 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold Start Active Learning Strategies in the Context of Imbalanced Classification
Jan 25, 2022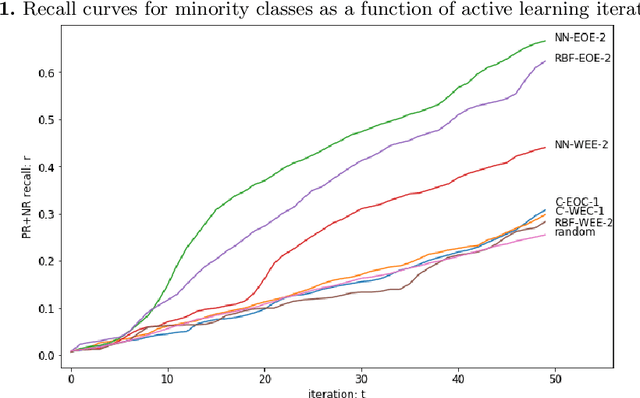
We present novel active learning strategies dedicated to providing a solution to the cold start stage, i.e. initializing the classification of a large set of data with no attached labels. Moreover, proposed strategies are designed to handle an imbalanced context in which random selection is highly inefficient. Specifically, our active learning iterations address label scarcity and imbalance using element scores, combining information extracted from a clustering structure to a label propagation model. The strategy is illustrated by a case study on annotating Twitter content w.r.t. testimonies of a real flood event. We show that our method effectively copes with class imbalance, by boosting the recall of samples from the minority class.
Computing flood probabilities using Twitter: application to the Houston urban area during Harvey
Dec 07, 2020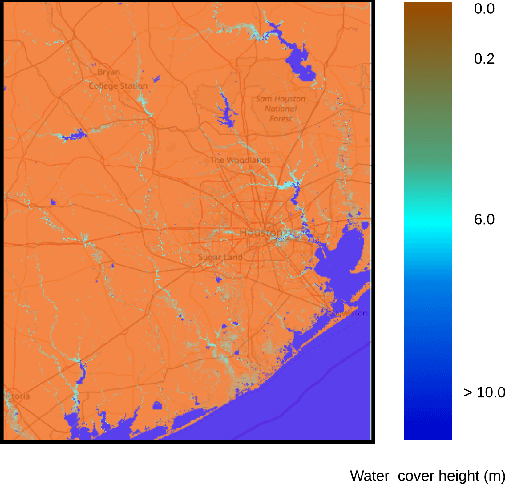
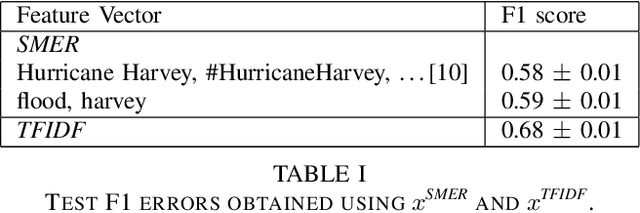
In this paper, we investigate the conversion of a Twitter corpus into geo-referenced raster cells holding the probability of the associated geographical areas of being flooded. We describe a baseline approach that combines a density ratio function, aggregation using a spatio-temporal Gaussian kernel function, and TFIDF textual features. The features are transformed to probabilities using a logistic regression model. The described method is evaluated on a corpus collected after the floods that followed Hurricane Harvey in the Houston urban area in August-September 2017. The baseline reaches a F1 score of 68%. We highlight research directions likely to improve these initial results.