 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning for RGB-D Salient Object Detection
Paper and Code

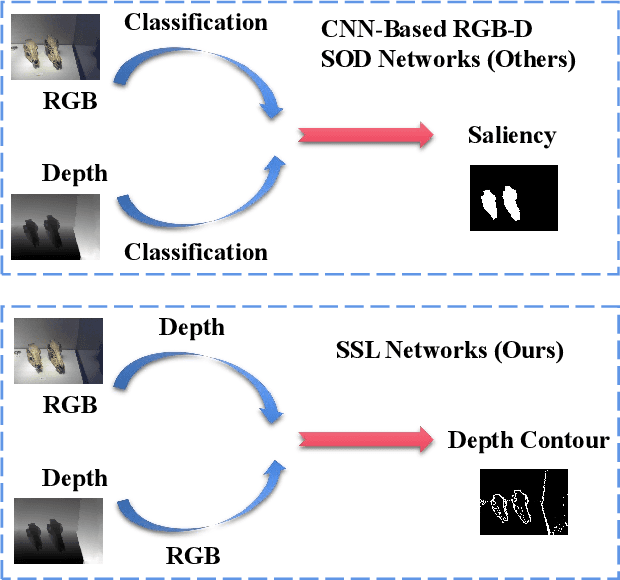
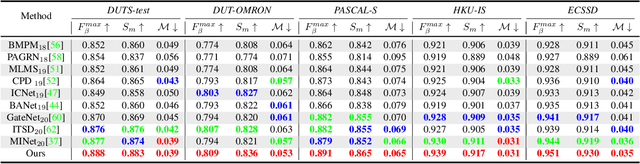
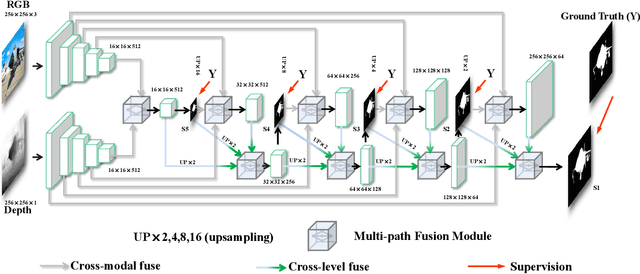
Existing CNNs-Based RGB-D Salient Object Detection (SOD) networks are all required to be pre-trained on the ImageNet to learn the hierarchy features which can help to provide a good initialization. However, the collection and annotation of large-scale datasets are time-consuming and expensive. In this paper, we utilize Self-Supervised Representation Learning (SSL) to design two pretext tasks: the cross-modal auto-encoder and the depth-contour estimation. Our pretext tasks require only a few and unlabeled RGB-D datasets to perform pre-training, which make the network capture rich semantic contexts as well as reduce the gap between two modalities, thereby providing an effective initialization for the downstream task. In addition, for the inherent problem of cross-modal fusion in RGB-D SOD, we propose a multi-path fusion (MPF) module that splits a single feature fusion into multi-path fusion to achieve an adequate perception of consistent and differential information. The MPF module is general and suitable for both cross-modal and cross-level feature fusion. Extensive experiments on six benchmark RGB-D SOD datasets, our model pre-trained on the RGB-D dataset ($6,335$ without any annotations) can perform favorably against most state-of-the-art RGB-D methods pre-trained on ImageNet ($1,280,000$ with image-level annotations).