 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Cross-Modal Visual Textual Retrieval using Transformer-Encoder Deep Features
Paper and Code
Jun 01, 2021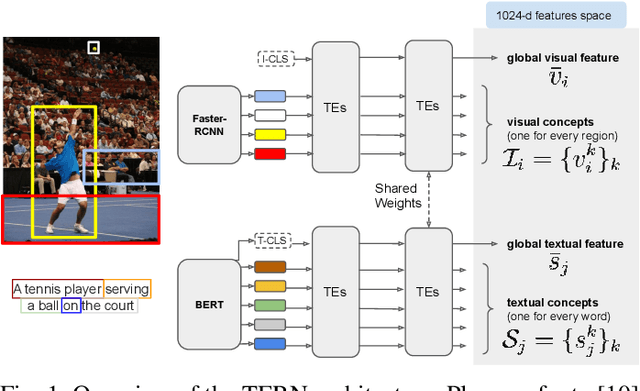
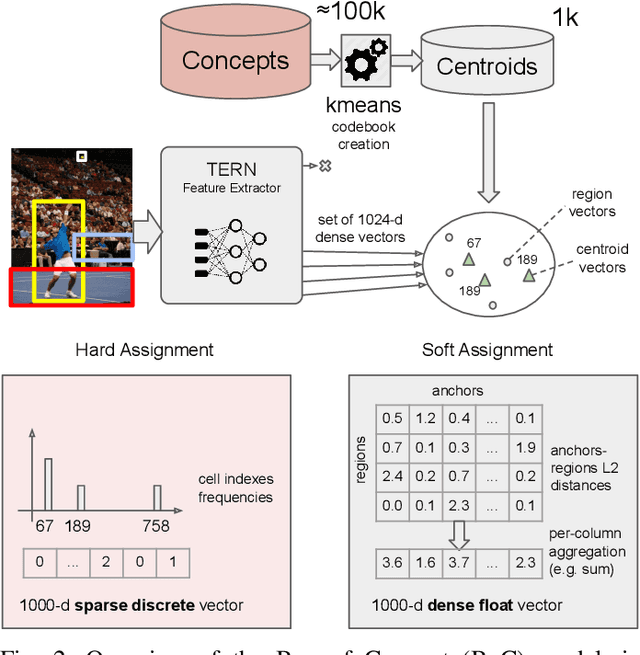
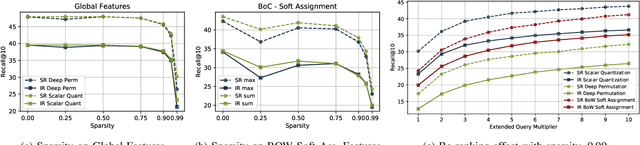
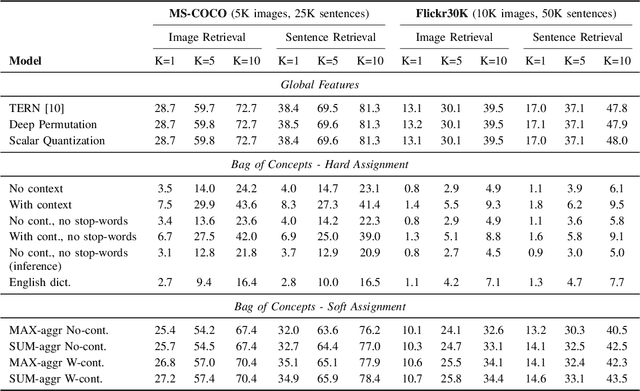
Cross-modal retrieval is an important functionality in modern search engines, as it increases the user experience by allowing queries and retrieved objects to pertain to different modalities. In this paper, we focus on the image-sentence retrieval task, where the objective is to efficiently find relevant images for a given sentence (image-retrieval) or the relevant sentences for a given image (sentence-retrieval). Computer vision literature reports the best results on the image-sentence matching task using deep neural networks equipped with attention and self-attention mechanisms. They evaluate the matching performance on the retrieval task by performing sequential scans of the whole dataset. This method does not scale well with an increasing amount of images or captions. In this work, we explore different preprocessing techniques to produce sparsified deep multi-modal features extracting them from state-of-the-art deep-learning architectures for image-text matching. Our main objective is to lay down the paths for efficient indexing of complex multi-modal descriptions. We use the recently introduced TERN architecture as an image-sentence features extractor. It is designed for producing fixed-size 1024-d vectors describing whole images and sentences, as well as variable-length sets of 1024-d vectors describing the various building components of the two modalities (image regions and sentence words respectively). All these vectors are enforced by the TERN design to lie into the same common space. Our experiments show interesting preliminary results on the explored methods and suggest further experimentation in this important research direction.