maps with the combined features. Finally, the predicted results are efficiently fused to generate the final saliency map. In addition, to achieve accurate boundary inference and semantic enhancement, edge-aware feature maps in low-level layers and the predicted results of low resolution features are recursively embedded into the learning framework. By aggregating multi-level convolutional features in this efficient and flexible manner, the proposed saliency model provides accurate salient object labeling. Comprehensive experiments demonstrate that our method performs favorably against state-of-the art approaches in terms of near all compared evaluation metrics.