 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Grounded Enhancement for Visual Document Retrieval
Nov 17, 2025Visual document retrieval requires understanding heterogeneous and multi-modal content to satisfy information needs. Recent advances use screenshot-based document encoding with fine-grained late interaction, significantly improving retrieval performance. However, retrievers are still trained with coarse global relevance labels, without revealing which regions support the match. As a result, retrievers tend to rely on surface-level cues and struggle to capture implicit semantic connections, hindering their ability to handle non-extractive queries. To alleviate this problem, we propose a \textbf{A}ttention-\textbf{G}rounded \textbf{RE}triever \textbf{E}nhancement (AGREE) framework. AGREE leverages cross-modal attention from multimodal large language models as proxy local supervision to guide the identification of relevant document regions. During training, AGREE combines local signals with the global signals to jointly optimize the retriever, enabling it to learn not only whether documents match, but also which content drives relevance. Experiments on the challenging ViDoRe V2 benchmark show that AGREE significantly outperforms the global-supervision-only baseline. Quantitative and qualitative analyses further demonstrate that AGREE promotes deeper alignment between query terms and document regions, moving beyond surface-level matching toward more accurate and interpretable retrieval. Our code is available at: https://anonymous.4open.science/r/AGREE-2025.
LiveThinking: Enabling Real-Time Efficient Reasoning for AI-Powered Livestreaming via Reinforcement Learning
Oct 09, 2025
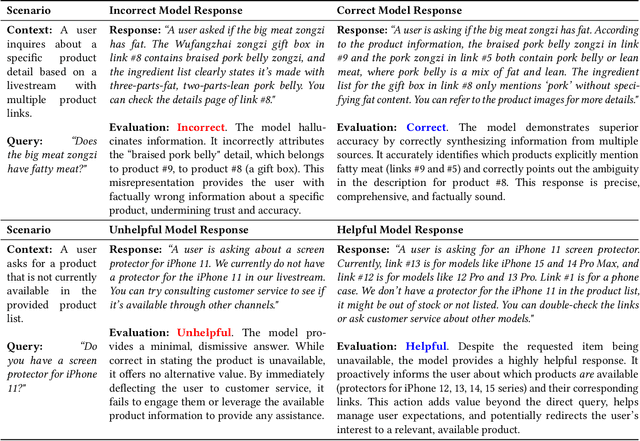
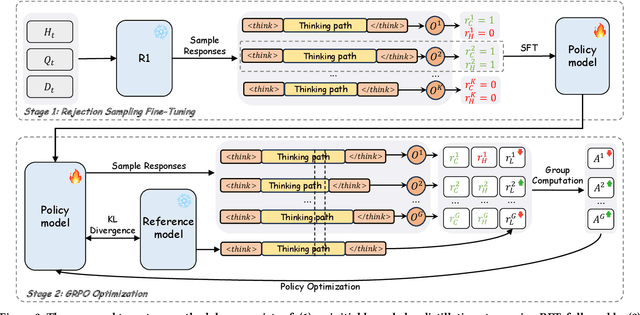
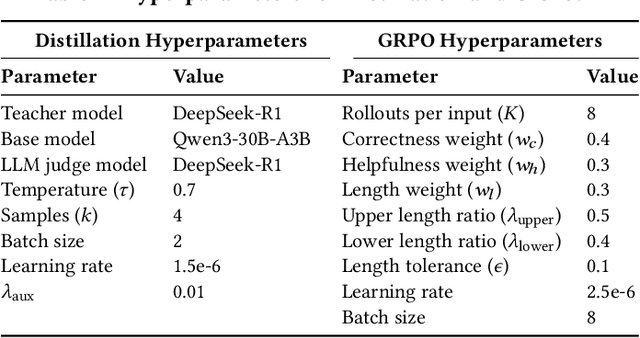
In AI-powered e-commerce livestreaming, digital avatars require real-time responses to drive engagement, a task for which high-latency Large Reasoning Models (LRMs) are ill-suited. We introduce LiveThinking, a practical two-stage optimization framework to bridge this gap. First, we address computational cost by distilling a 670B teacher LRM into a lightweight 30B Mixture-of-Experts (MoE) model (3B active) using Rejection Sampling Fine-Tuning (RFT). This reduces deployment overhead but preserves the teacher's verbose reasoning, causing latency. To solve this, our second stage employs reinforcement learning with Group Relative Policy Optimization (GRPO) to compress the model's reasoning path, guided by a multi-objective reward function balancing correctness, helpfulness, and brevity. LiveThinking achieves a 30-fold reduction in computational cost, enabling sub-second latency. In real-world application on Taobao Live, it improved response correctness by 3.3% and helpfulness by 21.8%. Tested by hundreds of thousands of viewers, our system led to a statistically significant increase in Gross Merchandise Volume (GMV), demonstrating its effectiveness in enhancing user experience and commercial performance in live, interactive settings.
Estimating Commonsense Plausibility through Semantic Shifts
Feb 19, 2025



Commonsense plausibility estimation is critical for evaluating language models (LMs), yet existing generative approaches--reliant on likelihoods or verbalized judgments--struggle with fine-grained discrimination. In this paper, we propose ComPaSS, a novel discriminative framework that quantifies commonsense plausibility by measuring semantic shifts when augmenting sentences with commonsense-related information. Plausible augmentations induce minimal shifts in semantics, while implausible ones result in substantial deviations. Evaluations on two types of fine-grained commonsense plausibility estimation tasks across different backbones, including LLMs and vision-language models (VLMs), show that ComPaSS consistently outperforms baselines. It demonstrates the advantage of discriminative approaches over generative methods in fine-grained commonsense plausibility evaluation. Experiments also show that (1) VLMs yield superior performance to LMs, when integrated with ComPaSS, on vision-grounded commonsense tasks. (2) contrastive pre-training sharpens backbone models' ability to capture semantic nuances, thereby further enhancing ComPaSS.
Image-Text Matching with Multi-View Attention
Feb 27, 2024
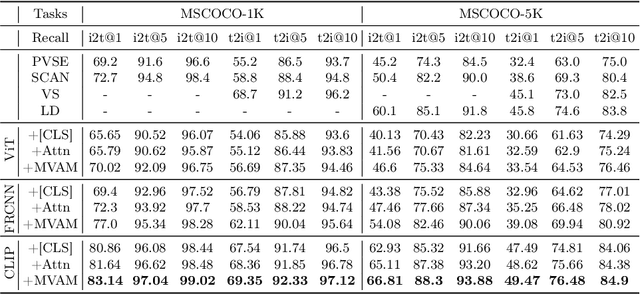
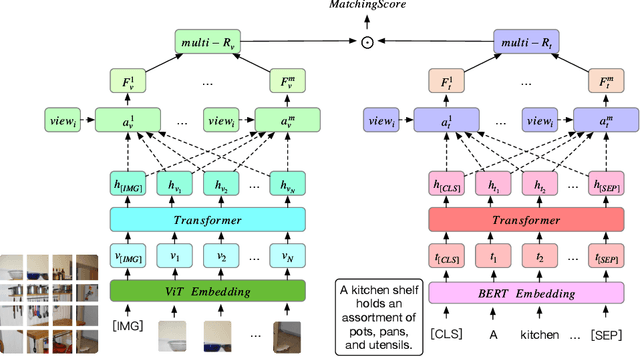
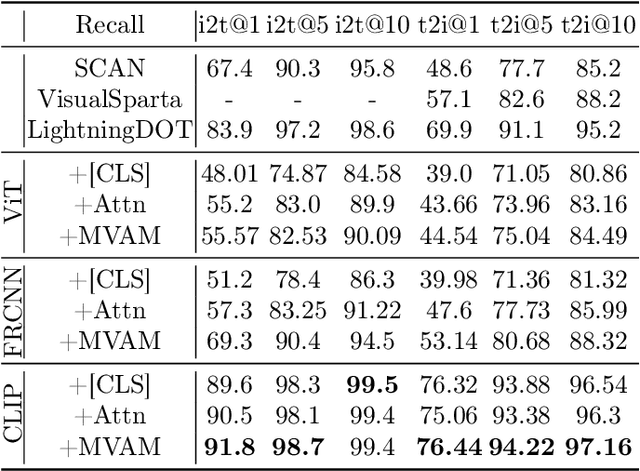
Existing two-stream models for image-text matching show good performance while ensuring retrieval speed and have received extensive attention from industry and academia. These methods use a single representation to encode image and text separately and get a matching score with cosine similarity or the inner product of vectors. However, the performance of the two-stream model is often sub-optimal. On the one hand, a single representation is challenging to cover complex content comprehensively. On the other hand, in this framework of lack of interaction, it is challenging to match multiple meanings which leads to information being ignored. To address the problems mentioned above and facilitate the performance of the two-stream model, we propose a multi-view attention approach for two-stream image-text matching MVAM (\textbf{M}ulti-\textbf{V}iew \textbf{A}ttention \textbf{M}odel). It first learns multiple image and text representations by diverse attention heads with different view codes. And then concatenate these representations into one for matching. A diversity objective is also used to promote diversity between attention heads. With this method, models are able to encode images and text from different views and attend to more key points. So we can get representations that contain more information. When doing retrieval tasks, the matching scores between images and texts can be calculated from different aspects, leading to better matching performance. Experiment results on MSCOCO and Flickr30K show that our proposed model brings improvements over existing models. Further case studies show that different attention heads can focus on different contents and finally obtain a more comprehensive representation.
MORE: Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning
Feb 21, 2024



Since commonsense information has been recorded significantly less frequently than its existence, language models pre-trained by text generation have difficulty to learn sufficient commonsense knowledge. Several studies have leveraged text retrieval to augment the models' commonsense ability. Unlike text, images capture commonsense information inherently but little effort has been paid to effectively utilize them. In this work, we propose a novel Multi-mOdal REtrieval (MORE) augmentation framework, to leverage both text and images to enhance the commonsense ability of language models. Extensive experiments on the Common-Gen task have demonstrated the efficacy of MORE based on the pre-trained models of both single and multiple modalities.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
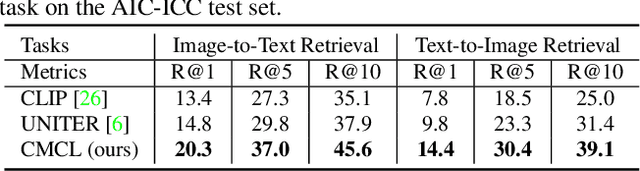
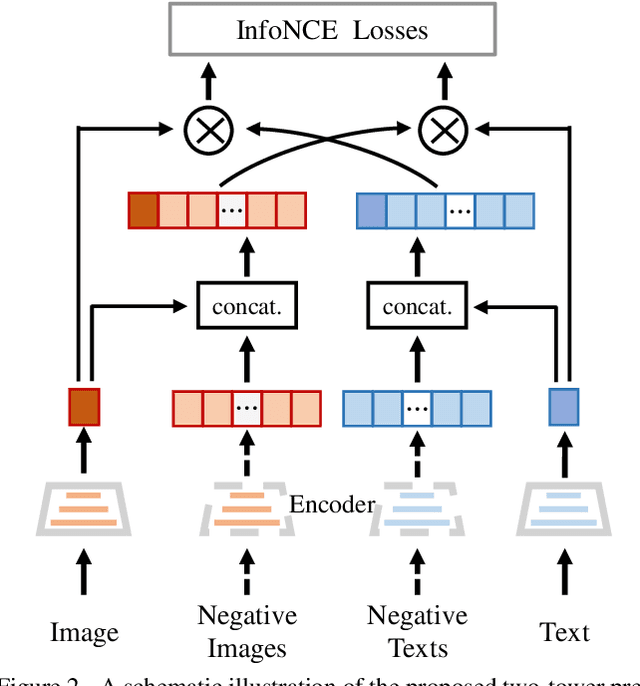
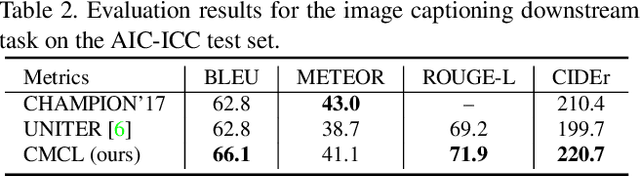
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
Beyond Language: Learning Commonsense from Images for Reasoning
Oct 10, 2020

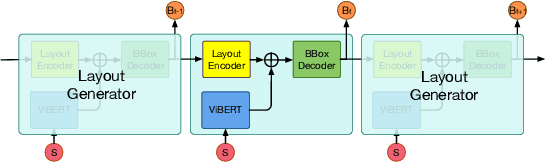
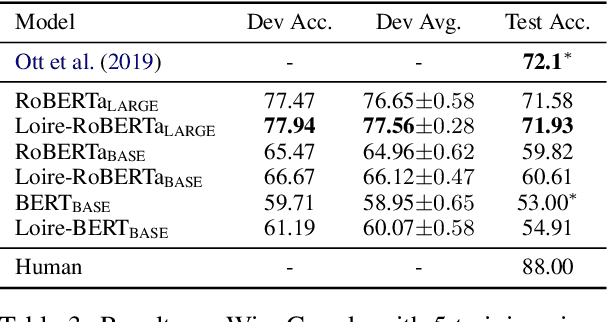
This paper proposes a novel approach to learn commonsense from images, instead of limited raw texts or costly constructed knowledge bases, for the commonsense reasoning problem in NLP. Our motivation comes from the fact that an image is worth a thousand words, where richer scene information could be leveraged to help distill the commonsense knowledge, which is often hidden in languages. Our approach, namely Loire, consists of two stages. In the first stage, a bi-modal sequence-to-sequence approach is utilized to conduct the scene layout generation task, based on a text representation model ViBERT. In this way, the required visual scene knowledge, such as spatial relations, will be encoded in ViBERT by the supervised learning process with some bi-modal data like COCO. Then ViBERT is concatenated with a pre-trained language model to perform the downstream commonsense reasoning tasks. Experimental results on two commonsense reasoning problems, i.e. commonsense question answering and pronoun resolution, demonstrate that Loire outperforms traditional language-based methods. We also give some case studies to show what knowledge is learned from images and explain how the generated scene layout helps the commonsense reasoning process.