 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning For Sequence to Sequence Models
Paper and Code
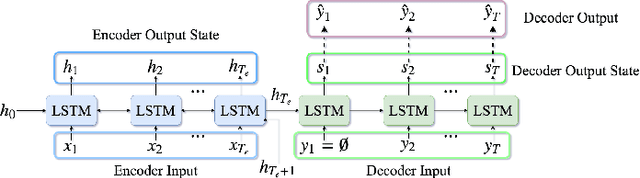

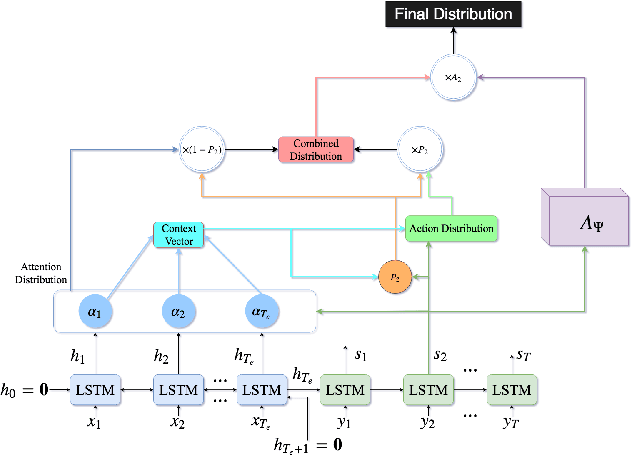
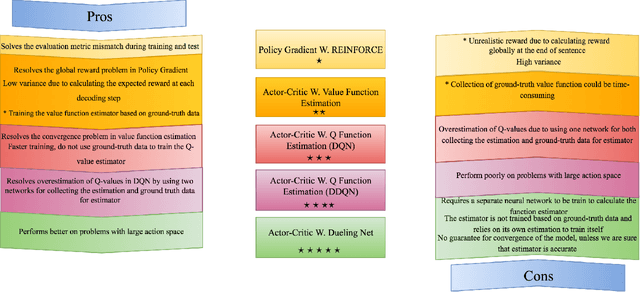
In recent times, sequence-to-sequence (seq2seq) models have gained a lot of popularity and provide state-of-the-art performance in a wide variety of tasks such as machine translation, headline generation, text summarization, speech to text conversion, and image caption generation. The underlying framework for all these models is usually a deep neural network comprising an encoder and a decoder. Although simple encoder-decoder models produce competitive results, many researchers have proposed additional improvements over these sequence-to-sequence models, e.g., using an attention-based model over the input, pointer-generation models, and self-attention models. However, such seq2seq models suffer from two common problems: 1) exposure bias and 2) inconsistency between train/test measurement. Recently, a completely novel point of view has emerged in addressing these two problems in seq2seq models, leveraging methods from reinforcement learning (RL). In this survey, we consider seq2seq problems from the RL point of view and provide a formulation combining the power of RL methods in decision-making with sequence-to-sequence models that enable remembering long-term memories. We present some of the most recent frameworks that combine concepts from RL and deep neural networks and explain how these two areas could benefit from each other in solving complex seq2seq tasks. Our work aims to provide insights into some of the problems that inherently arise with current approaches and how we can address them with better RL models. We also provide the source code for implementing most of the RL models discussed in this paper to support the complex task of abstractive text summarization.