 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Detection Explorer: An Interactive Tool for Event Detection Exploration
Apr 26, 2022
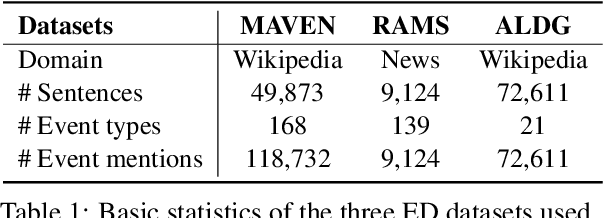
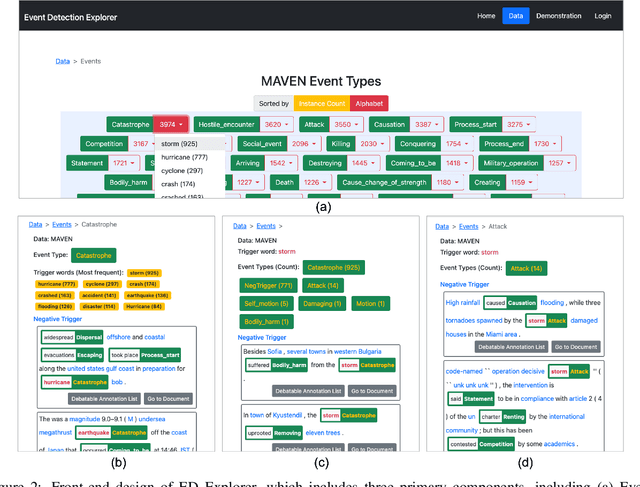

Event Detection (ED) is an important task in natural language processing. In the past few years, many datasets have been introduced for advancing ED machine learning models. However, most of these datasets are under-explored because not many tools are available for people to study events, trigger words, and event mention instances systematically and efficiently. In this paper, we present an interactive and easy-to-use tool, namely ED Explorer, for ED dataset and model exploration. ED Explorer consists of an interactive web application, an API, and an NLP toolkit, which can help both domain experts and non-experts to better understand the ED task. We use ED Explorer to analyze a recent proposed large-scale ED datasets (referred to as MAVEN), and discover several underlying problems, including sparsity, label bias, label imbalance, and debatable annotations, which provide us with directions to improve the MAVEN dataset. The ED Explorer can be publicly accessed through http://edx.leafnlp.org/. The demonstration video is available here https://www.youtube.com/watch?v=6QPnxPwxg50.
Attention-based Aspect Reasoning for Knowledge Base Question Answering on Clinical Notes
Aug 01, 2021

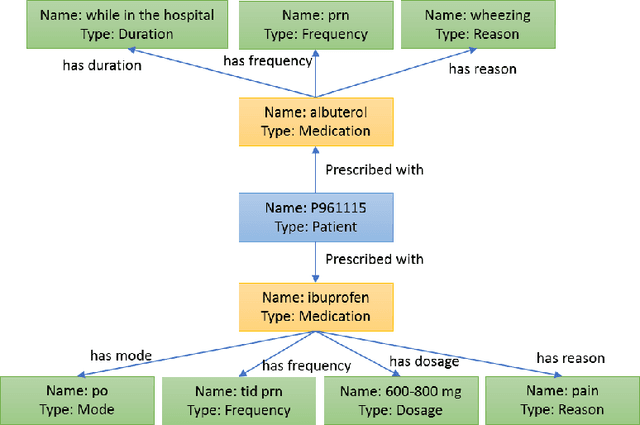
Question Answering (QA) in clinical notes has gained a lot of attention in the past few years. Existing machine reading comprehension approaches in clinical domain can only handle questions about a single block of clinical texts and fail to retrieve information about different patients and clinical notes. To handle more complex questions, we aim at creating knowledge base from clinical notes to link different patients and clinical notes, and performing knowledge base question answering (KBQA). Based on the expert annotations in n2c2, we first created the ClinicalKBQA dataset that includes 8,952 QA pairs and covers questions about seven medical topics through 322 question templates. Then, we proposed an attention-based aspect reasoning (AAR) method for KBQA and investigated the impact of different aspects of answers (e.g., entity, type, path, and context) for prediction. The AAR method achieves better performance due to the well-designed encoder and attention mechanism. In the experiments, we find that both aspects, type and path, enable the model to identify answers satisfying the general conditions and produce lower precision and higher recall. On the other hand, the aspects, entity and context, limit the answers by node-specific information and lead to higher precision and lower recall.
Deliberate Self-Attention Network with Uncertainty Estimation for Multi-Aspect Review Rating Prediction
Sep 18, 2020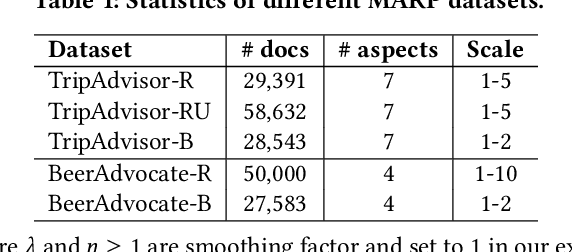
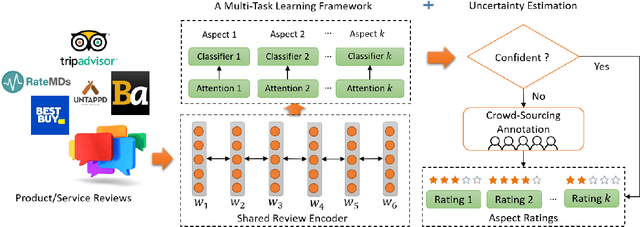
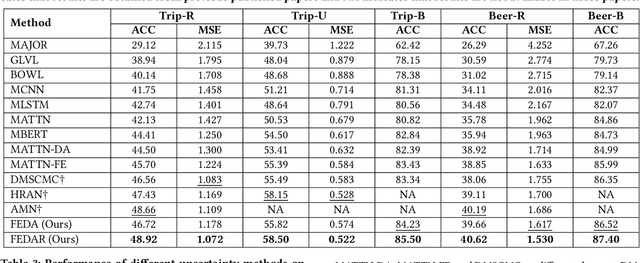
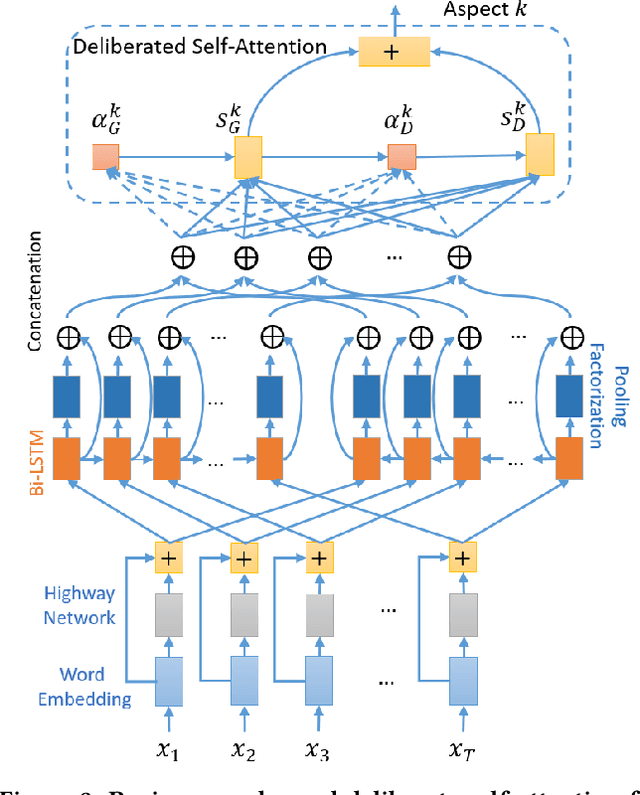
In recent years, several online platforms have seen a rapid increase in the number of review systems that request users to provide aspect-level feedback. Multi-Aspect Rating Prediction (MARP), where the goal is to predict the ratings from a review at an individual aspect level, has become a challenging and an imminent problem. To tackle this challenge, we propose a deliberate self-attention deep neural network model, named as FEDAR, for the MARP problem, which can achieve competitive performance while also being able to interpret the predictions made. As opposed to the previous studies, which make use of hand-crafted keywords to determine aspects in sentiment predictions, our model does not suffer from human bias issues since aspect keywords are automatically detected through a self-attention mechanism. FEDAR is equipped with a highway word embedding layer to transfer knowledge from pre-trained word embeddings, an RNN encoder layer with output features enriched by pooling and factorization techniques, and a deliberate self-attention layer. In addition, we also propose an Attention-driven Keywords Ranking (AKR) method, which can automatically extract aspect-level sentiment-related keywords from the review corpus based on the attention weights. Since crowdsourcing annotation can be an alternate way to recover missing ratings of reviews, we propose a LEcture-AuDience (LEAD) strategy to estimate model uncertainty in the context of multi-task learning, so that valuable human resources can focus on the most uncertain predictions. Our extensive set of experiments on different DMSC datasets demonstrate the superiority of the proposed FEDAR and LEAD models. Visualization of aspect-level sentiment keywords demonstrate the interpretability of our model and effectiveness of our AKR method.
A Simple and Effective Self-Supervised Contrastive Learning Framework for Aspect Detection
Sep 18, 2020

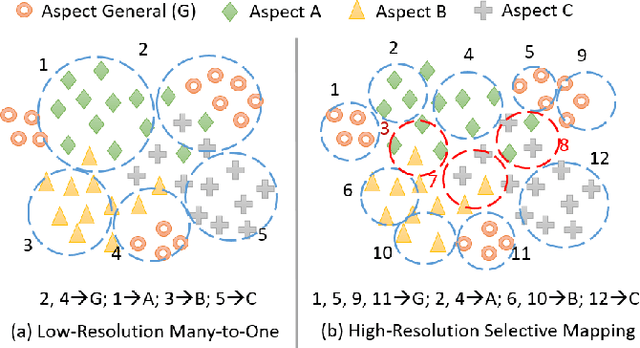
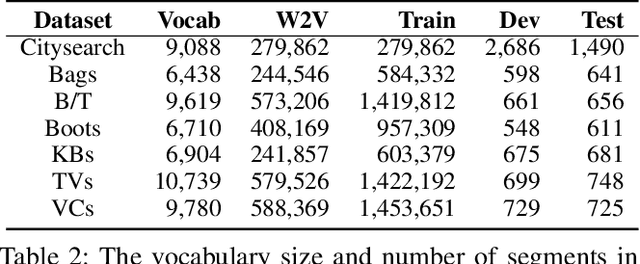
Unsupervised aspect detection (UAD) aims at automatically extracting interpretable aspects and identifying aspect-specific segments (such as sentences) from online reviews. However, recent deep learning-based topic models, specifically aspect-based autoencoder, suffer from several problems, such as extracting noisy aspects and poorly mapping aspects discovered by models to the aspects of interest. To tackle these challenges, in this paper, we first propose a self-supervised contrastive learning framework and an attention-based model equipped with a novel smooth self-attention (SSA) module for the UAD task in order to learn better representations for aspects and review segments. Secondly, we introduce a high-resolution selective mapping (HRSMap) method to efficiently assign aspects discovered by the model to aspects of interest. We also propose using a knowledge distilling technique to further improve the aspect detection performance. Our methods outperform several recent unsupervised and weakly supervised approaches on publicly available benchmark user review datasets. Aspect interpretation results show that extracted aspects are meaningful, have good coverage, and can be easily mapped to aspects of interest. Ablation studies and attention weight visualization also demonstrate the effectiveness of SSA and the knowledge distilling method.
A Concept-based Abstraction-Aggregation Deep Neural Network for Interpretable Document Classification
Apr 24, 2020



Using attention weights to identify information that is important for models' decision making is a popular approach to interpret attention-based neural networks, which is commonly realized via creating a heat-map for every single document based on attention weights. However, this interpretation method is fragile. In this paper, we propose a corpus-level explanation approach, which aims to capture causal relationships between keywords and model predictions via learning importance of keywords for predicted labels across a training corpus based on attention weights. Using this idea as the fundamental building block, we further propose a concept-based explanation method that can automatically learn higher-level concepts and their importance to model prediction task. Our concept-based explanation method is built upon a novel Abstraction-Aggregation Network, which can automatically cluster important keywords during an end-to-end training process. We apply these methods to the document classification task and show that they are powerful in extracting semantically meaningful keywords and concepts. Our consistency analysis results based on an attention-based Na\"ive Bayes Classifier also demonstrate these keywords and concepts are important for model predictions.
A Translate-Edit Model for Natural Language Question to SQL Query Generation on Multi-relational Healthcare Data
Jul 28, 2019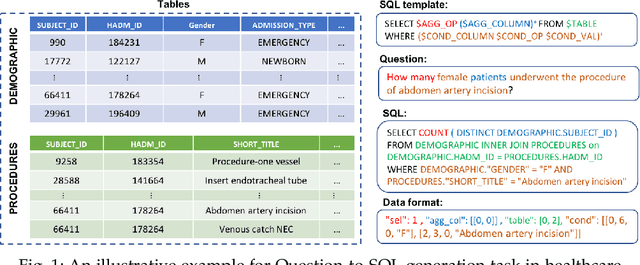
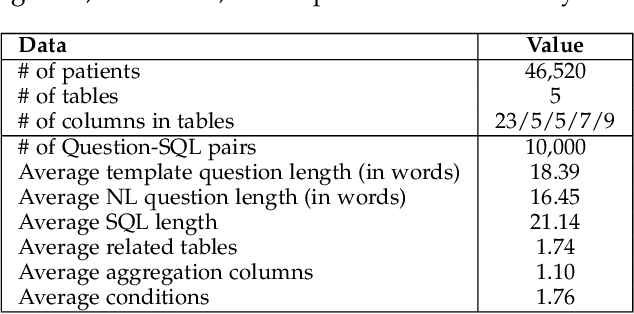
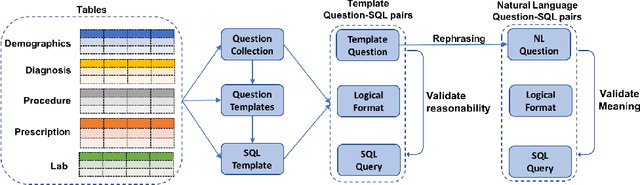
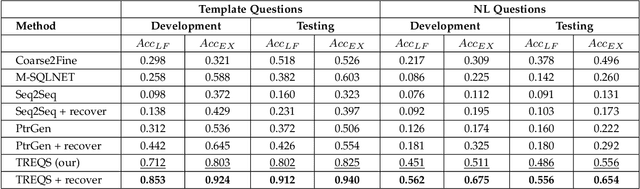
Electronic health record (EHR) data contains most of the important patient health information and is typically stored in a relational database with multiple tables. One important way for doctors to make use of EHR data is to retrieve intuitive information by posing a sequence of questions against it. However, due to a large amount of information stored in it, effectively retrieving patient information from EHR data in a short time is still a challenging issue for medical experts since it requires a good understanding of a query language to get access to the database. We tackle this challenge by developing a deep learning based approach that can translate a natural language question on multi-relational EHR data into its corresponding SQL query, which is referred to as a Question-to-SQL generation task. Most of the existing methods cannot solve this problem since they primarily focus on tackling the questions related to a single table under the table-aware assumption. While in our problem, it is possible that questions asked by clinicians are related to multiple unspecified tables. In this paper, we first create a new question to query dataset designed for healthcare to perform the Question-to-SQL generation task, named MIMICSQL, based on a publicly available electronic medical database. To address the challenge of generating queries on multi-relational databases from natural language questions, we propose a TRanslate-Edit Model for Question-to-SQL query (TREQS), which adopts the sequence-to-sequence model to directly generate SQL query for a given question, and further edits it with an attentive-copying mechanism and task-specific look-up tables. Both quantitative and qualitative experimental results indicate the flexibility and efficiency of our proposed method in tackling challenges that are unique in MIMICSQL.
LeafNATS: An Open-Source Toolkit and Live Demo System for Neural Abstractive Text Summarization
May 28, 2019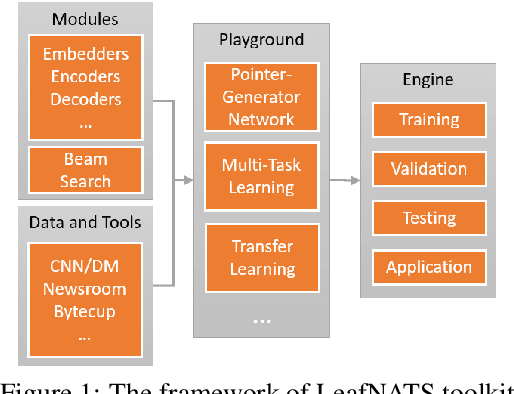
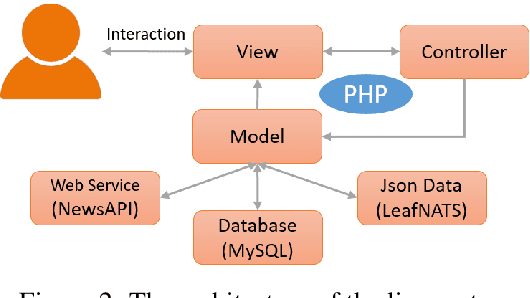
Neural abstractive text summarization (NATS) has received a lot of attention in the past few years from both industry and academia. In this paper, we introduce an open-source toolkit, namely LeafNATS, for training and evaluation of different sequence-to-sequence based models for the NATS task, and for deploying the pre-trained models to real-world applications. The toolkit is modularized and extensible in addition to maintaining competitive performance in the NATS task. A live news blogging system has also been implemented to demonstrate how these models can aid blog/news editors by providing them suggestions of headlines and summaries of their articles.
Neural Abstractive Text Summarization with Sequence-to-Sequence Models
Dec 07, 2018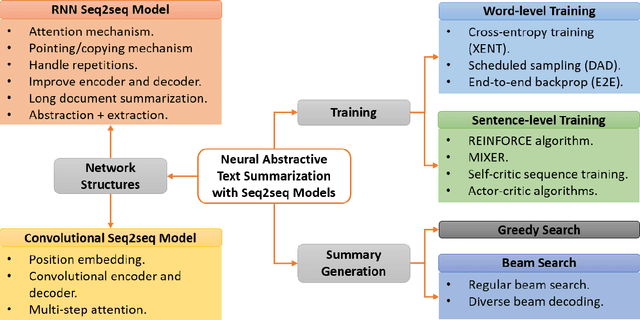
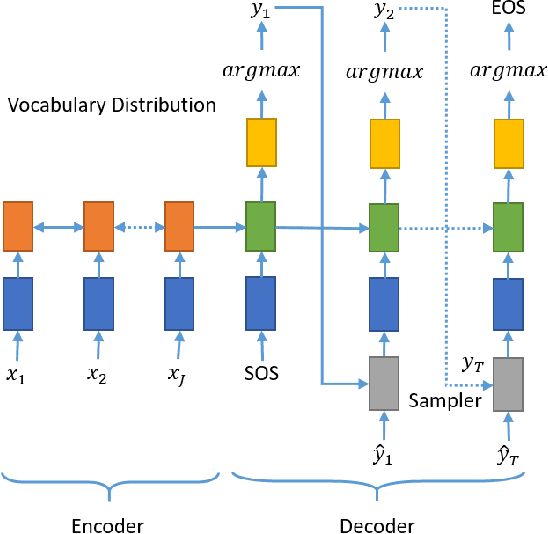
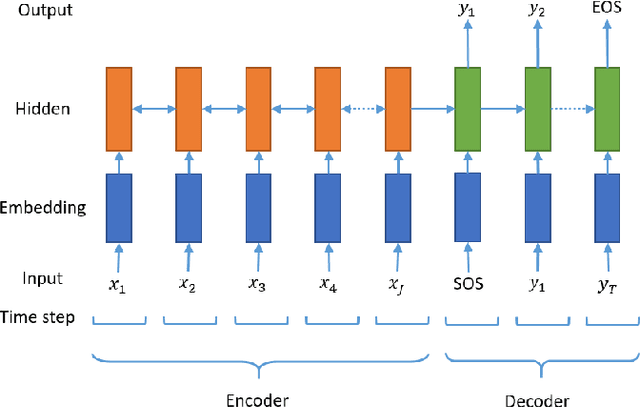
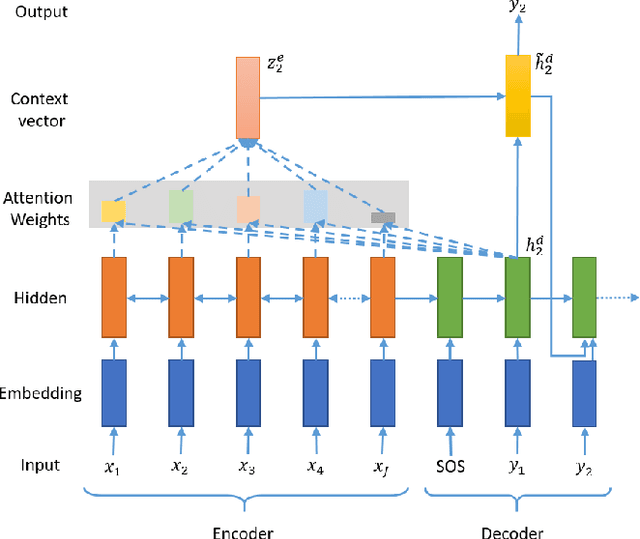
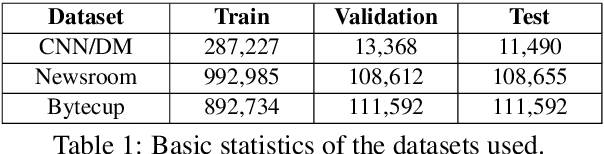
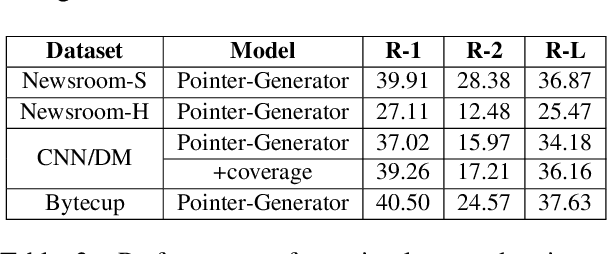
In the past few years, neural abstractive text summarization with sequence-to-sequence (seq2seq) models have gained a lot of popularity. Many interesting techniques have been proposed to improve the seq2seq models, making them capable of handling different challenges, such as saliency, fluency and human readability, and generate high-quality summaries. Generally speaking, most of these techniques differ in one of these three categories: network structure, parameter inference, and decoding/generation. There are also other concerns, such as efficiency and parallelism for training a model. In this paper, we provide a comprehensive literature and technical survey on different seq2seq models for abstractive text summarization from viewpoint of network structures, training strategies, and summary generation algorithms. Many models were first proposed for language modeling and generation tasks, such as machine translation, and later applied to abstractive text summarization. Therefore, we also provide a brief review of these models. As part of this survey, we also develop an open source library, namely Neural Abstractive Text Summarizer (NATS) toolkit, for the abstractive text summarization. An extensive set of experiments have been conducted on the widely used CNN/Daily Mail dataset to examine the effectiveness of several different neural network components. Finally, we benchmark two models implemented in NATS on two recently released datasets, i.e., Newsroom and Bytecup.
Deep Reinforcement Learning For Sequence to Sequence Models
Jul 20, 2018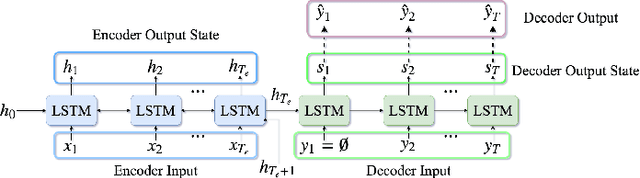

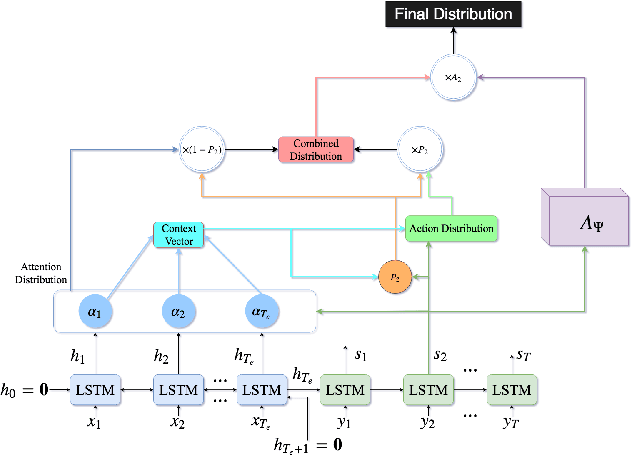
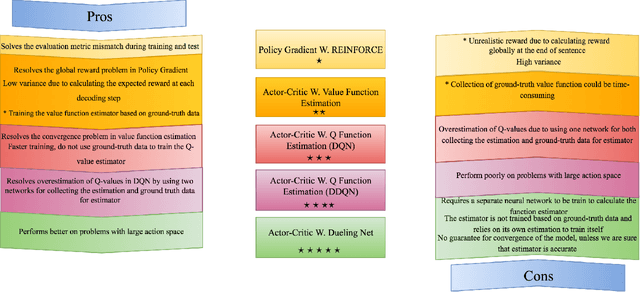
In recent times, sequence-to-sequence (seq2seq) models have gained a lot of popularity and provide state-of-the-art performance in a wide variety of tasks such as machine translation, headline generation, text summarization, speech to text conversion, and image caption generation. The underlying framework for all these models is usually a deep neural network comprising an encoder and a decoder. Although simple encoder-decoder models produce competitive results, many researchers have proposed additional improvements over these sequence-to-sequence models, e.g., using an attention-based model over the input, pointer-generation models, and self-attention models. However, such seq2seq models suffer from two common problems: 1) exposure bias and 2) inconsistency between train/test measurement. Recently, a completely novel point of view has emerged in addressing these two problems in seq2seq models, leveraging methods from reinforcement learning (RL). In this survey, we consider seq2seq problems from the RL point of view and provide a formulation combining the power of RL methods in decision-making with sequence-to-sequence models that enable remembering long-term memories. We present some of the most recent frameworks that combine concepts from RL and deep neural networks and explain how these two areas could benefit from each other in solving complex seq2seq tasks. Our work aims to provide insights into some of the problems that inherently arise with current approaches and how we can address them with better RL models. We also provide the source code for implementing most of the RL models discussed in this paper to support the complex task of abstractive text summarization.