 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASL: Guided Attention for Sparsity Learning in Deep Neural Networks
Paper and Code
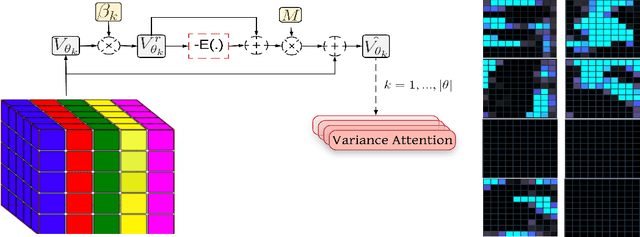
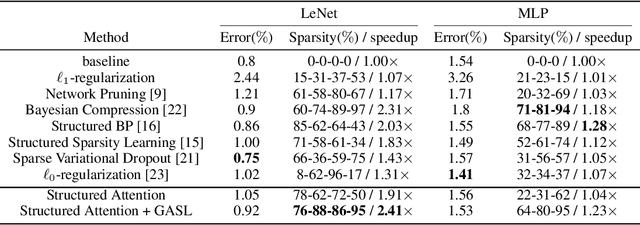
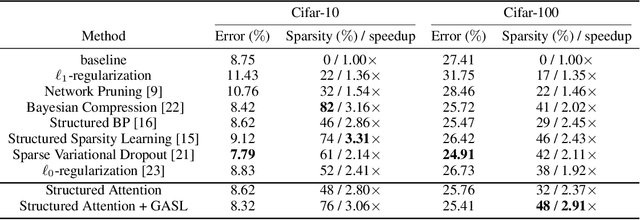
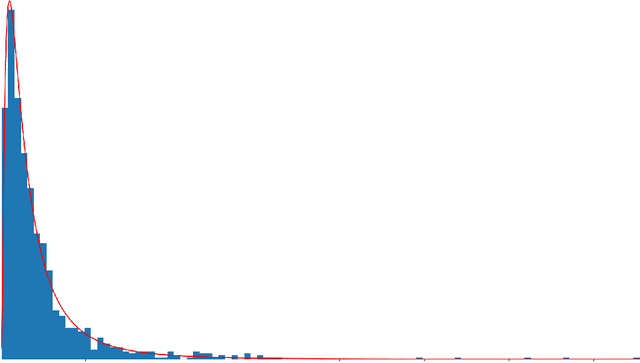
The main goal of network pruning is imposing sparsity on the neural network by increasing the number of parameters with zero value in order to reduce the architecture size and the computational speedup. In most of the previous research works, sparsity is imposed stochastically without considering any prior knowledge of the weights distribution or other internal network characteristics. Enforcing too much sparsity may induce accuracy drop due to the fact that a lot of important elements might have been eliminated. In this paper, we propose Guided Attention for Sparsity Learning (GASL) to achieve (1) model compression by having less number of elements and speed-up; (2) prevent the accuracy drop by supervising the sparsity operation via a guided attention mechanism and (3) introduce a generic mechanism that can be adapted for any type of architecture; Our work is aimed at providing a framework based on interpretable attention mechanisms for imposing structured and non-structured sparsity in deep neural networks. For Cifar-100 experiments, we achieved the state-of-the-art sparsity level and 2.91x speedup with competitive accuracy compared to the best method. For MNIST and LeNet architecture we also achieved the highest sparsity and speedup level.