 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAPPA-GANs for Parallel MRI Reconstruction
Jan 05, 2021
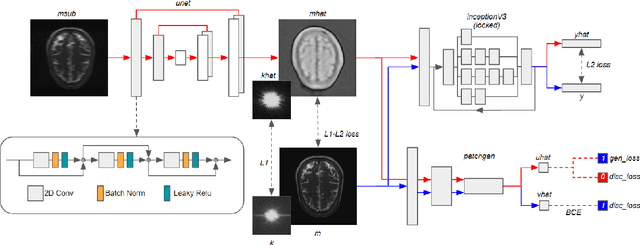
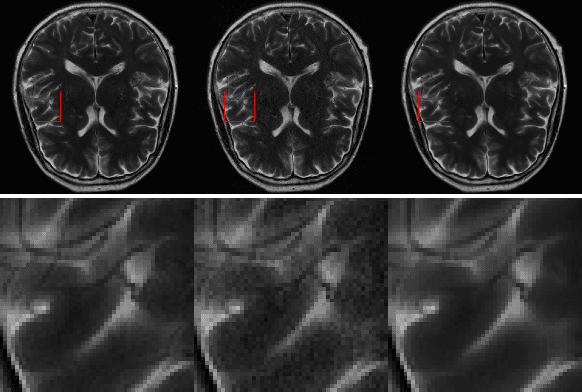
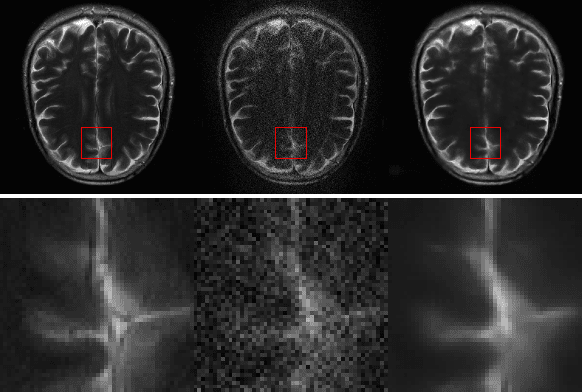
k-space undersampling is a standard technique to accelerate MR image acquisitions. Reconstruction techniques including GeneRalized Autocalibrating Partial Parallel Acquisition(GRAPPA) and its variants are utilized extensively in clinical and research settings. A reconstruction model combining GRAPPA with a conditional generative adversarial network (GAN) was developed and tested on multi-coil human brain images from the fastMRI dataset. For various acceleration rates, GAN and GRAPPA reconstructions were compared in terms of peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). For an acceleration rate of R=4, PSNR improved from 33.88 using regularized GRAPPA to 37.65 using GAN. GAN consistently outperformed GRAPPA for various acceleration rates.
Differentially Private Synthetic Medical Data Generation using Convolutional GANs
Dec 22, 2020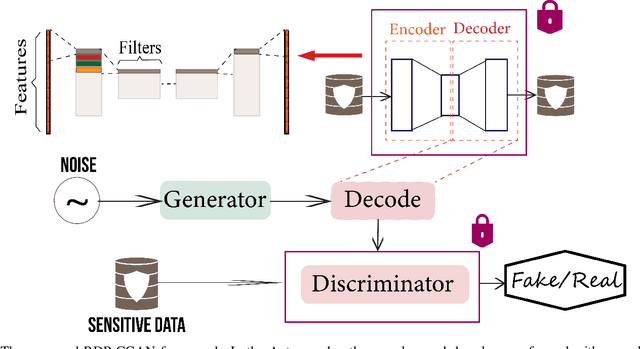
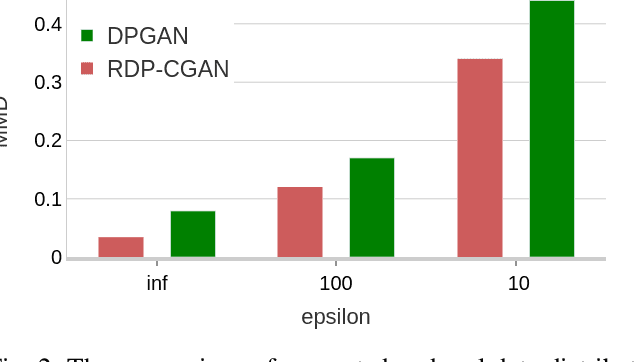
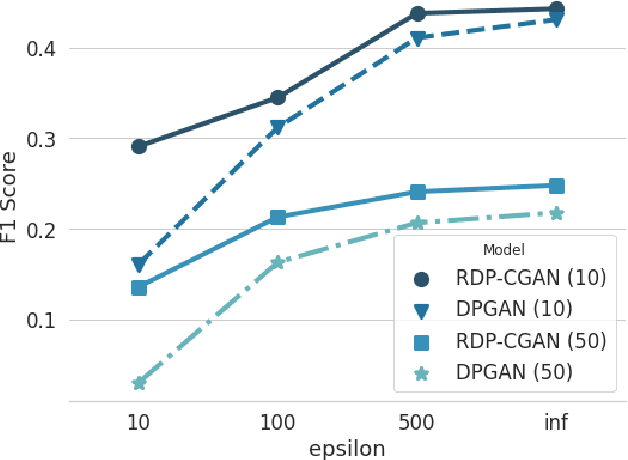
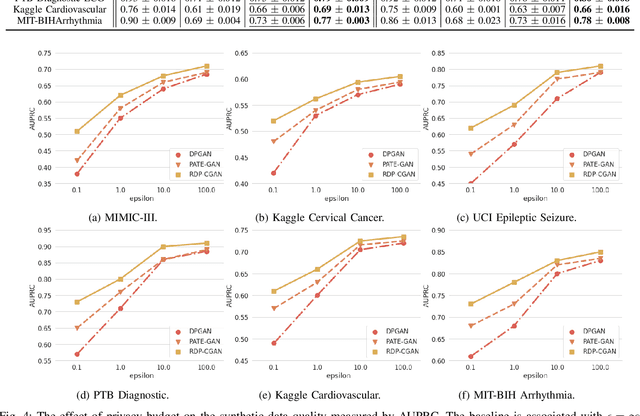
Deep learning models have demonstrated superior performance in several application problems, such as image classification and speech processing. However, creating a deep learning model using health record data requires addressing certain privacy challenges that bring unique concerns to researchers working in this domain. One effective way to handle such private data issues is to generate realistic synthetic data that can provide practically acceptable data quality and correspondingly the model performance. To tackle this challenge, we develop a differentially private framework for synthetic data generation using R\'enyi differential privacy. Our approach builds on convolutional autoencoders and convolutional generative adversarial networks to preserve some of the critical characteristics of the generated synthetic data. In addition, our model can also capture the temporal information and feature correlations that might be present in the original data. We demonstrate that our model outperforms existing state-of-the-art models under the same privacy budget using several publicly available benchmark medical datasets in both supervised and unsupervised settings.
On the Evaluation of Generative Adversarial Networks By Discriminative Models
Oct 07, 2020

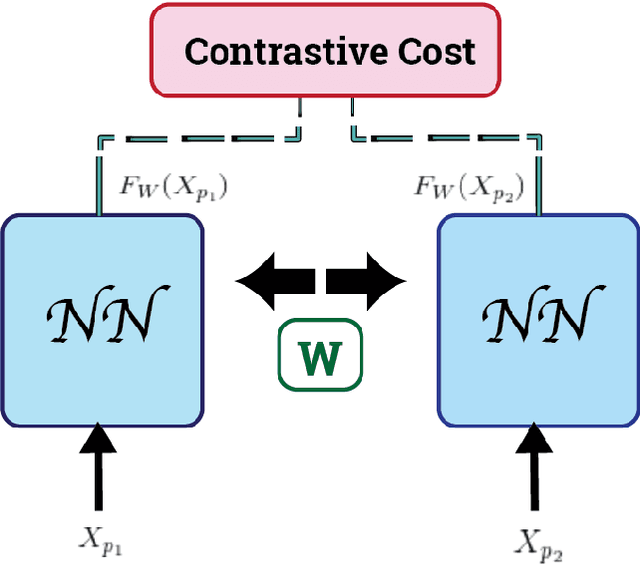
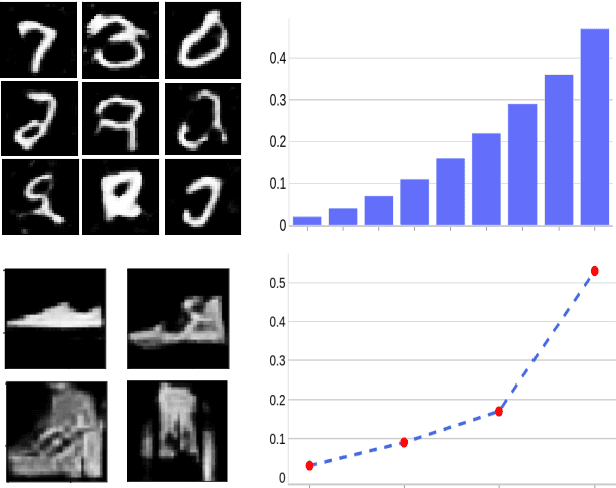
Generative Adversarial Networks (GANs) can accurately model complex multi-dimensional data and generate realistic samples. However, due to their implicit estimation of data distributions, their evaluation is a challenging task. The majority of research efforts associated with tackling this issue were validated by qualitative visual evaluation. Such approaches do not generalize well beyond the image domain. Since many of those evaluation metrics are proposed and bound to the vision domain, they are difficult to apply to other domains. Quantitative measures are necessary to better guide the training and comparison of different GANs models. In this work, we leverage Siamese neural networks to propose a domain-agnostic evaluation metric: (1) with a qualitative evaluation that is consistent with human evaluation, (2) that is robust relative to common GAN issues such as mode dropping and invention, and (3) does not require any pretrained classifier. The empirical results in this paper demonstrate the superiority of this method compared to the popular Inception Score and are competitive with the FID score.
CorGAN: Correlation-Capturing Convolutional Generative Adversarial Networks for Generating Synthetic Healthcare Records
Mar 04, 2020
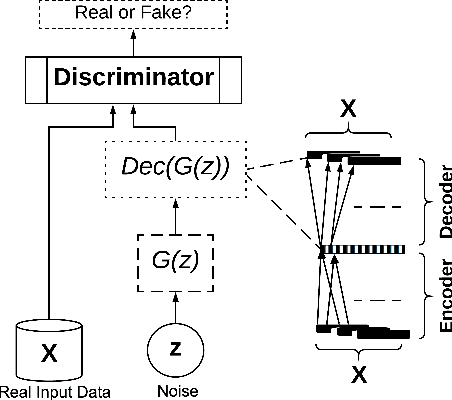


Deep learning models have demonstrated high-quality performance in areas such as image classification and speech processing. However, creating a deep learning model using electronic health record (EHR) data, requires addressing particular privacy challenges that are unique to researchers in this domain. This matter focuses attention on generating realistic synthetic data while ensuring privacy. In this paper, we propose a novel framework called correlation-capturing Generative Adversarial Network (CorGAN), to generate synthetic healthcare records. In CorGAN we utilize Convolutional Neural Networks to capture the correlations between adjacent medical features in the data representation space by combining Convolutional Generative Adversarial Networks and Convolutional Autoencoders. To demonstrate the model fidelity, we show that CorGAN generates synthetic data with performance similar to that of real data in various Machine Learning settings such as classification and prediction. We also give a privacy assessment and report on statistical analysis regarding realistic characteristics of the synthetic data. The software of this work is open-source and is available at: https://github.com/astorfi/cor-gan.
Natural Language Processing Advancements By Deep Learning: A Survey
Mar 04, 2020
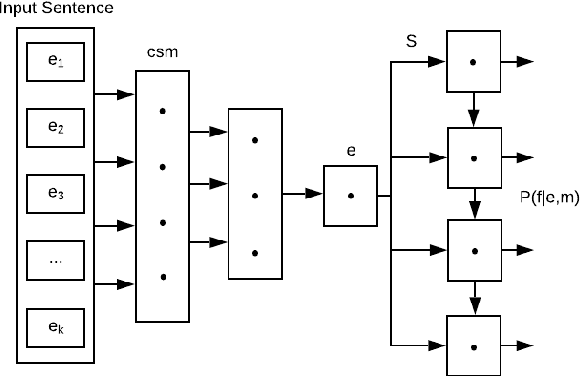


Natural Language Processing (NLP) helps empower intelligent machines by enhancing a better understanding of the human language for linguistic-based human-computer communication. Recent developments in computational power and the advent of large amounts of linguistic data have heightened the need and demand for automating semantic analysis using data-driven approaches. The utilization of data-driven strategies is pervasive now due to the significant improvements demonstrated through the usage of deep learning methods in areas such as Computer Vision, Automatic Speech Recognition, and in particular, NLP. This survey categorizes and addresses the different aspects and applications of NLP that have benefited from deep learning. It covers core NLP tasks and applications and describes how deep learning methods and models advance these areas. We further analyze and compare different approaches and state-of-the-art models.
GASL: Guided Attention for Sparsity Learning in Deep Neural Networks
Jan 15, 2019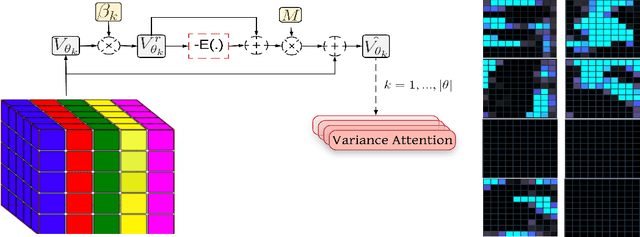
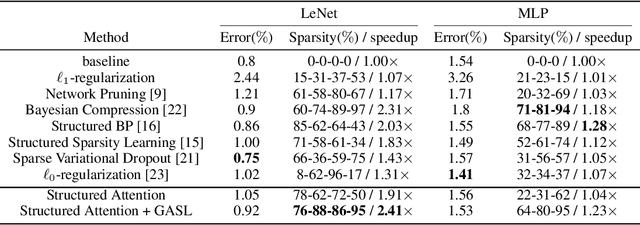
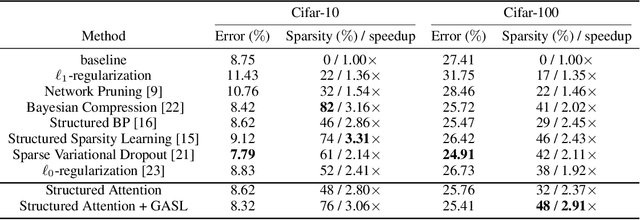
The main goal of network pruning is imposing sparsity on the neural network by increasing the number of parameters with zero value in order to reduce the architecture size and the computational speedup. In most of the previous research works, sparsity is imposed stochastically without considering any prior knowledge of the weights distribution or other internal network characteristics. Enforcing too much sparsity may induce accuracy drop due to the fact that a lot of important elements might have been eliminated. In this paper, we propose Guided Attention for Sparsity Learning (GASL) to achieve (1) model compression by having less number of elements and speed-up; (2) prevent the accuracy drop by supervising the sparsity operation via a guided attention mechanism and (3) introduce a generic mechanism that can be adapted for any type of architecture; Our work is aimed at providing a framework based on interpretable attention mechanisms for imposing structured and non-structured sparsity in deep neural networks. For Cifar-100 experiments, we achieved the state-of-the-art sparsity level and 2.91x speedup with competitive accuracy compared to the best method. For MNIST and LeNet architecture we also achieved the highest sparsity and speedup level.
Attention-Based Guided Structured Sparsity of Deep Neural Networks
Jul 14, 2018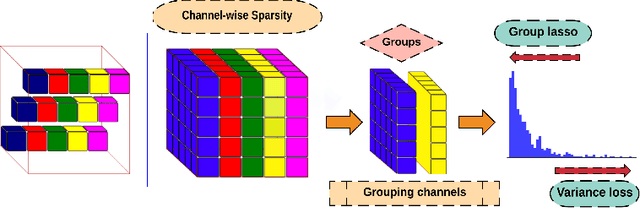
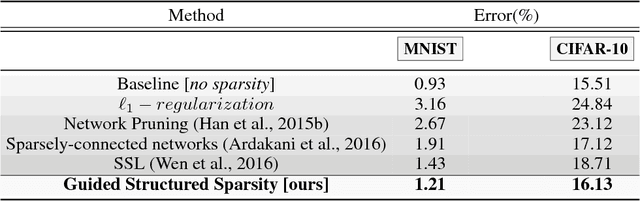
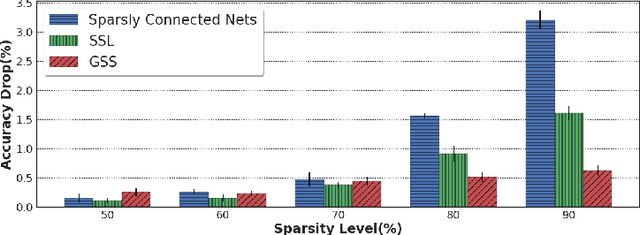
Network pruning is aimed at imposing sparsity in a neural network architecture by increasing the portion of zero-valued weights for reducing its size regarding energy-efficiency consideration and increasing evaluation speed. In most of the conducted research efforts, the sparsity is enforced for network pruning without any attention to the internal network characteristics such as unbalanced outputs of the neurons or more specifically the distribution of the weights and outputs of the neurons. That may cause severe accuracy drop due to uncontrolled sparsity. In this work, we propose an attention mechanism that simultaneously controls the sparsity intensity and supervised network pruning by keeping important information bottlenecks of the network to be active. On CIFAR-10, the proposed method outperforms the best baseline method by 6% and reduced the accuracy drop by 2.6x at the same level of sparsity.
Generalized Bilinear Deep Convolutional Neural Networks for Multimodal Biometric Identification
Jul 03, 2018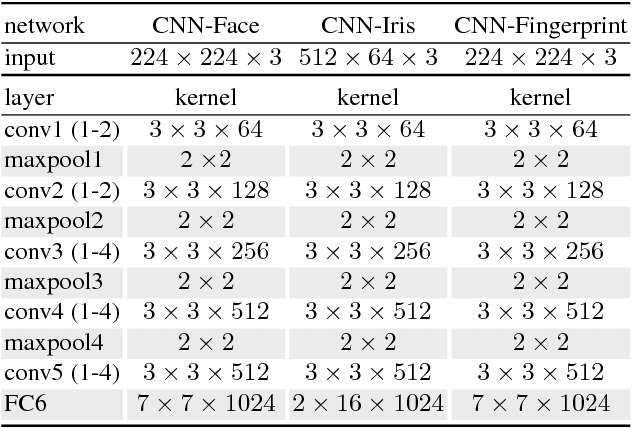
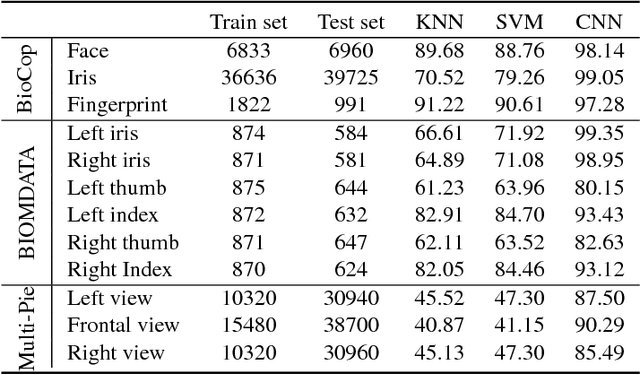
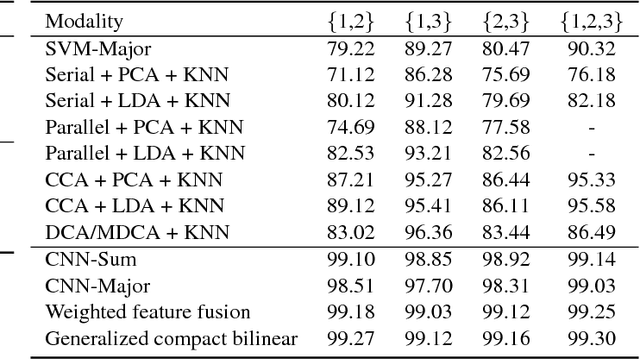
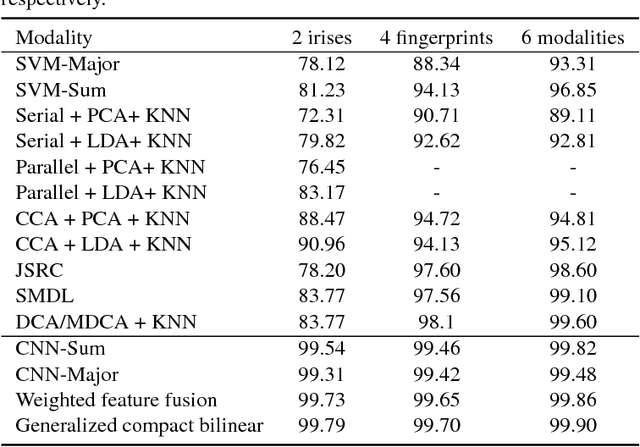
In this paper, we propose to employ a bank of modality-dedicated Convolutional Neural Networks (CNNs), fuse, train, and optimize them together for person classification tasks. A modality-dedicated CNN is used for each modality to extract modality-specific features. We demonstrate that, rather than spatial fusion at the convolutional layers, the fusion can be performed on the outputs of the fully-connected layers of the modality-specific CNNs without any loss of performance and with significant reduction in the number of parameters. We show that, using multiple CNNs with multimodal fusion at the feature-level, we significantly outperform systems that use unimodal representation. We study weighted feature, bilinear, and compact bilinear feature-level fusion algorithms for multimodal biometric person identification. Finally, We propose generalized compact bilinear fusion algorithm to deploy both the weighted feature fusion and compact bilinear schemes. We provide the results for the proposed algorithms on three challenging databases: CMU Multi-PIE, BioCop, and BIOMDATA.
Text-Independent Speaker Verification Using 3D Convolutional Neural Networks
Jun 06, 2018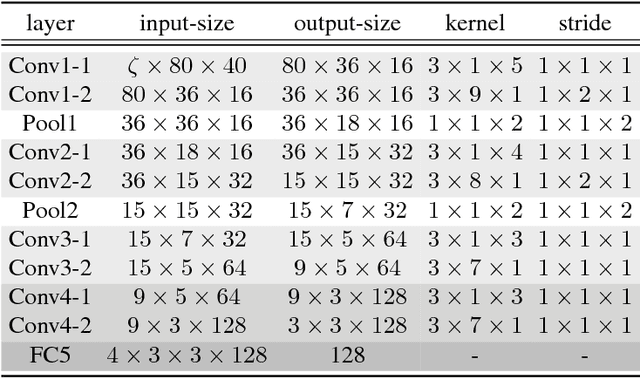
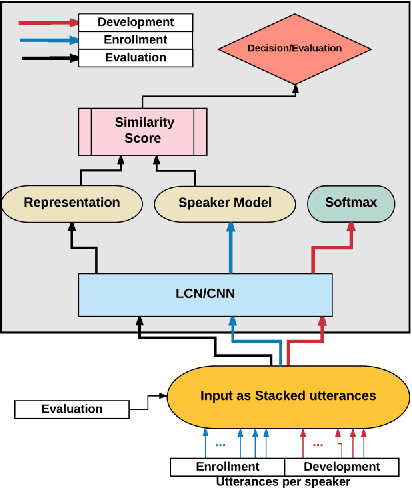
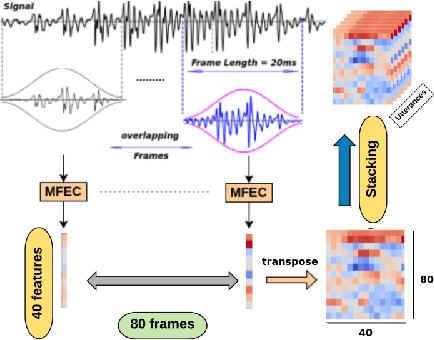
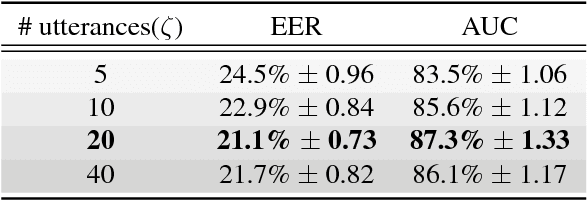
In this paper, a novel method using 3D Convolutional Neural Network (3D-CNN) architecture has been proposed for speaker verification in the text-independent setting. One of the main challenges is the creation of the speaker models. Most of the previously-reported approaches create speaker models based on averaging the extracted features from utterances of the speaker, which is known as the d-vector system. In our paper, we propose an adaptive feature learning by utilizing the 3D-CNNs for direct speaker model creation in which, for both development and enrollment phases, an identical number of spoken utterances per speaker is fed to the network for representing the speakers' utterances and creation of the speaker model. This leads to simultaneously capturing the speaker-related information and building a more robust system to cope with within-speaker variation. We demonstrate that the proposed method significantly outperforms the traditional d-vector verification system. Moreover, the proposed system can also be an alternative to the traditional d-vector system which is a one-shot speaker modeling system by utilizing 3D-CNNs.
3D Convolutional Neural Networks for Cross Audio-Visual Matching Recognition
Aug 13, 2017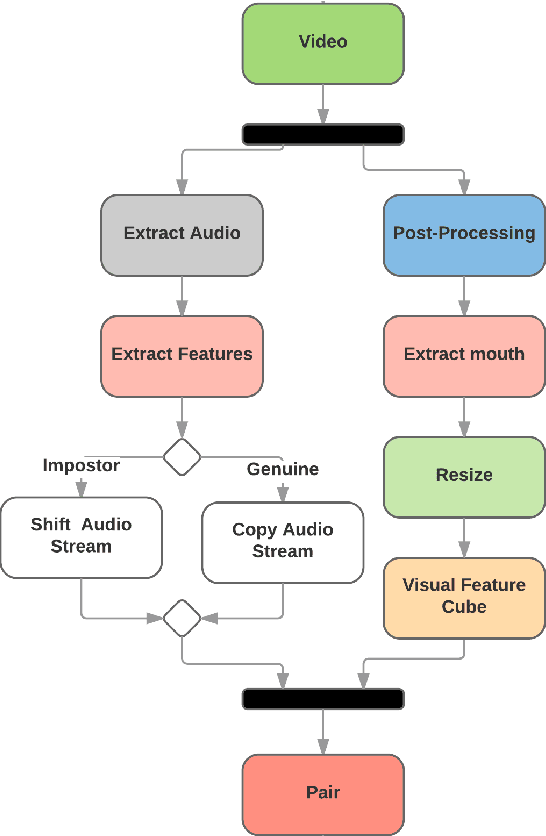
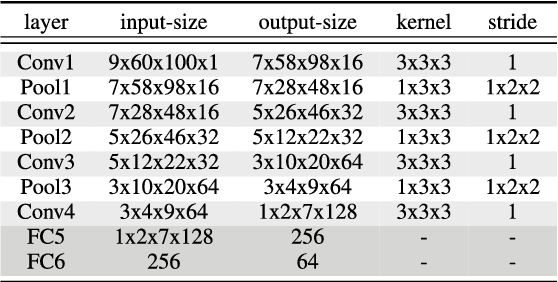
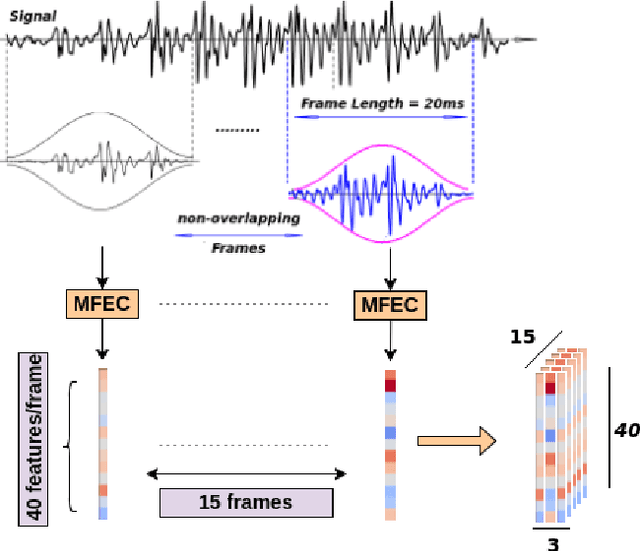
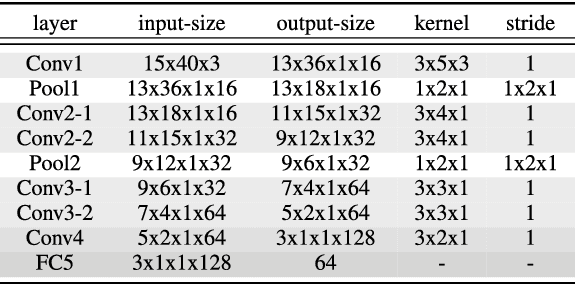
Audio-visual recognition (AVR) has been considered as a solution for speech recognition tasks when the audio is corrupted, as well as a visual recognition method used for speaker verification in multi-speaker scenarios. The approach of AVR systems is to leverage the extracted information from one modality to improve the recognition ability of the other modality by complementing the missing information. The essential problem is to find the correspondence between the audio and visual streams, which is the goal of this work. We propose the use of a coupled 3D Convolutional Neural Network (3D-CNN) architecture that can map both modalities into a representation space to evaluate the correspondence of audio-visual streams using the learned multimodal features. The proposed architecture will incorporate both spatial and temporal information jointly to effectively find the correlation between temporal information for different modalities. By using a relatively small network architecture and much smaller dataset for training, our proposed method surpasses the performance of the existing similar methods for audio-visual matching which use 3D CNNs for feature representation. We also demonstrate that an effective pair selection method can significantly increase the performance. The proposed method achieves relative improvements over 20% on the Equal Error Rate (EER) and over 7% on the Average Precision (AP) in comparison to the state-of-the-art method.