Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Nonlinear Variable Selection via Kernel Random Features
Paper and Code

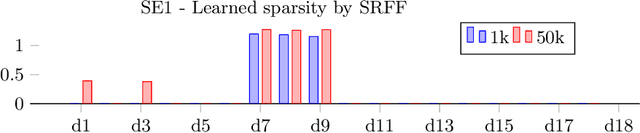
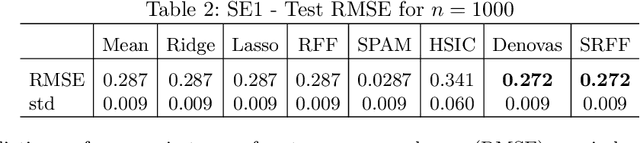
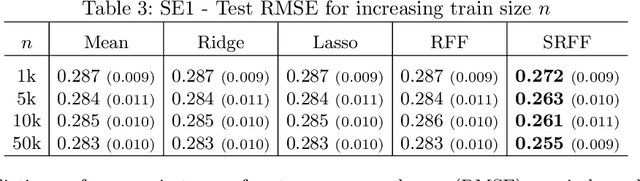
We propose a new method for input variable selection in nonlinear regression. The method is embedded into a kernel regression machine that can model general nonlinear functions, not being a priori limited to additive models. This is the first kernel-based variable selection method applicable to large datasets. It sidesteps the typical poor scaling properties of kernel methods by mapping the inputs into a relatively low-dimensional space of random features. The algorithm discovers the variables relevant for the regression task together with learning the prediction model through learning the appropriate nonlinear random feature maps. We demonstrate the outstanding performance of our method on a set of large-scale synthetic and real datasets.
* Final version for proceedings of ECML/PKDD 2018
View paper on