 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network Enhanced Language Models for Efficient Multilingual Text Classification
Paper and Code
Mar 06, 2022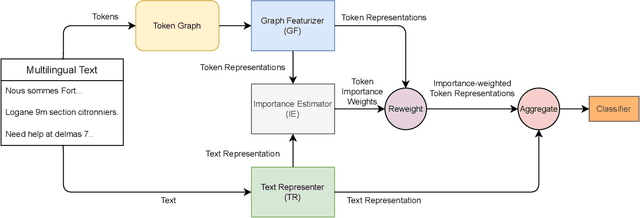
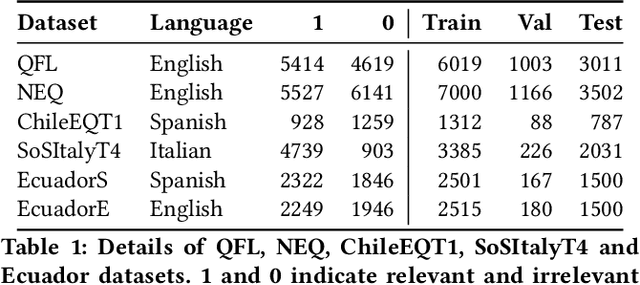
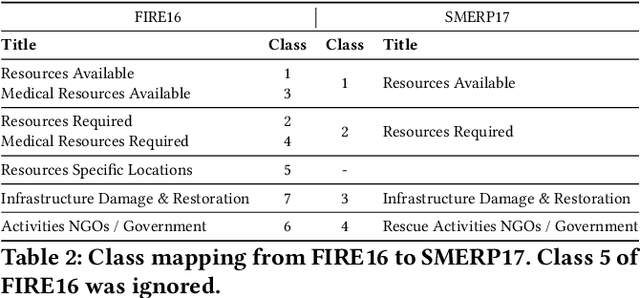

Online social media works as a source of various valuable and actionable information during disasters. These information might be available in multiple languages due to the nature of user generated content. An effective system to automatically identify and categorize these actionable information should be capable to handle multiple languages and under limited supervision. However, existing works mostly focus on English language only with the assumption that sufficient labeled data is available. To overcome these challenges, we propose a multilingual disaster related text classification system which is capable to work under \{mono, cross and multi\} lingual scenarios and under limited supervision. Our end-to-end trainable framework combines the versatility of graph neural networks, by applying over the corpus, with the power of transformer based large language models, over examples, with the help of cross-attention between the two. We evaluate our framework over total nine English, Non-English and monolingual datasets in \{mono, cross and multi\} lingual classification scenarios. Our framework outperforms state-of-the-art models in disaster domain and multilingual BERT baseline in terms of Weighted F$_1$ score. We also show the generalizability of the proposed model under limited supervision.