 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Digital Twin in Flood Forecasting with Data Assimilation Satellite Earth Observations -- A Proof-of-Concept in the Alzette Catchment
May 13, 2025Floods pose significant risks to human lives, infrastructure, and the environment. Timely and accurate flood forecasting plays a pivotal role in mitigating these risks. This study presents a proof-of-concept for a Digital Twin framework aimed at improving flood forecasting in the Alzette Catchment, Luxembourg. The approach integrates satellite-based Earth observations, specifically Sentinel-1 flood probability maps, into a particle filter-based data assimilation (DA) process to enhance flood predictions. By combining the GloFAS global flood monitoring and GloFAS streamflow forecasts products with DA using a high-resolution LISFLOOD-FP hydrodynamic model, the Digital Twin can provide daily flood forecasts for up to 30 days with reduced prediction uncertainties. Using the 2021 flood event as a case study, we evaluate the performance of the Digital Twin in assimilating EO data to refine hydraulic model simulations and issue accurate forecasts. While some limitations, such as uncertainties in GloFAS discharge forecasts, remain large, the approach successfully improves forecast accuracy compared to open-loop simulations. Future developments will focus on constructing more adaptively the hazard catalog, and reducing inherent uncertainties related to GloFAS streamflow forecasts and Sentinel-1 flood maps, to further enhance predictive capability. The framework demonstrates potential for advancing real-time flood forecasting and strengthening flood resilience.
Amélioration de la qualité d'images avec un algorithme d'optimisation inspirée par la nature
Mar 13, 2023Reproducible images preprocessing is important in the field of computer vision, for efficient algorithms comparison or for new images corpus preparation. In this paper, we propose a method to obtain an explicit and ordered sequence of transformations that improves a given image: the computation is performed via a nature-inspired optimization algorithm based on quality assessment techniques. Preliminary tests show the impact of the approach on different state-of-the-art data sets. -- L'application de pr\'etraitements explicites et reproductibles est fondamentale dans le domaine de la vision par ordinateur, pour pouvoir comparer efficacement des algorithmes ou pour pr\'eparer un nouveau corpus d'images. Dans cet article, nous proposons une m\'ethode pour obtenir une s\'equence reproductible de transformations qui am\'eliore une image donn\'ee: le calcul est r\'ealis\'e via un algorithme d'optimisation inspir\'ee par la nature et bas\'e sur des techniques d'\'evaluation de la qualit\'e. Des tests montrent l'impact de l'approche sur diff\'erents ensembles d'images de l'\'etat de l'art.
Cold Start Active Learning Strategies in the Context of Imbalanced Classification
Jan 25, 2022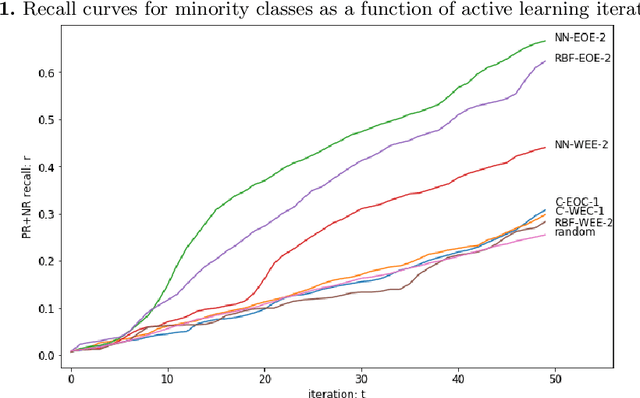
We present novel active learning strategies dedicated to providing a solution to the cold start stage, i.e. initializing the classification of a large set of data with no attached labels. Moreover, proposed strategies are designed to handle an imbalanced context in which random selection is highly inefficient. Specifically, our active learning iterations address label scarcity and imbalance using element scores, combining information extracted from a clustering structure to a label propagation model. The strategy is illustrated by a case study on annotating Twitter content w.r.t. testimonies of a real flood event. We show that our method effectively copes with class imbalance, by boosting the recall of samples from the minority class.
Computing flood probabilities using Twitter: application to the Houston urban area during Harvey
Dec 07, 2020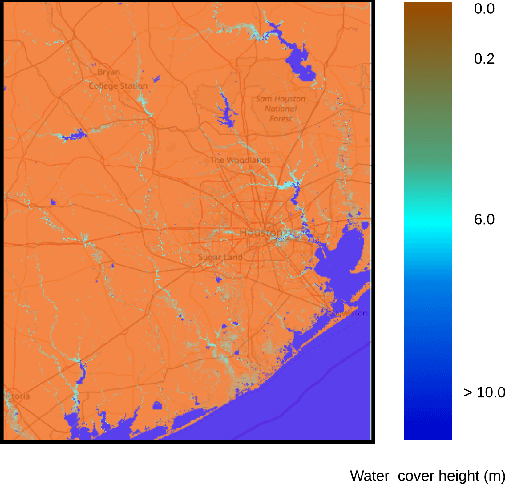
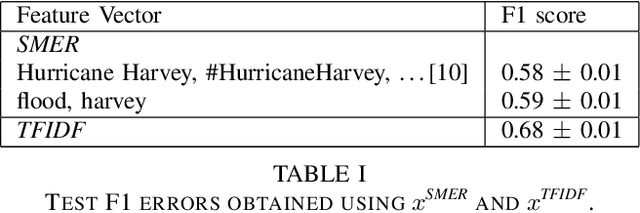
In this paper, we investigate the conversion of a Twitter corpus into geo-referenced raster cells holding the probability of the associated geographical areas of being flooded. We describe a baseline approach that combines a density ratio function, aggregation using a spatio-temporal Gaussian kernel function, and TFIDF textual features. The features are transformed to probabilities using a logistic regression model. The described method is evaluated on a corpus collected after the floods that followed Hurricane Harvey in the Houston urban area in August-September 2017. The baseline reaches a F1 score of 68%. We highlight research directions likely to improve these initial results.