 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing Advancements By Deep Learning: A Survey
Mar 04, 2020


Natural Language Processing (NLP) helps empower intelligent machines by enhancing a better understanding of the human language for linguistic-based human-computer communication. Recent developments in computational power and the advent of large amounts of linguistic data have heightened the need and demand for automating semantic analysis using data-driven approaches. The utilization of data-driven strategies is pervasive now due to the significant improvements demonstrated through the usage of deep learning methods in areas such as Computer Vision, Automatic Speech Recognition, and in particular, NLP. This survey categorizes and addresses the different aspects and applications of NLP that have benefited from deep learning. It covers core NLP tasks and applications and describes how deep learning methods and models advance these areas. We further analyze and compare different approaches and state-of-the-art models.
Neural Abstractive Text Summarization with Sequence-to-Sequence Models
Dec 07, 2018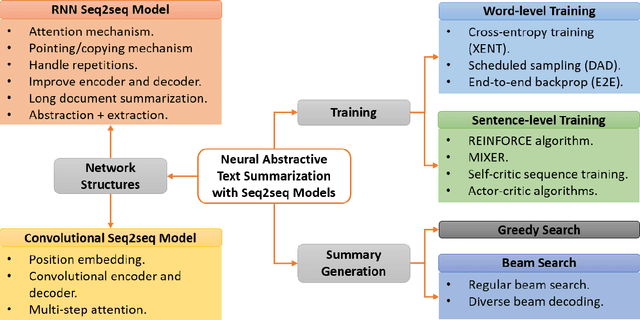
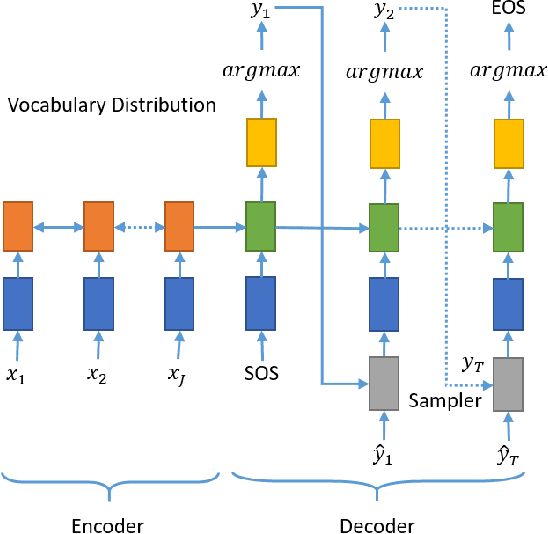
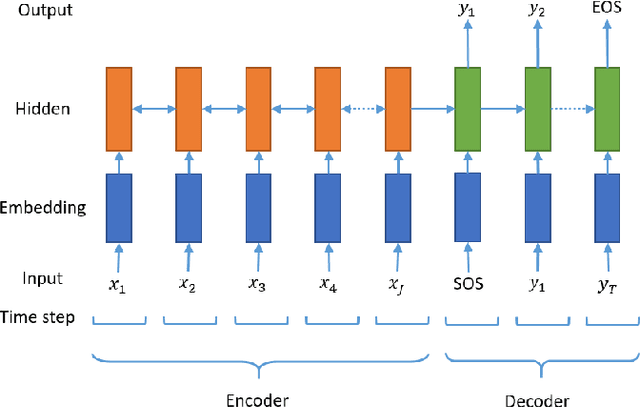
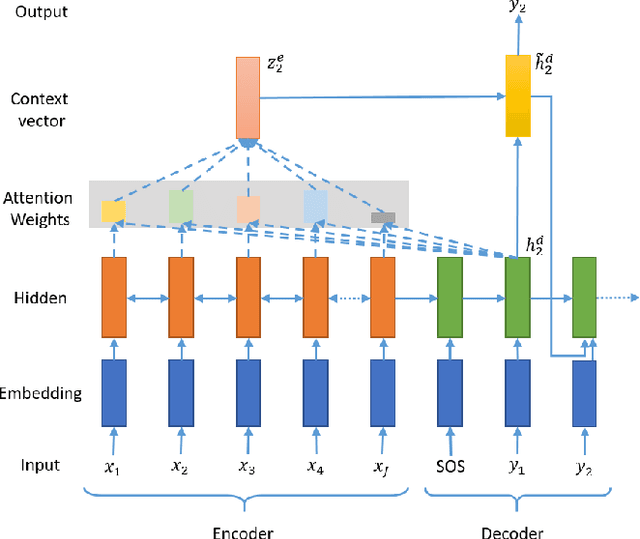
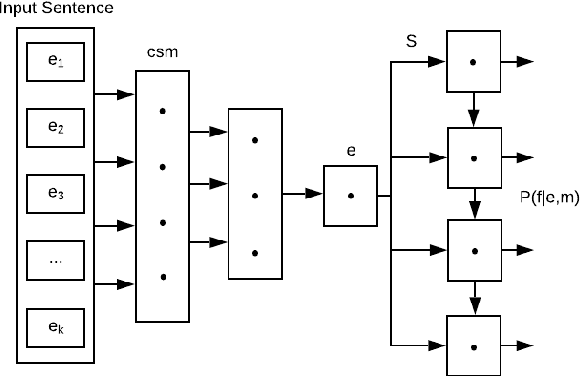
In the past few years, neural abstractive text summarization with sequence-to-sequence (seq2seq) models have gained a lot of popularity. Many interesting techniques have been proposed to improve the seq2seq models, making them capable of handling different challenges, such as saliency, fluency and human readability, and generate high-quality summaries. Generally speaking, most of these techniques differ in one of these three categories: network structure, parameter inference, and decoding/generation. There are also other concerns, such as efficiency and parallelism for training a model. In this paper, we provide a comprehensive literature and technical survey on different seq2seq models for abstractive text summarization from viewpoint of network structures, training strategies, and summary generation algorithms. Many models were first proposed for language modeling and generation tasks, such as machine translation, and later applied to abstractive text summarization. Therefore, we also provide a brief review of these models. As part of this survey, we also develop an open source library, namely Neural Abstractive Text Summarizer (NATS) toolkit, for the abstractive text summarization. An extensive set of experiments have been conducted on the widely used CNN/Daily Mail dataset to examine the effectiveness of several different neural network components. Finally, we benchmark two models implemented in NATS on two recently released datasets, i.e., Newsroom and Bytecup.
Deep Transfer Reinforcement Learning for Text Summarization
Oct 15, 2018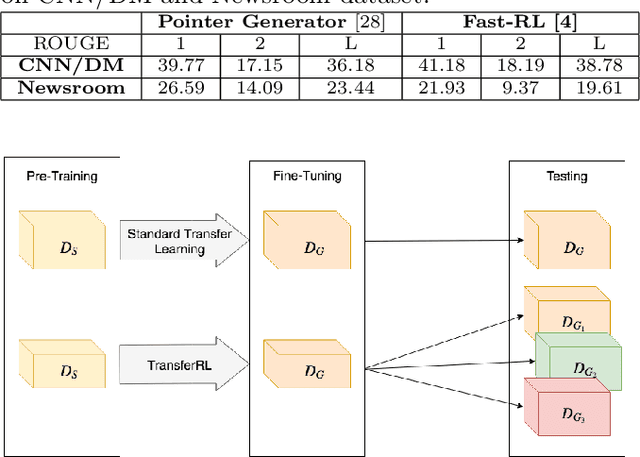
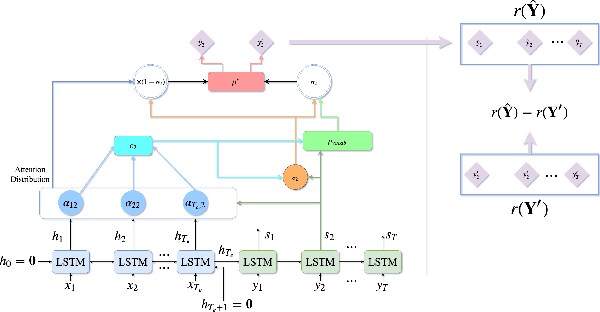


Deep neural networks are data hungry models and thus they face difficulties when used for training on small size data. Transfer learning is a method that could potentially help in such situations. Although transfer learning achieved great success in image processing, its effect in the text domain is yet to be well established especially due to several intricacies that arise in the context of document analysis and understanding. In this paper, we study the problem of transfer learning for text summarization and discuss why the existing state-of-the-art models for this problem fail to generalize well on other (unseen) datasets. We propose a reinforcement learning framework based on self-critic policy gradient method which solves this problem and achieves good generalization and state-of-the-art results on a variety of datasets. Through an extensive set of experiments, we also show the ability of our proposed framework in fine-tuning the text summarization model only with a few training samples. To the best of our knowledge, this is first work that studies transfer learning in text summarization and provides a generic solution that works well on unseen data.
Deep Reinforcement Learning For Sequence to Sequence Models
Jul 20, 2018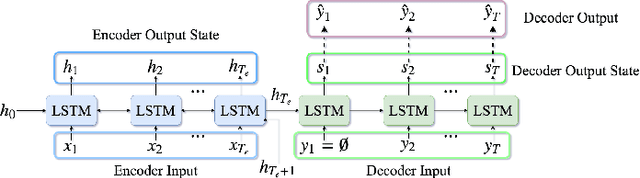

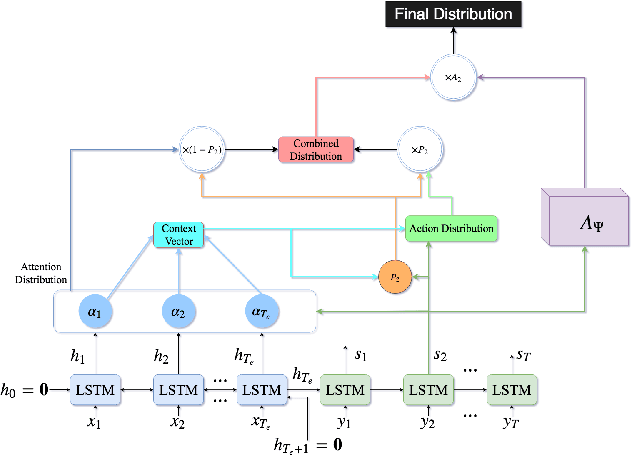
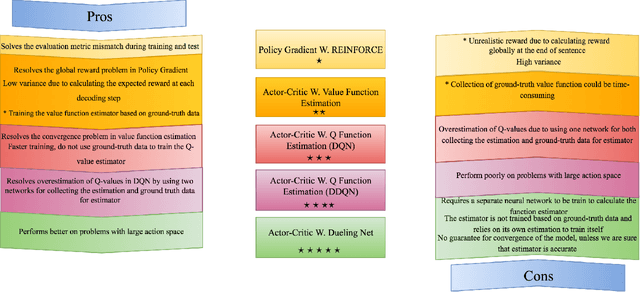
In recent times, sequence-to-sequence (seq2seq) models have gained a lot of popularity and provide state-of-the-art performance in a wide variety of tasks such as machine translation, headline generation, text summarization, speech to text conversion, and image caption generation. The underlying framework for all these models is usually a deep neural network comprising an encoder and a decoder. Although simple encoder-decoder models produce competitive results, many researchers have proposed additional improvements over these sequence-to-sequence models, e.g., using an attention-based model over the input, pointer-generation models, and self-attention models. However, such seq2seq models suffer from two common problems: 1) exposure bias and 2) inconsistency between train/test measurement. Recently, a completely novel point of view has emerged in addressing these two problems in seq2seq models, leveraging methods from reinforcement learning (RL). In this survey, we consider seq2seq problems from the RL point of view and provide a formulation combining the power of RL methods in decision-making with sequence-to-sequence models that enable remembering long-term memories. We present some of the most recent frameworks that combine concepts from RL and deep neural networks and explain how these two areas could benefit from each other in solving complex seq2seq tasks. Our work aims to provide insights into some of the problems that inherently arise with current approaches and how we can address them with better RL models. We also provide the source code for implementing most of the RL models discussed in this paper to support the complex task of abstractive text summarization.