 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-sourced Data Ecosystem in Autonomous Driving: the Present and Future
Dec 06, 2023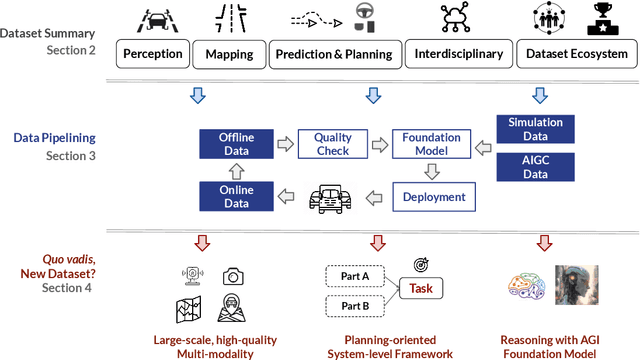
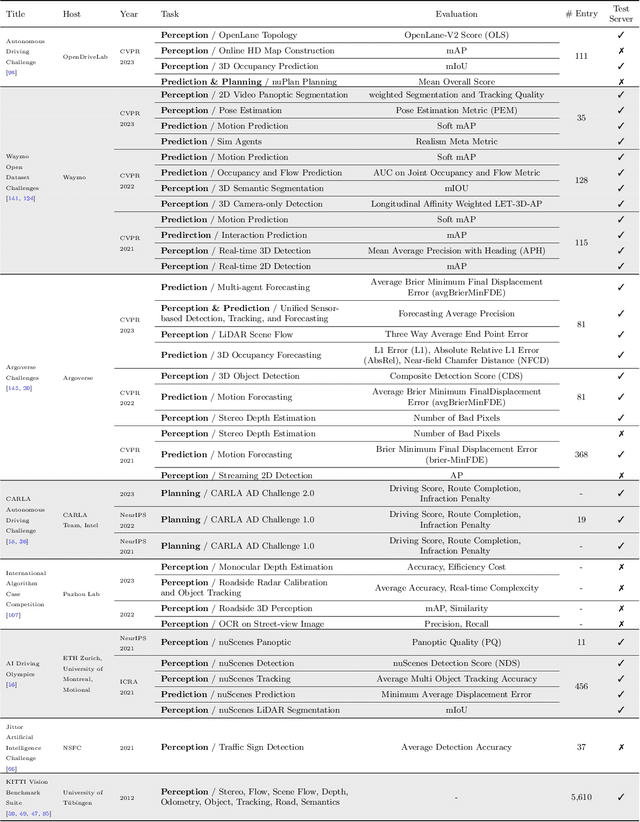
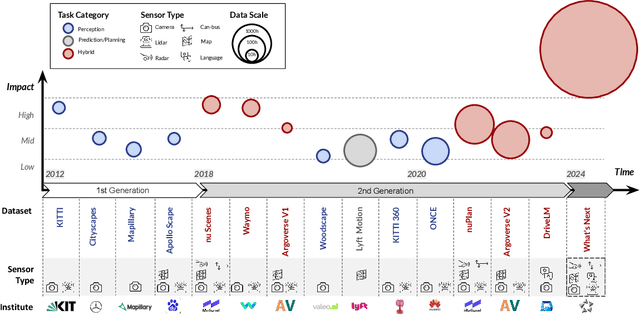
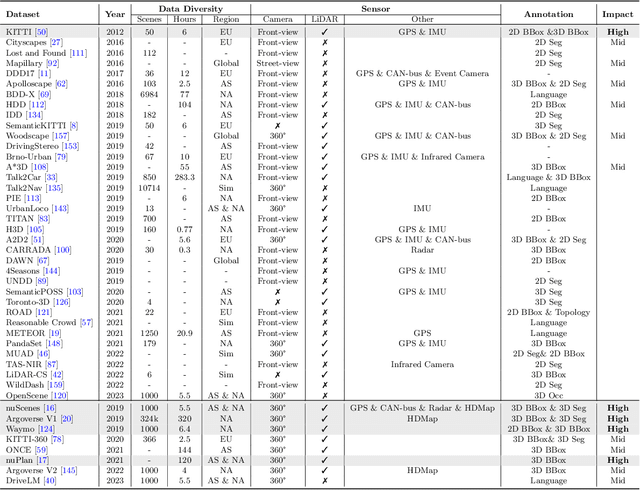
With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem. Current autonomous driving datasets can broadly be categorized into two generations. The first-generation autonomous driving datasets are characterized by relatively simpler sensor modalities, smaller data scale, and is limited to perception-level tasks. KITTI, introduced in 2012, serves as a prominent representative of this initial wave. In contrast, the second-generation datasets exhibit heightened complexity in sensor modalities, greater data scale and diversity, and an expansion of tasks from perception to encompass prediction and control. Leading examples of the second generation include nuScenes and Waymo, introduced around 2019. This comprehensive review, conducted in collaboration with esteemed colleagues from both academia and industry, systematically assesses over seventy open-source autonomous driving datasets from domestic and international sources. It offers insights into various aspects, such as the principles underlying the creation of high-quality datasets, the pivotal role of data engine systems, and the utilization of generative foundation models to facilitate scalable data generation. Furthermore, this review undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess. It also delves into the scientific and technical challenges that warrant resolution. These endeavors are pivotal in advancing autonomous innovation and fostering technological enhancement in critical domains. For further details, please refer to https://github.com/OpenDriveLab/DriveAGI.
Object Detection Networks on Convolutional Feature Maps
Aug 17, 2016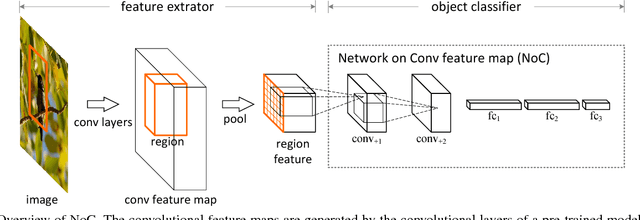

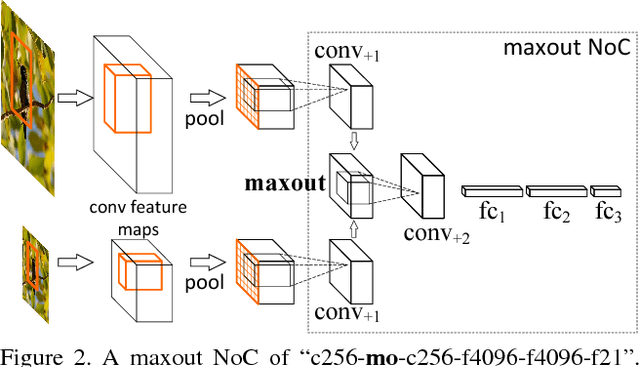
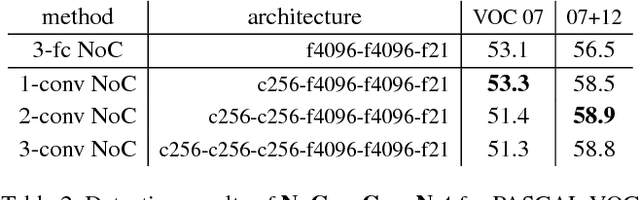
Most object detectors contain two important components: a feature extractor and an object classifier. The feature extractor has rapidly evolved with significant research efforts leading to better deep convolutional architectures. The object classifier, however, has not received much attention and many recent systems (like SPPnet and Fast/Faster R-CNN) use simple multi-layer perceptrons. This paper demonstrates that carefully designing deep networks for object classification is just as important. We experiment with region-wise classifier networks that use shared, region-independent convolutional features. We call them "Networks on Convolutional feature maps" (NoCs). We discover that aside from deep feature maps, a deep and convolutional per-region classifier is of particular importance for object detection, whereas latest superior image classification models (such as ResNets and GoogLeNets) do not directly lead to good detection accuracy without using such a per-region classifier. We show by experiments that despite the effective ResNets and Faster R-CNN systems, the design of NoCs is an essential element for the 1st-place winning entries in ImageNet and MS COCO challenges 2015.
Identity Mappings in Deep Residual Networks
Jul 25, 2016


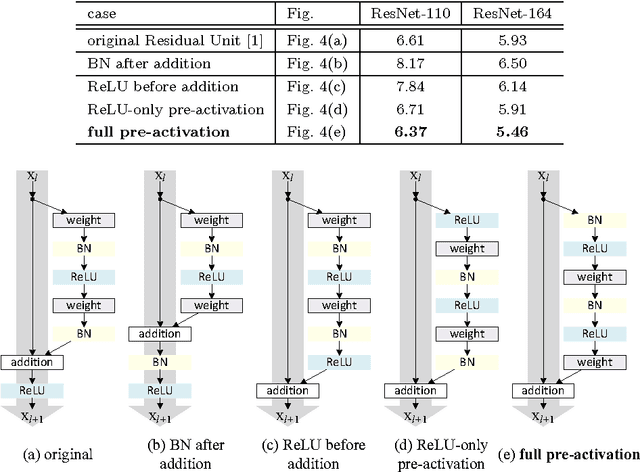
Deep residual networks have emerged as a family of extremely deep architectures showing compelling accuracy and nice convergence behaviors. In this paper, we analyze the propagation formulations behind the residual building blocks, which suggest that the forward and backward signals can be directly propagated from one block to any other block, when using identity mappings as the skip connections and after-addition activation. A series of ablation experiments support the importance of these identity mappings. This motivates us to propose a new residual unit, which makes training easier and improves generalization. We report improved results using a 1001-layer ResNet on CIFAR-10 (4.62% error) and CIFAR-100, and a 200-layer ResNet on ImageNet. Code is available at: https://github.com/KaimingHe/resnet-1k-layers
Instance-sensitive Fully Convolutional Networks
Mar 29, 2016
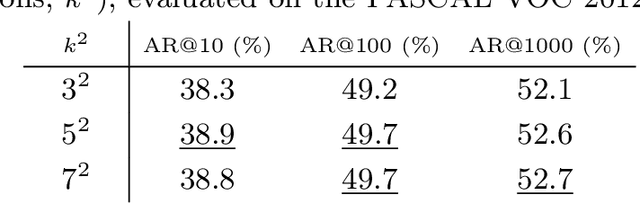
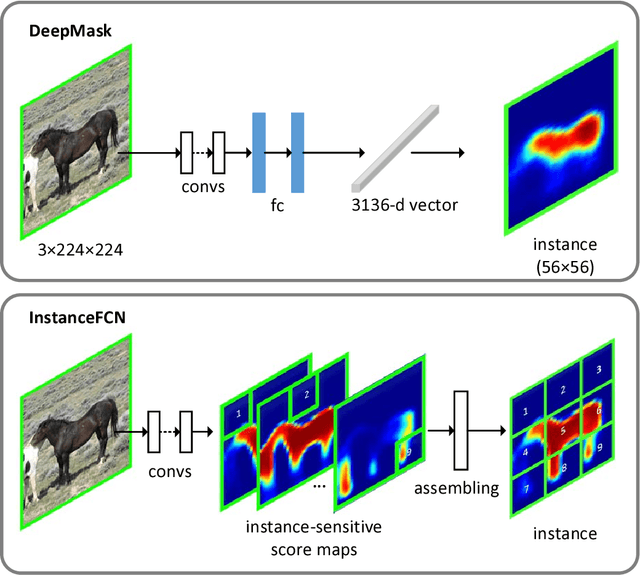

Fully convolutional networks (FCNs) have been proven very successful for semantic segmentation, but the FCN outputs are unaware of object instances. In this paper, we develop FCNs that are capable of proposing instance-level segment candidates. In contrast to the previous FCN that generates one score map, our FCN is designed to compute a small set of instance-sensitive score maps, each of which is the outcome of a pixel-wise classifier of a relative position to instances. On top of these instance-sensitive score maps, a simple assembling module is able to output instance candidate at each position. In contrast to the recent DeepMask method for segmenting instances, our method does not have any high-dimensional layer related to the mask resolution, but instead exploits image local coherence for estimating instances. We present competitive results of instance segment proposal on both PASCAL VOC and MS COCO.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Jan 06, 2016



State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features---using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model, our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available.
Deep Residual Learning for Image Recognition
Dec 10, 2015



Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Apr 23, 2015



Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, "spatial pyramid pooling", to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning. The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102x faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007. In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Feb 06, 2015

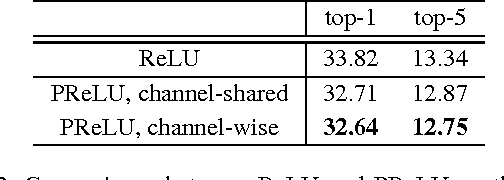
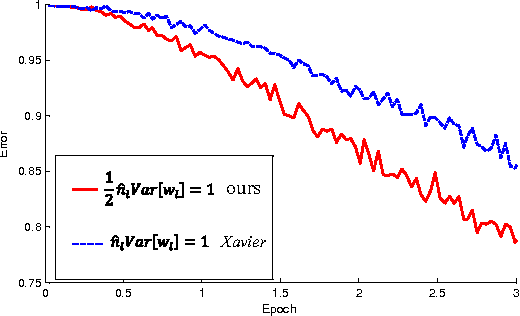
Rectified activation units (rectifiers) are essential for state-of-the-art neural networks. In this work, we study rectifier neural networks for image classification from two aspects. First, we propose a Parametric Rectified Linear Unit (PReLU) that generalizes the traditional rectified unit. PReLU improves model fitting with nearly zero extra computational cost and little overfitting risk. Second, we derive a robust initialization method that particularly considers the rectifier nonlinearities. This method enables us to train extremely deep rectified models directly from scratch and to investigate deeper or wider network architectures. Based on our PReLU networks (PReLU-nets), we achieve 4.94% top-5 test error on the ImageNet 2012 classification dataset. This is a 26% relative improvement over the ILSVRC 2014 winner (GoogLeNet, 6.66%). To our knowledge, our result is the first to surpass human-level performance (5.1%, Russakovsky et al.) on this visual recognition challenge.