 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1S-DAug: One-Shot Data Augmentation for Robust Few-Shot Generalization
Jan 27, 2026Few-shot learning (FSL) challenges model generalization to novel classes based on just a few shots of labeled examples, a testbed where traditional test-time augmentations fail to be effective. We introduce 1S-DAug, a one-shot generative augmentation operator that synthesizes diverse yet faithful variants from just one example image at test time. 1S-DAug couples traditional geometric perturbations with controlled noise injection and a denoising diffusion process conditioned on the original image. The generated images are then encoded and aggregated, alongside the original image, into a combined representation for more robust FSL predictions. Integrated as a training-free model-agnostic plugin, 1S-DAug consistently improves FSL across standard benchmarks of 4 different datasets without any model parameter update, including achieving over 10% proportional accuracy improvement on the miniImagenet 5-way-1-shot benchmark. Codes will be released.
FSL Model can Score Higher as It Is
Feb 28, 2024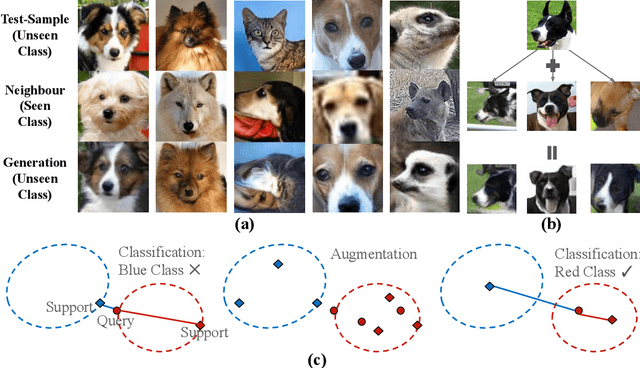
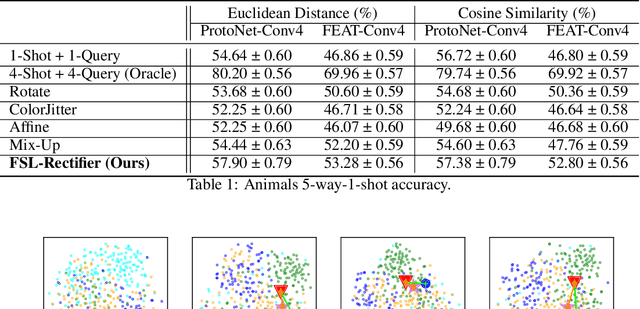
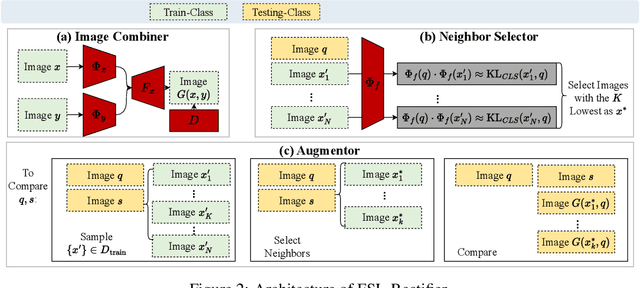
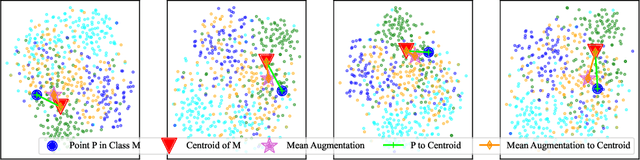
In daily life, we tend to present the front of our faces by staring squarely at a facial recognition machine, instead of facing it sideways, in order to increase the chance of being correctly recognised. Few-shot-learning (FSL) classification is challenging in itself because a model has to identify images that belong to classes previously unseen during training. Therefore, a warped and non-typical query or support image during testing can make it even more challenging for a model to predict correctly. In our work, to increase the chance of correct prediction during testing, we aim to rectify the test input of a trained FSL model by generating new samples of the tested classes through image-to-image translation. An FSL model is usually trained on classes with sufficient samples, and then tested on classes with few-shot samples. Our proposed method first captures the style or shape of the test image, and then identifies a suitable trained class sample. It then transfers the style or shape of the test image to the train-class images for generation of more test-class samples, before performing classification based on a set of generated samples instead of just one sample. Our method has potential in empowering a trained FSL model to score higher during the testing phase without any extra training nor dataset. According to our experiments, by augmenting the support set with just 1 additional generated sample, we can achieve around 2% improvement for trained FSL models on datasets consisting of either animal faces or traffic signs. By augmenting both the support set and the queries, we can achieve even more performance improvement. Our Github Repository is publicly available.