 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025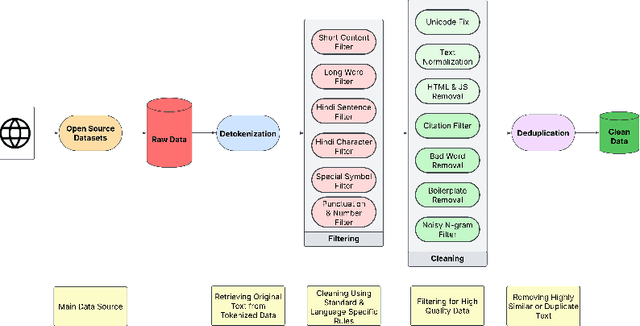

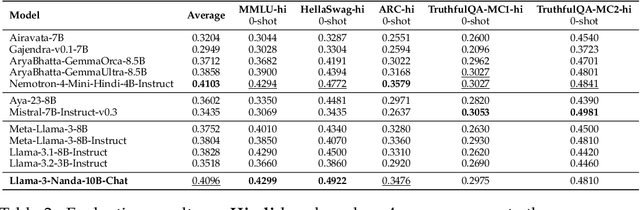

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Graph Neural Network Enhanced Language Models for Efficient Multilingual Text Classification
Mar 06, 2022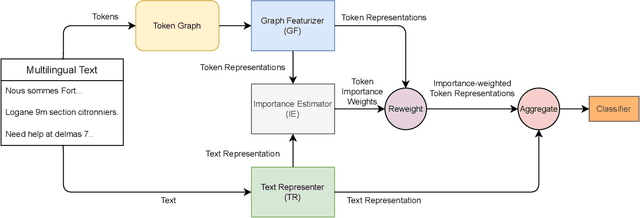
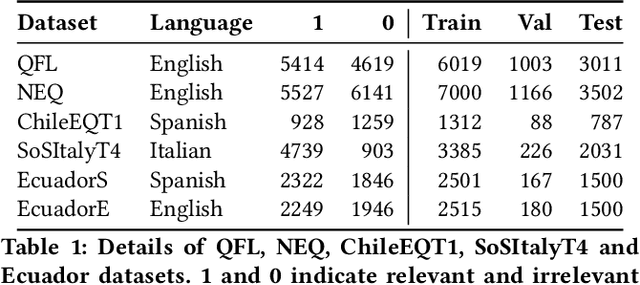

Online social media works as a source of various valuable and actionable information during disasters. These information might be available in multiple languages due to the nature of user generated content. An effective system to automatically identify and categorize these actionable information should be capable to handle multiple languages and under limited supervision. However, existing works mostly focus on English language only with the assumption that sufficient labeled data is available. To overcome these challenges, we propose a multilingual disaster related text classification system which is capable to work under \{mono, cross and multi\} lingual scenarios and under limited supervision. Our end-to-end trainable framework combines the versatility of graph neural networks, by applying over the corpus, with the power of transformer based large language models, over examples, with the help of cross-attention between the two. We evaluate our framework over total nine English, Non-English and monolingual datasets in \{mono, cross and multi\} lingual classification scenarios. Our framework outperforms state-of-the-art models in disaster domain and multilingual BERT baseline in terms of Weighted F$_1$ score. We also show the generalizability of the proposed model under limited supervision.
Supervised Graph Contrastive Pretraining for Text Classification
Dec 21, 2021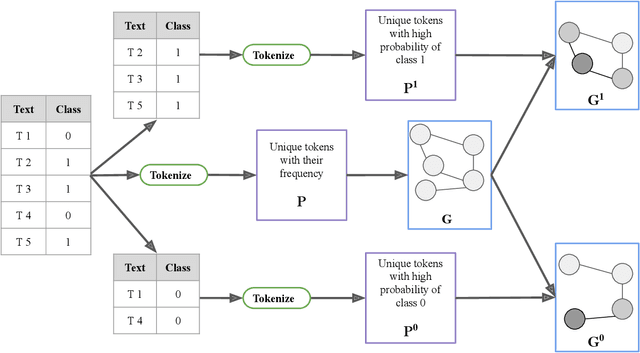
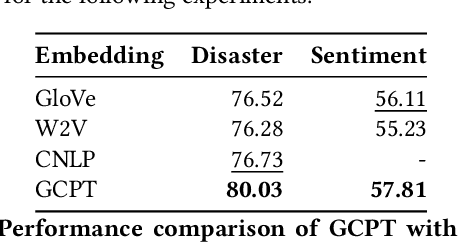
Contrastive pretraining techniques for text classification has been largely studied in an unsupervised setting. However, oftentimes labeled data from related tasks which share label semantics with current task is available. We hypothesize that using this labeled data effectively can lead to better generalization on current task. In this paper, we propose a novel way to effectively utilize labeled data from related tasks with a graph based supervised contrastive learning approach. We formulate a token-graph by extrapolating the supervised information from examples to tokens. Our formulation results in an embedding space where tokens with high/low probability of belonging to same class are near/further-away from one another. We also develop detailed theoretical insights which serve as a motivation for our method. In our experiments with $13$ datasets, we show our method outperforms pretraining schemes by $2.5\%$ and also example-level contrastive learning based formulation by $1.8\%$ on average. In addition, we show cross-domain effectiveness of our method in a zero-shot setting by $3.91\%$ on average. Lastly, we also demonstrate our method can be used as a noisy teacher in a knowledge distillation setting to significantly improve performance of transformer based models in low labeled data regime by $4.57\%$ on average.
Unsupervised Domain Adaptation with Global and Local Graph Neural Networks in Limited Labeled Data Scenario: Application to Disaster Management
Apr 03, 2021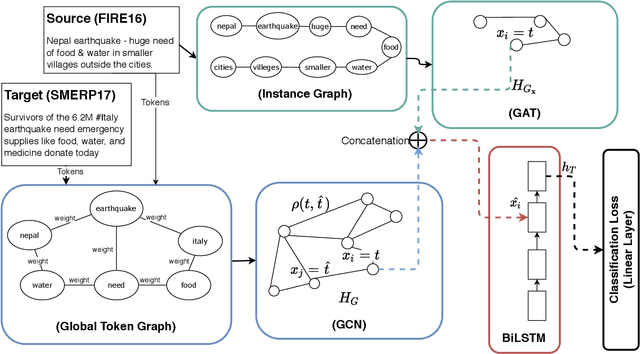
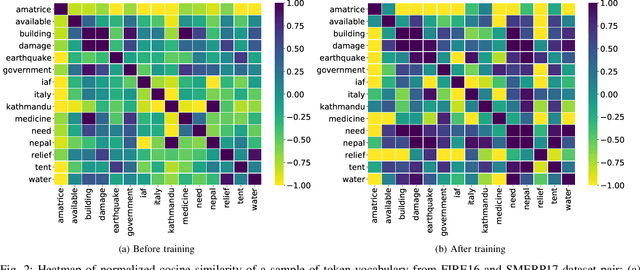
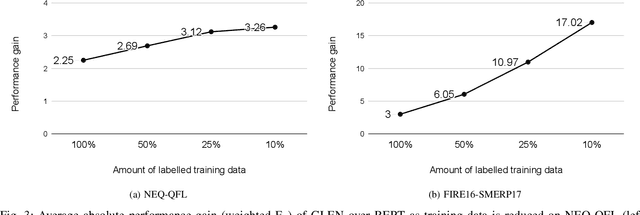

Identification and categorization of social media posts generated during disasters are crucial to reduce the sufferings of the affected people. However, lack of labeled data is a significant bottleneck in learning an effective categorization system for a disaster. This motivates us to study the problem as unsupervised domain adaptation (UDA) between a previous disaster with labeled data (source) and a current disaster (target). However, if the amount of labeled data available is limited, it restricts the learning capabilities of the model. To handle this challenge, we utilize limited labeled data along with abundantly available unlabeled data, generated during a source disaster to propose a novel two-part graph neural network. The first-part extracts domain-agnostic global information by constructing a token level graph across domains and the second-part preserves local instance-level semantics. In our experiments, we show that the proposed method outperforms state-of-the-art techniques by $2.74\%$ weighted F$_1$ score on average on two standard public dataset in the area of disaster management. We also report experimental results for granular actionable multi-label classification datasets in disaster domain for the first time, on which we outperform BERT by $3.00\%$ on average w.r.t weighted F$_1$. Additionally, we show that our approach can retain performance when very limited labeled data is available.