 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Graph Neural Network Activation Patterns Through Graph Topology
Feb 24, 2026Curvature notions on graphs provide a theoretical description of graph topology, highlighting bottlenecks and denser connected regions. Artifacts of the message passing paradigm in Graph Neural Networks, such as oversmoothing and oversquashing, have been attributed to these regions. However, it remains unclear how the topology of a graph interacts with the learned preferences of GNNs. Through Massive Activations, which correspond to extreme edge activation values in Graph Transformers, we probe this correspondence. Our findings on synthetic graphs and molecular benchmarks reveal that MAs do not preferentially concentrate on curvature extremes, despite their theoretical link to information flow. On the Long Range Graph Benchmark, we identify a systemic \textit{curvature shift}: global attention mechanisms exacerbate topological bottlenecks, drastically increasing the prevalence of negative curvature. Our work reframes curvature as a diagnostic probe for understanding when and why graph learning fails.
Injecting Hierarchical Biological Priors into Graph Neural Networks for Flow Cytometry Prediction
May 28, 2024In the complex landscape of hematologic samples such as peripheral blood or bone marrow derived from flow cytometry (FC) data, cell-level prediction presents profound challenges. This work explores injecting hierarchical prior knowledge into graph neural networks (GNNs) for single-cell multi-class classification of tabular cellular data. By representing the data as graphs and encoding hierarchical relationships between classes, we propose our hierarchical plug-in method to be applied to several GNN models, namely, FCHC-GNN, and effectively designed to capture neighborhood information crucial for single-cell FC domain. Extensive experiments on our cohort of 19 distinct patients, demonstrate that incorporating hierarchical biological constraints boosts performance significantly across multiple metrics compared to baseline GNNs without such priors. The proposed approach highlights the importance of structured inductive biases for gaining improved generalization in complex biological prediction tasks.
Why Attention Graphs Are All We Need: Pioneering Hierarchical Classification of Hematologic Cell Populations with LeukoGraph
Feb 28, 2024
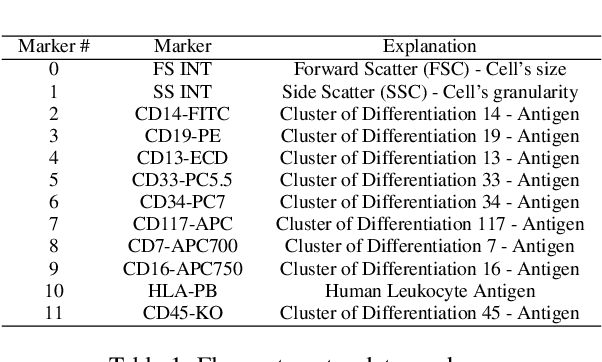
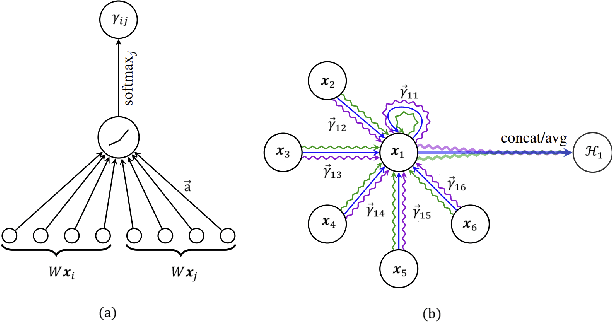
In the complex landscape of hematologic samples such as peripheral blood or bone marrow, cell classification, delineating diverse populations into a hierarchical structure, presents profound challenges. This study presents LeukoGraph, a recently developed framework designed explicitly for this purpose employing graph attention networks (GATs) to navigate hierarchical classification (HC) complexities. Notably, LeukoGraph stands as a pioneering effort, marking the application of graph neural networks (GNNs) for hierarchical inference on graphs, accommodating up to one million nodes and millions of edges, all derived from flow cytometry data. LeukoGraph intricately addresses a classification paradigm where for example four different cell populations undergo flat categorization, while a fifth diverges into two distinct child branches, exemplifying the nuanced hierarchical structure inherent in complex datasets. The technique is more general than this example. A hallmark achievement of LeukoGraph is its F-score of 98%, significantly outclassing prevailing state-of-the-art methodologies. Crucially, LeukoGraph's prowess extends beyond theoretical innovation, showcasing remarkable precision in predicting both flat and hierarchical cell types across flow cytometry datasets from 30 distinct patients. This precision is further underscored by LeukoGraph's ability to maintain a correct label ratio, despite the inherent challenges posed by hierarchical classifications.
FlowCyt: A Comparative Study of Deep Learning Approaches for Multi-Class Classification in Flow Cytometry Benchmarking
Feb 28, 2024



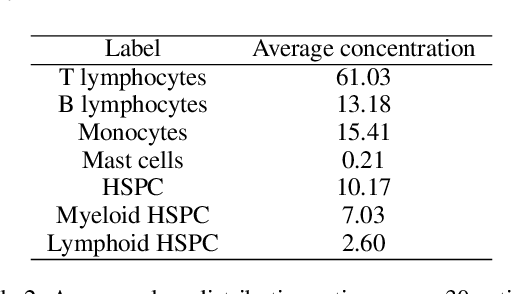
This paper presents FlowCyt, the first comprehensive benchmark for multi-class single-cell classification in flow cytometry data. The dataset comprises bone marrow samples from 30 patients, with each cell characterized by twelve markers. Ground truth labels identify five hematological cell types: T lymphocytes, B lymphocytes, Monocytes, Mast cells, and Hematopoietic Stem/Progenitor Cells (HSPCs). Experiments utilize supervised inductive learning and semi-supervised transductive learning on up to 1 million cells per patient. Baseline methods include Gaussian Mixture Models, XGBoost, Random Forests, Deep Neural Networks, and Graph Neural Networks (GNNs). GNNs demonstrate superior performance by exploiting spatial relationships in graph-encoded data. The benchmark allows standardized evaluation of clinically relevant classification tasks, along with exploratory analyses to gain insights into hematological cell phenotypes. This represents the first public flow cytometry benchmark with a richly annotated, heterogeneous dataset. It will empower the development and rigorous assessment of novel methodologies for single-cell analysis.
HemaGraph: Breaking Barriers in Hematologic Single Cell Classification with Graph Attention
Feb 28, 2024In the realm of hematologic cell populations classification, the intricate patterns within flow cytometry data necessitate advanced analytical tools. This paper presents 'HemaGraph', a novel framework based on Graph Attention Networks (GATs) for single-cell multi-class classification of hematological cells from flow cytometry data. Harnessing the power of GATs, our method captures subtle cell relationships, offering highly accurate patient profiling. Based on evaluation of data from 30 patients, HemaGraph demonstrates classification performance across five different cell classes, outperforming traditional methodologies and state-of-the-art methods. Moreover, the uniqueness of this framework lies in the training and testing phase of HemaGraph, where it has been applied for extremely large graphs, containing up to hundreds of thousands of nodes and two million edges, to detect low frequency cell populations (e.g. 0.01% for one population), with accuracies reaching 98%. Our findings underscore the potential of HemaGraph in improving hematoligic multi-class classification, paving the way for patient-personalized interventions. To the best of our knowledge, this is the first effort to use GATs, and Graph Neural Networks (GNNs) in general, to classify cell populations from single-cell flow cytometry data. We envision applying this method to single-cell data from larger cohort of patients and on other hematologic diseases.
Supervised Auto-Encoding Twin-Bottleneck Hashing
Jun 19, 2023Deep hashing has shown to be a complexity-efficient solution for the Approximate Nearest Neighbor search problem in high dimensional space. Many methods usually build the loss function from pairwise or triplet data points to capture the local similarity structure. Other existing methods construct the similarity graph and consider all points simultaneously. Auto-encoding Twin-bottleneck Hashing is one such method that dynamically builds the graph. Specifically, each input data is encoded into a binary code and a continuous variable, or the so-called twin bottlenecks. The similarity graph is then computed from these binary codes, which get updated consistently during the training. In this work, we generalize the original model into a supervised deep hashing network by incorporating the label information. In addition, we examine the differences of codes structure between these two networks and consider the class imbalance problem especially in multi-labeled datasets. Experiments on three datasets yield statistically significant improvement against the original model. Results are also comparable and competitive to other supervised methods.
Cold Start Active Learning Strategies in the Context of Imbalanced Classification
Jan 25, 2022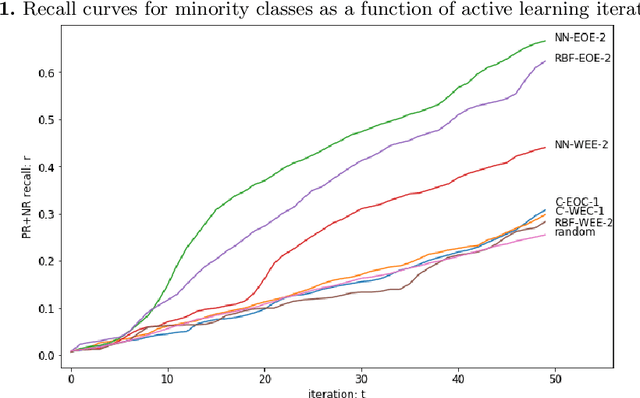
We present novel active learning strategies dedicated to providing a solution to the cold start stage, i.e. initializing the classification of a large set of data with no attached labels. Moreover, proposed strategies are designed to handle an imbalanced context in which random selection is highly inefficient. Specifically, our active learning iterations address label scarcity and imbalance using element scores, combining information extracted from a clustering structure to a label propagation model. The strategy is illustrated by a case study on annotating Twitter content w.r.t. testimonies of a real flood event. We show that our method effectively copes with class imbalance, by boosting the recall of samples from the minority class.
Towards Efficient Cross-Modal Visual Textual Retrieval using Transformer-Encoder Deep Features
Jun 01, 2021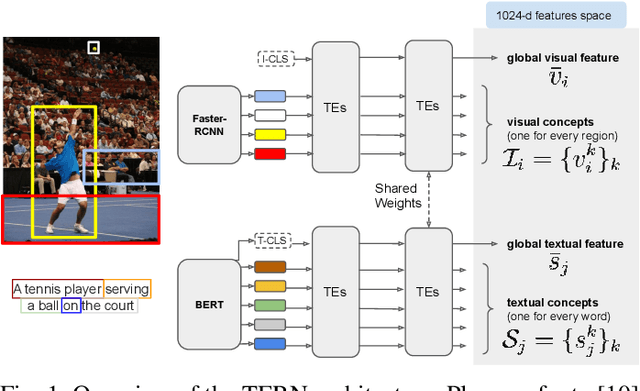
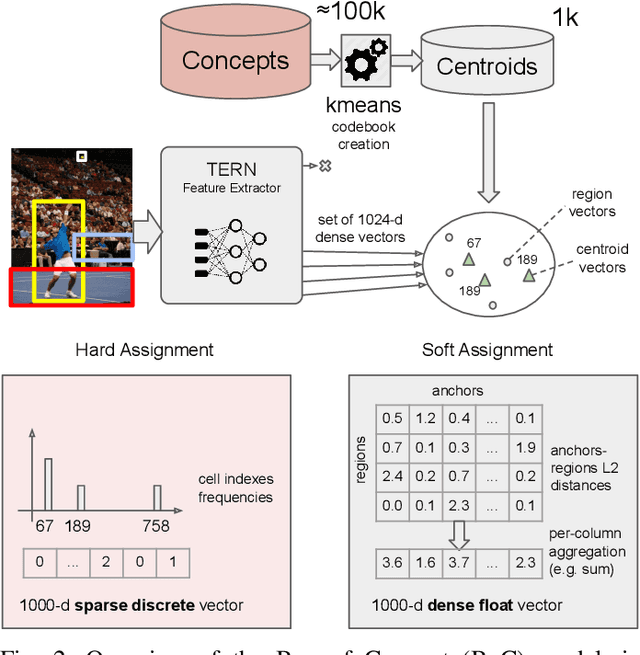
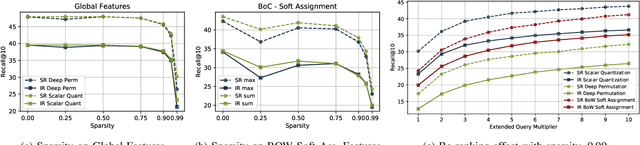
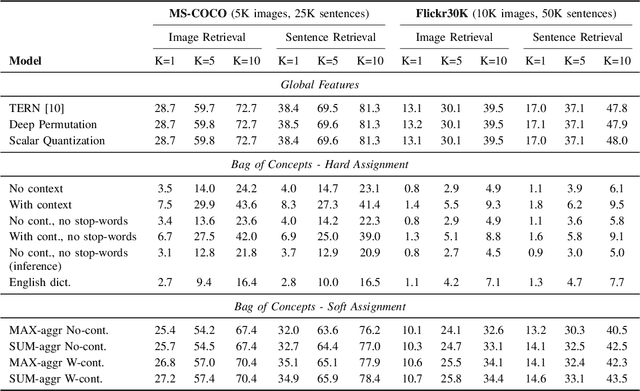
Cross-modal retrieval is an important functionality in modern search engines, as it increases the user experience by allowing queries and retrieved objects to pertain to different modalities. In this paper, we focus on the image-sentence retrieval task, where the objective is to efficiently find relevant images for a given sentence (image-retrieval) or the relevant sentences for a given image (sentence-retrieval). Computer vision literature reports the best results on the image-sentence matching task using deep neural networks equipped with attention and self-attention mechanisms. They evaluate the matching performance on the retrieval task by performing sequential scans of the whole dataset. This method does not scale well with an increasing amount of images or captions. In this work, we explore different preprocessing techniques to produce sparsified deep multi-modal features extracting them from state-of-the-art deep-learning architectures for image-text matching. Our main objective is to lay down the paths for efficient indexing of complex multi-modal descriptions. We use the recently introduced TERN architecture as an image-sentence features extractor. It is designed for producing fixed-size 1024-d vectors describing whole images and sentences, as well as variable-length sets of 1024-d vectors describing the various building components of the two modalities (image regions and sentence words respectively). All these vectors are enforced by the TERN design to lie into the same common space. Our experiments show interesting preliminary results on the explored methods and suggest further experimentation in this important research direction.
Computing flood probabilities using Twitter: application to the Houston urban area during Harvey
Dec 07, 2020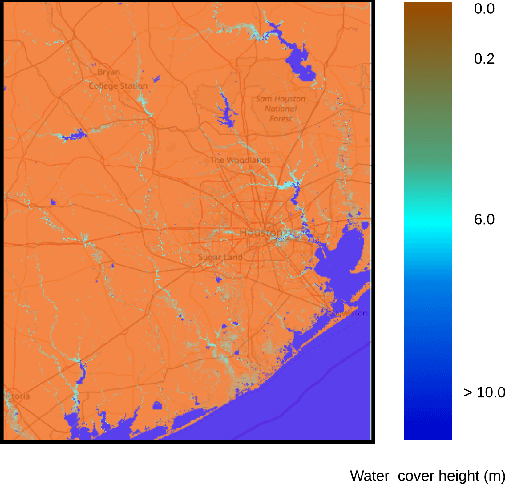
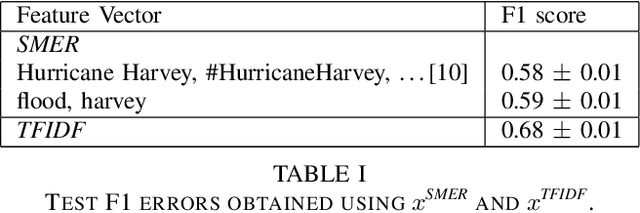
In this paper, we investigate the conversion of a Twitter corpus into geo-referenced raster cells holding the probability of the associated geographical areas of being flooded. We describe a baseline approach that combines a density ratio function, aggregation using a spatio-temporal Gaussian kernel function, and TFIDF textual features. The features are transformed to probabilities using a logistic regression model. The described method is evaluated on a corpus collected after the floods that followed Hurricane Harvey in the Houston urban area in August-September 2017. The baseline reaches a F1 score of 68%. We highlight research directions likely to improve these initial results.
Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders
Aug 12, 2020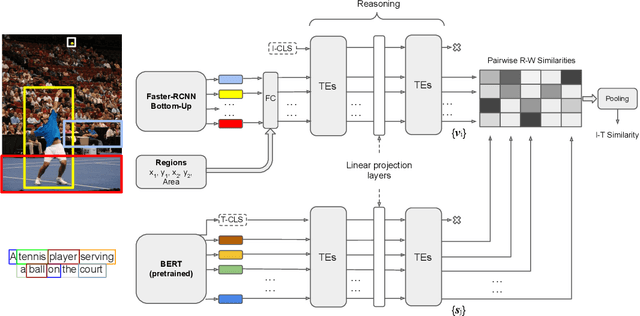
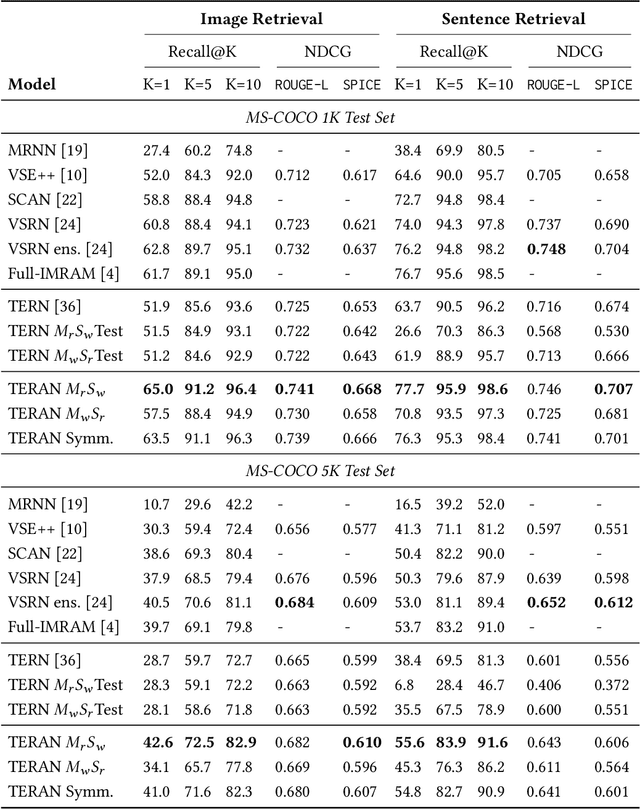
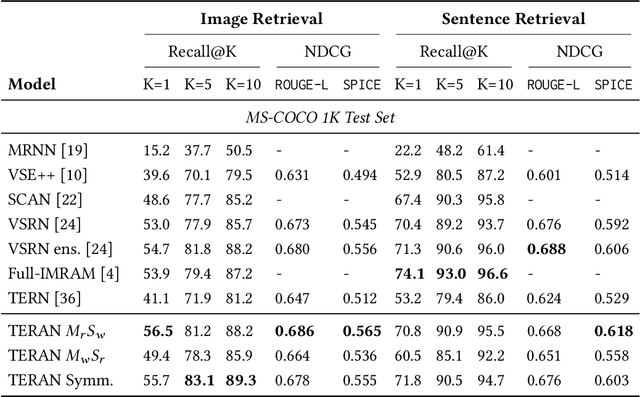

Despite the evolution of deep-learning-based visual-textual processing systems, precise multi-modal matching remains a challenging task. In this work, we tackle the problem of accurate cross-media retrieval through image-sentence matching based on word-region alignments using supervision only at the global image-sentence level. In particular, we present an approach called Transformer Encoder Reasoning and Alignment Network (TERAN). TERAN enforces a fine-grained match between the underlying components of images and sentences, i.e., image regions and words, respectively, in order to preserve the informative richness of both modalities. The proposed approach obtains state-of-the-art results on the image retrieval task on both MS-COCO and Flickr30k. Moreover, on MS-COCO, it defeats current approaches also on the sentence retrieval task. Given our long-term interest in scalable cross-modal information retrieval, TERAN is designed to keep the visual and textual data pipelines well separated. In fact, cross-attention links invalidate any chance to separately extract visual and textual features needed for the online search and the offline indexing steps in large-scale retrieval systems. In this respect, TERAN merges the information from the two domains only during the final alignment phase, immediately before the loss computation. We argue that the fine-grained alignments produced by TERAN pave the way towards the research for effective and efficient methods for large-scale cross-modal information retrieval. We compare the effectiveness of our approach against the best eight methods in this research area. On the MS-COCO 1K test set, we obtain an improvement of 3.5% and 1.2% respectively on the image and the sentence retrieval tasks on the Recall@1 metric. The code used for the experiments is publicly available on GitHub at https://github.com/mesnico/TERAN.