 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Abstractive Text Summarization with Sequence-to-Sequence Models
Paper and Code
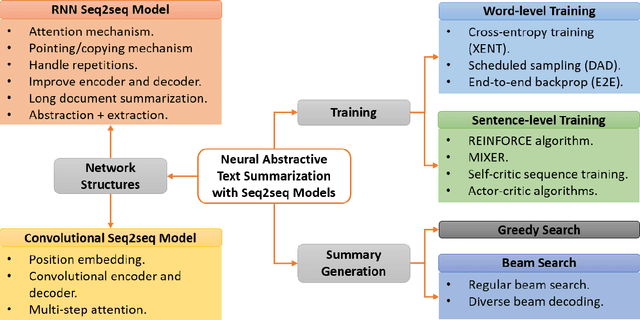
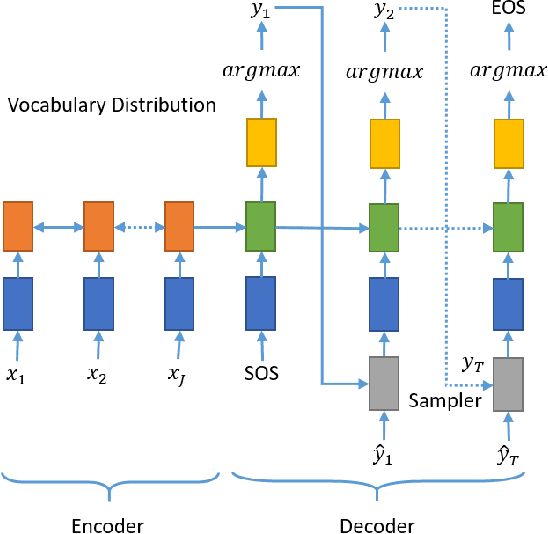
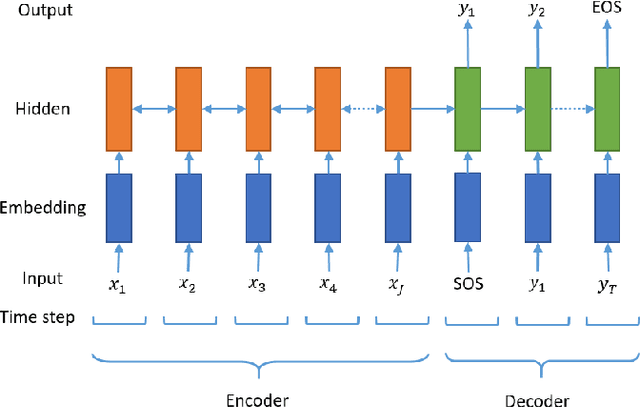
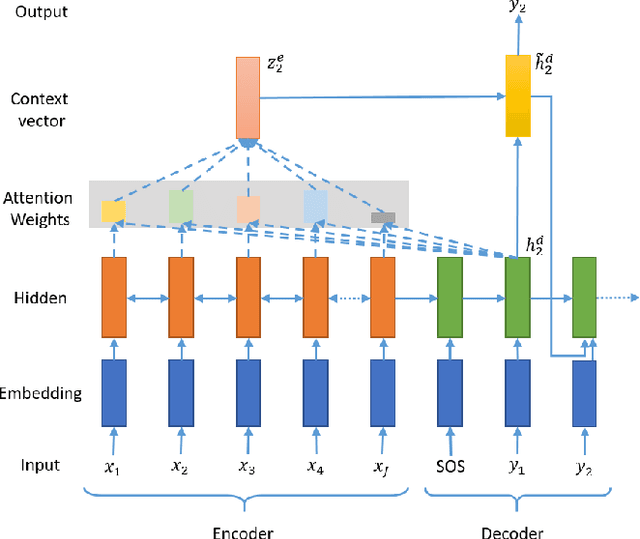
In the past few years, neural abstractive text summarization with sequence-to-sequence (seq2seq) models have gained a lot of popularity. Many interesting techniques have been proposed to improve the seq2seq models, making them capable of handling different challenges, such as saliency, fluency and human readability, and generate high-quality summaries. Generally speaking, most of these techniques differ in one of these three categories: network structure, parameter inference, and decoding/generation. There are also other concerns, such as efficiency and parallelism for training a model. In this paper, we provide a comprehensive literature and technical survey on different seq2seq models for abstractive text summarization from viewpoint of network structures, training strategies, and summary generation algorithms. Many models were first proposed for language modeling and generation tasks, such as machine translation, and later applied to abstractive text summarization. Therefore, we also provide a brief review of these models. As part of this survey, we also develop an open source library, namely Neural Abstractive Text Summarizer (NATS) toolkit, for the abstractive text summarization. An extensive set of experiments have been conducted on the widely used CNN/Daily Mail dataset to examine the effectiveness of several different neural network components. Finally, we benchmark two models implemented in NATS on two recently released datasets, i.e., Newsroom and Bytecup.