 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Text Matching with Multi-View Attention
Paper and Code
Feb 27, 2024
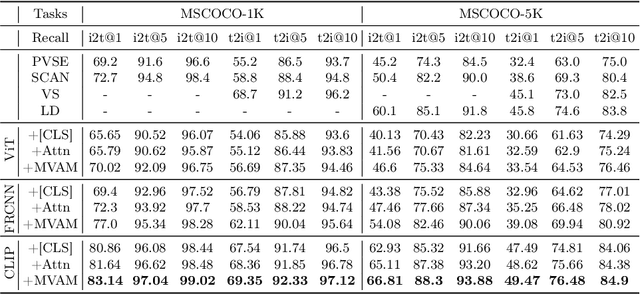
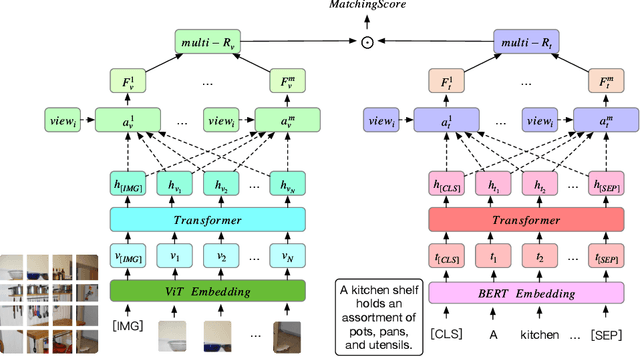
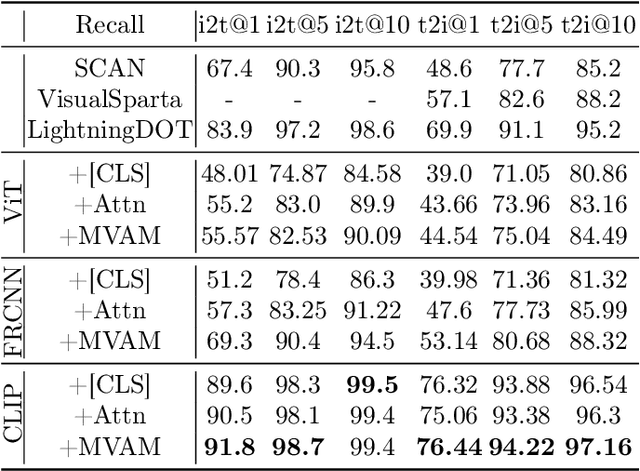
Existing two-stream models for image-text matching show good performance while ensuring retrieval speed and have received extensive attention from industry and academia. These methods use a single representation to encode image and text separately and get a matching score with cosine similarity or the inner product of vectors. However, the performance of the two-stream model is often sub-optimal. On the one hand, a single representation is challenging to cover complex content comprehensively. On the other hand, in this framework of lack of interaction, it is challenging to match multiple meanings which leads to information being ignored. To address the problems mentioned above and facilitate the performance of the two-stream model, we propose a multi-view attention approach for two-stream image-text matching MVAM (\textbf{M}ulti-\textbf{V}iew \textbf{A}ttention \textbf{M}odel). It first learns multiple image and text representations by diverse attention heads with different view codes. And then concatenate these representations into one for matching. A diversity objective is also used to promote diversity between attention heads. With this method, models are able to encode images and text from different views and attend to more key points. So we can get representations that contain more information. When doing retrieval tasks, the matching scores between images and texts can be calculated from different aspects, leading to better matching performance. Experiment results on MSCOCO and Flickr30K show that our proposed model brings improvements over existing models. Further case studies show that different attention heads can focus on different contents and finally obtain a more comprehensive representation.