 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders
Paper and Code
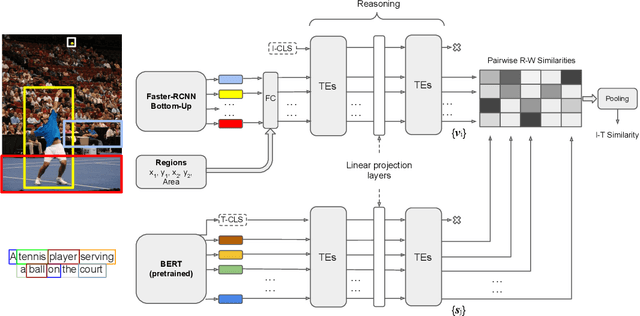
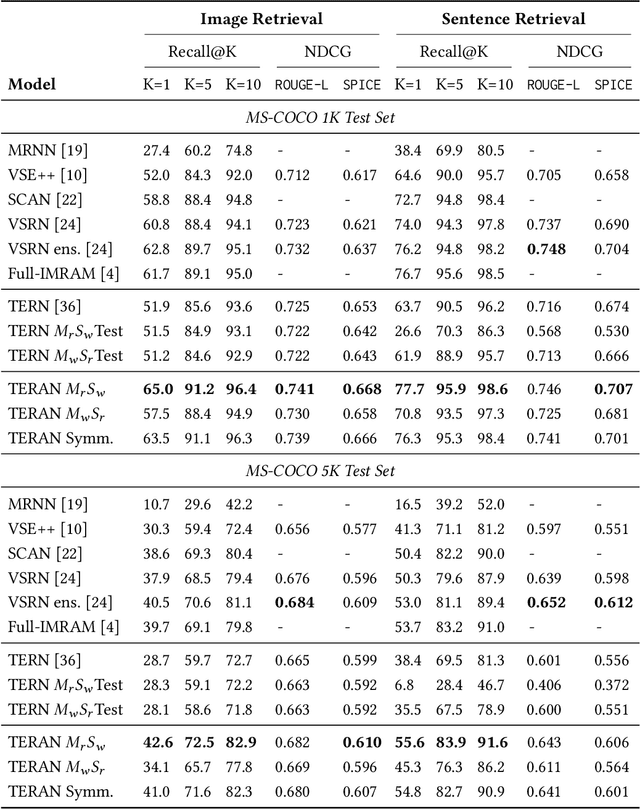
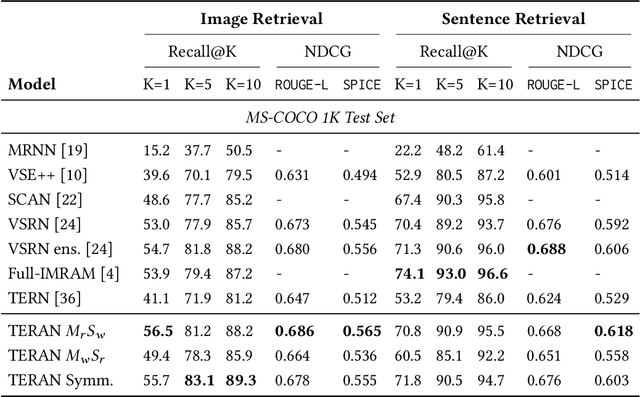

Despite the evolution of deep-learning-based visual-textual processing systems, precise multi-modal matching remains a challenging task. In this work, we tackle the problem of accurate cross-media retrieval through image-sentence matching based on word-region alignments using supervision only at the global image-sentence level. In particular, we present an approach called Transformer Encoder Reasoning and Alignment Network (TERAN). TERAN enforces a fine-grained match between the underlying components of images and sentences, i.e., image regions and words, respectively, in order to preserve the informative richness of both modalities. The proposed approach obtains state-of-the-art results on the image retrieval task on both MS-COCO and Flickr30k. Moreover, on MS-COCO, it defeats current approaches also on the sentence retrieval task. Given our long-term interest in scalable cross-modal information retrieval, TERAN is designed to keep the visual and textual data pipelines well separated. In fact, cross-attention links invalidate any chance to separately extract visual and textual features needed for the online search and the offline indexing steps in large-scale retrieval systems. In this respect, TERAN merges the information from the two domains only during the final alignment phase, immediately before the loss computation. We argue that the fine-grained alignments produced by TERAN pave the way towards the research for effective and efficient methods for large-scale cross-modal information retrieval. We compare the effectiveness of our approach against the best eight methods in this research area. On the MS-COCO 1K test set, we obtain an improvement of 3.5% and 1.2% respectively on the image and the sentence retrieval tasks on the Recall@1 metric. The code used for the experiments is publicly available on GitHub at https://github.com/mesnico/TERAN.