 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Change the Stroke Size for Easier Diffusion?
Mar 25, 2026Diffusion models can be challenged in the low signal-to-noise regime, where they have to make pixel-level predictions despite the presence of high noise. The geometric intuition is akin to using the finest stroke for oil painting throughout, which may be ineffective. We therefore study stroke-size control as a controlled intervention that changes the effective roughness of the supervised target, predictions and perturbations across timesteps, in an attempt to ease the low signal-to-noise challenge. We analyze the advantages and trade-offs of the intervention both theoretically and empirically. Code will be released.
1S-DAug: One-Shot Data Augmentation for Robust Few-Shot Generalization
Jan 27, 2026Few-shot learning (FSL) challenges model generalization to novel classes based on just a few shots of labeled examples, a testbed where traditional test-time augmentations fail to be effective. We introduce 1S-DAug, a one-shot generative augmentation operator that synthesizes diverse yet faithful variants from just one example image at test time. 1S-DAug couples traditional geometric perturbations with controlled noise injection and a denoising diffusion process conditioned on the original image. The generated images are then encoded and aggregated, alongside the original image, into a combined representation for more robust FSL predictions. Integrated as a training-free model-agnostic plugin, 1S-DAug consistently improves FSL across standard benchmarks of 4 different datasets without any model parameter update, including achieving over 10% proportional accuracy improvement on the miniImagenet 5-way-1-shot benchmark. Codes will be released.
VORD: Visual Ordinal Calibration for Mitigating Object Hallucinations in Large Vision-Language Models
Dec 20, 2024Large Vision-Language Models (LVLMs) have made remarkable developments along with the recent surge of large language models. Despite their advancements, LVLMs have a tendency to generate plausible yet inaccurate or inconsistent information based on the provided source content. This phenomenon, also known as ``hallucinations" can have serious downstream implications during the deployment of LVLMs. To address this, we present VORD a simple and effective method that alleviates hallucinations by calibrating token predictions based on ordinal relationships between modified image pairs. VORD is presented in two forms: 1.) a minimalist training-free variant which eliminates implausible tokens from modified image pairs, and 2.) a trainable objective function that penalizes unlikely tokens. Our experiments demonstrate that VORD delivers better calibration and effectively mitigates object hallucinations on a wide-range of LVLM benchmarks.
FSL Model can Score Higher as It Is
Feb 28, 2024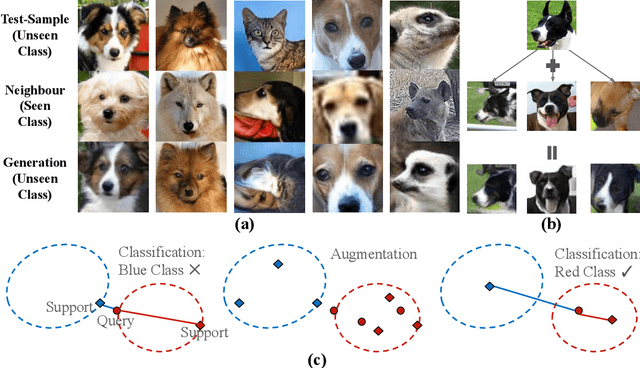
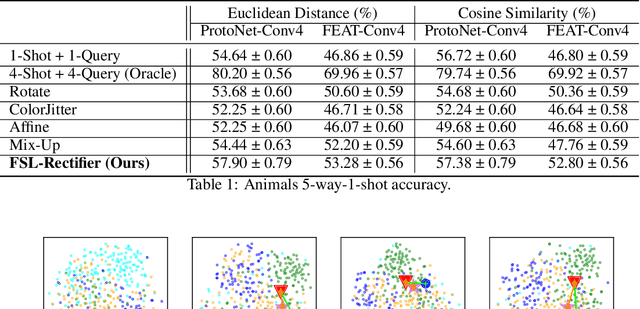
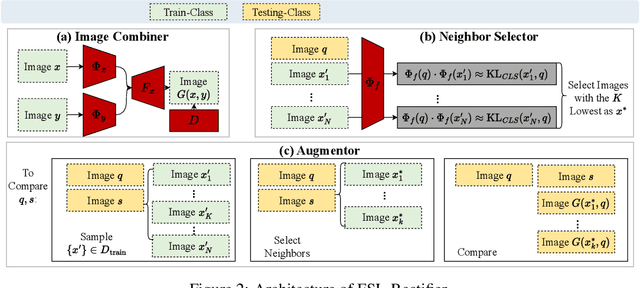
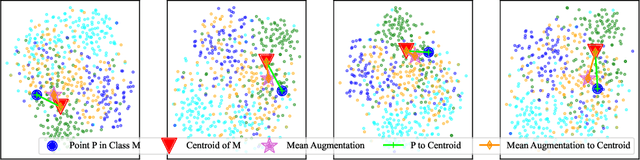
In daily life, we tend to present the front of our faces by staring squarely at a facial recognition machine, instead of facing it sideways, in order to increase the chance of being correctly recognised. Few-shot-learning (FSL) classification is challenging in itself because a model has to identify images that belong to classes previously unseen during training. Therefore, a warped and non-typical query or support image during testing can make it even more challenging for a model to predict correctly. In our work, to increase the chance of correct prediction during testing, we aim to rectify the test input of a trained FSL model by generating new samples of the tested classes through image-to-image translation. An FSL model is usually trained on classes with sufficient samples, and then tested on classes with few-shot samples. Our proposed method first captures the style or shape of the test image, and then identifies a suitable trained class sample. It then transfers the style or shape of the test image to the train-class images for generation of more test-class samples, before performing classification based on a set of generated samples instead of just one sample. Our method has potential in empowering a trained FSL model to score higher during the testing phase without any extra training nor dataset. According to our experiments, by augmenting the support set with just 1 additional generated sample, we can achieve around 2% improvement for trained FSL models on datasets consisting of either animal faces or traffic signs. By augmenting both the support set and the queries, we can achieve even more performance improvement. Our Github Repository is publicly available.
FER-C: Benchmarking Out-of-Distribution Soft Calibration for Facial Expression Recognition
Dec 16, 2023We present a soft benchmark for calibrating facial expression recognition (FER). While prior works have focused on identifying affective states, we find that FER models are uncalibrated. This is particularly true when out-of-distribution (OOD) shifts further exacerbate the ambiguity of facial expressions. While most OOD benchmarks provide hard labels, we argue that the ground-truth labels for evaluating FER models should be soft in order to better reflect the ambiguity behind facial behaviours. Our framework proposes soft labels that closely approximates the average information loss based on different types of OOD shifts. Finally, we show the benefits of calibration on five state-of-the-art FER algorithms tested on our benchmark.
MaxEnt Loss: Constrained Maximum Entropy for Calibration under Out-of-Distribution Shift
Oct 26, 2023



We present a new loss function that addresses the out-of-distribution (OOD) calibration problem. While many objective functions have been proposed to effectively calibrate models in-distribution, our findings show that they do not always fare well OOD. Based on the Principle of Maximum Entropy, we incorporate helpful statistical constraints observed during training, delivering better model calibration without sacrificing accuracy. We provide theoretical analysis and show empirically that our method works well in practice, achieving state-of-the-art calibration on both synthetic and real-world benchmarks.
DSAC-C: Constrained Maximum Entropy for Robust Discrete Soft-Actor Critic
Oct 26, 2023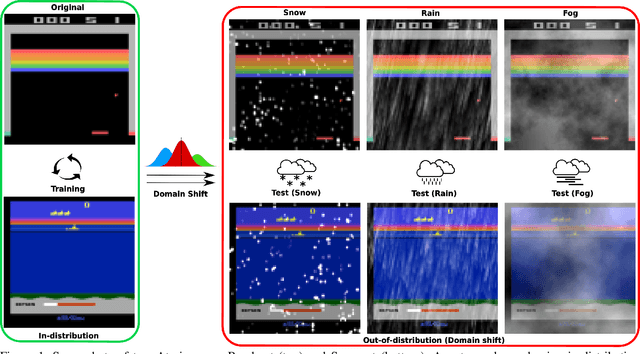
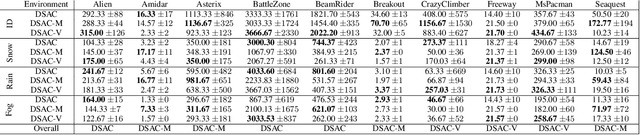
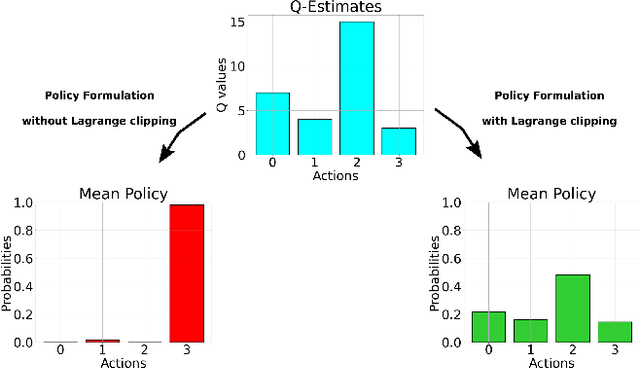

We present a novel extension to the family of Soft Actor-Critic (SAC) algorithms. We argue that based on the Maximum Entropy Principle, discrete SAC can be further improved via additional statistical constraints derived from a surrogate critic policy. Furthermore, our findings suggests that these constraints provide an added robustness against potential domain shifts, which are essential for safe deployment of reinforcement learning agents in the real-world. We provide theoretical analysis and show empirical results on low data regimes for both in-distribution and out-of-distribution variants of Atari 2600 games.
Stack-Captioning: Coarse-to-Fine Learning for Image Captioning
Mar 14, 2018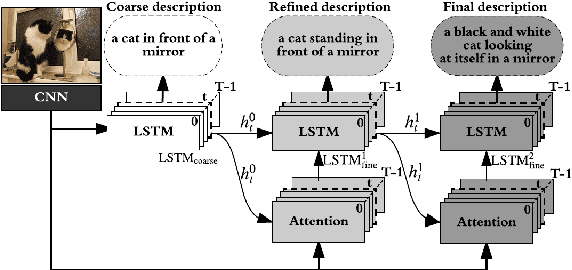
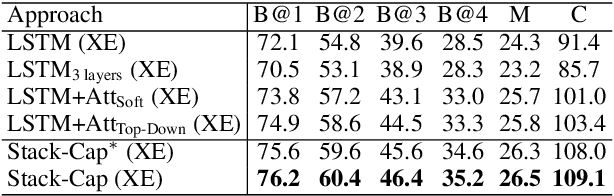
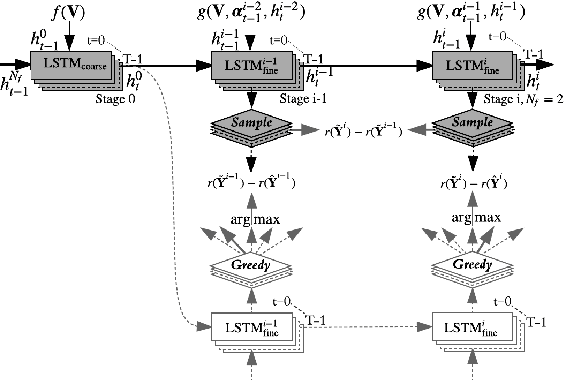
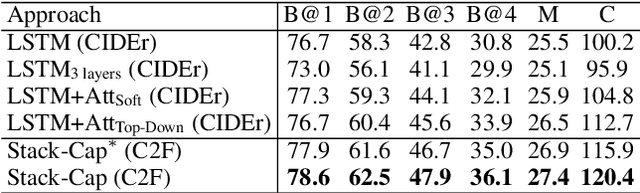
The existing image captioning approaches typically train a one-stage sentence decoder, which is difficult to generate rich fine-grained descriptions. On the other hand, multi-stage image caption model is hard to train due to the vanishing gradient problem. In this paper, we propose a coarse-to-fine multi-stage prediction framework for image captioning, composed of multiple decoders each of which operates on the output of the previous stage, producing increasingly refined image descriptions. Our proposed learning approach addresses the difficulty of vanishing gradients during training by providing a learning objective function that enforces intermediate supervisions. Particularly, we optimize our model with a reinforcement learning approach which utilizes the output of each intermediate decoder's test-time inference algorithm as well as the output of its preceding decoder to normalize the rewards, which simultaneously solves the well-known exposure bias problem and the loss-evaluation mismatch problem. We extensively evaluate the proposed approach on MSCOCO and show that our approach can achieve the state-of-the-art performance.
Recent Advances in Convolutional Neural Networks
Oct 19, 2017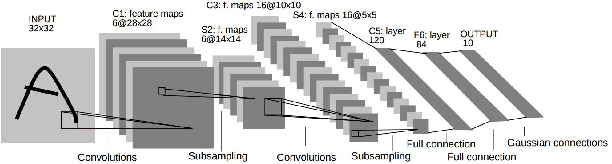
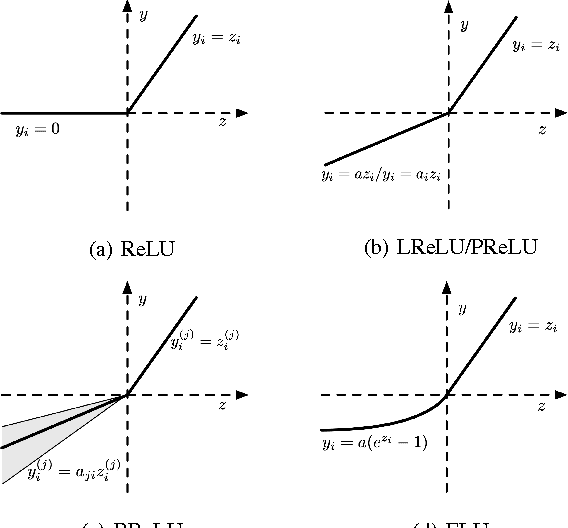
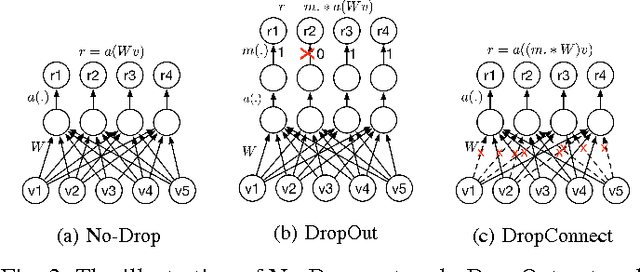
In the last few years, deep learning has led to very good performance on a variety of problems, such as visual recognition, speech recognition and natural language processing. Among different types of deep neural networks, convolutional neural networks have been most extensively studied. Leveraging on the rapid growth in the amount of the annotated data and the great improvements in the strengths of graphics processor units, the research on convolutional neural networks has been emerged swiftly and achieved state-of-the-art results on various tasks. In this paper, we provide a broad survey of the recent advances in convolutional neural networks. We detailize the improvements of CNN on different aspects, including layer design, activation function, loss function, regularization, optimization and fast computation. Besides, we also introduce various applications of convolutional neural networks in computer vision, speech and natural language processing.
An Empirical Study of Language CNN for Image Captioning
Aug 02, 2017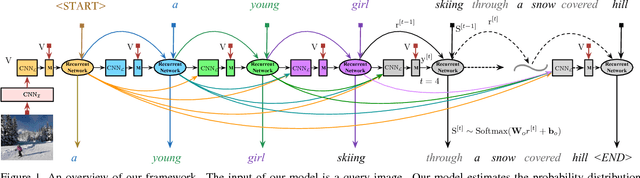
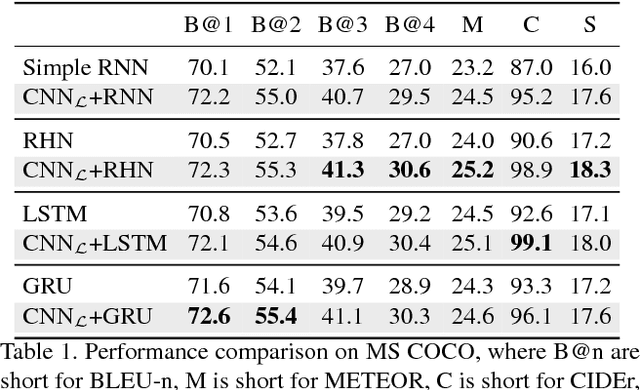
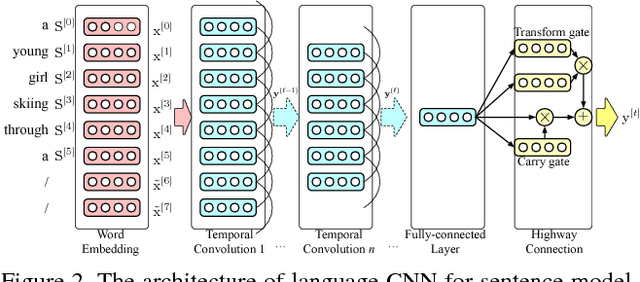
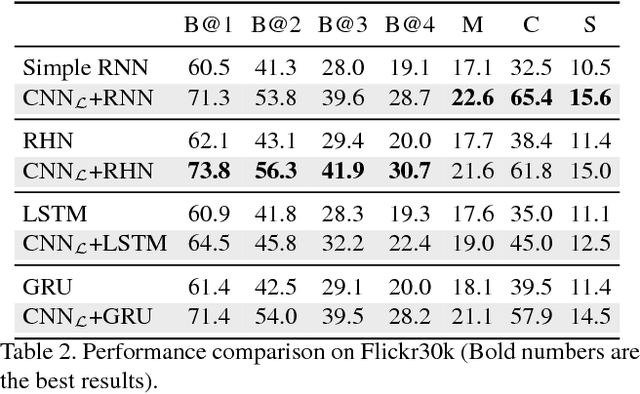
Language Models based on recurrent neural networks have dominated recent image caption generation tasks. In this paper, we introduce a Language CNN model which is suitable for statistical language modeling tasks and shows competitive performance in image captioning. In contrast to previous models which predict next word based on one previous word and hidden state, our language CNN is fed with all the previous words and can model the long-range dependencies of history words, which are critical for image captioning. The effectiveness of our approach is validated on two datasets MS COCO and Flickr30K. Our extensive experimental results show that our method outperforms the vanilla recurrent neural network based language models and is competitive with the state-of-the-art methods.