 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDinoBloom: A Foundation Model for Generalizable Cell Embeddings in Hematology
Apr 07, 2024In hematology, computational models offer significant potential to improve diagnostic accuracy, streamline workflows, and reduce the tedious work of analyzing single cells in peripheral blood or bone marrow smears. However, clinical adoption of computational models has been hampered by the lack of generalization due to large batch effects, small dataset sizes, and poor performance in transfer learning from natural images. To address these challenges, we introduce DinoBloom, the first foundation model for single cell images in hematology, utilizing a tailored DINOv2 pipeline. Our model is built upon an extensive collection of 13 diverse, publicly available datasets of peripheral blood and bone marrow smears, the most substantial open-source cohort in hematology so far, comprising over 380,000 white blood cell images. To assess its generalization capability, we evaluate it on an external dataset with a challenging domain shift. We show that our model outperforms existing medical and non-medical vision models in (i) linear probing and k-nearest neighbor evaluations for cell-type classification on blood and bone marrow smears and (ii) weakly supervised multiple instance learning for acute myeloid leukemia subtyping by a large margin. A family of four DinoBloom models (small, base, large, and giant) can be adapted for a wide range of downstream applications, be a strong baseline for classification problems, and facilitate the assessment of batch effects in new datasets. All models are available at github.com/marrlab/DinoBloom.
Self-Supervised Multiple Instance Learning for Acute Myeloid Leukemia Classification
Mar 08, 2024



Automated disease diagnosis using medical image analysis relies on deep learning, often requiring large labeled datasets for supervised model training. Diseases like Acute Myeloid Leukemia (AML) pose challenges due to scarce and costly annotations on a single-cell level. Multiple Instance Learning (MIL) addresses weakly labeled scenarios but necessitates powerful encoders typically trained with labeled data. In this study, we explore Self-Supervised Learning (SSL) as a pre-training approach for MIL-based AML subtype classification from blood smears, removing the need for labeled data during encoder training. We investigate the three state-of-the-art SSL methods SimCLR, SwAV, and DINO, and compare their performance against supervised pre-training. Our findings show that SSL-pretrained encoders achieve comparable performance, showcasing the potential of SSL in MIL. This breakthrough offers a cost-effective and data-efficient solution, propelling the field of AI-based disease diagnosis.
Topologically-Regularized Multiple Instance Learning for Red Blood Cell Disease Classification
Jul 26, 2023Diagnosing rare anemia disorders using microscopic images is challenging for skilled specialists and machine-learning methods alike. Due to thousands of disease-relevant cells in a single blood sample, this constitutes a complex multiple-instance learning (MIL) problem. While the spatial neighborhood of red blood cells is not meaningful per se, the topology, i.e., the geometry of blood samples as a whole, contains informative features to remedy typical MIL issues, such as vanishing gradients and overfitting when training on limited data. We thus develop a topology-based approach that extracts multi-scale topological features from bags of single red blood cell images. The topological features are used to regularize the model, enforcing the preservation of characteristic topological properties of the data. Applied to a dataset of 71 patients suffering from rare anemia disorders with 521 microscopic images of red blood cells, our experiments show that topological regularization is an effective method that leads to more than 3% performance improvements for the automated classification of rare anemia disorders based on single-cell images. This is the first approach that uses topological properties for regularizing the MIL process.
Anomaly-aware multiple instance learning for rare anemia disorder classification
Jul 04, 2022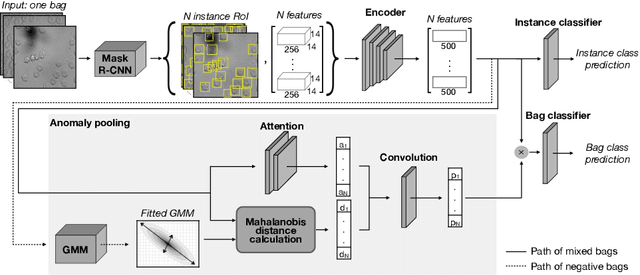

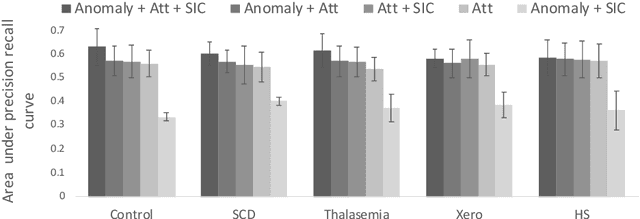
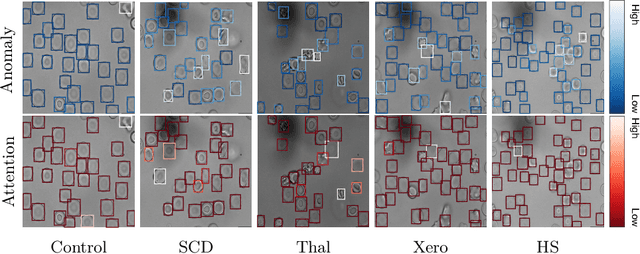
Deep learning-based classification of rare anemia disorders is challenged by the lack of training data and instance-level annotations. Multiple Instance Learning (MIL) has shown to be an effective solution, yet it suffers from low accuracy and limited explainability. Although the inclusion of attention mechanisms has addressed these issues, their effectiveness highly depends on the amount and diversity of cells in the training samples. Consequently, the poor machine learning performance on rare anemia disorder classification from blood samples remains unresolved. In this paper, we propose an interpretable pooling method for MIL to address these limitations. By benefiting from instance-level information of negative bags (i.e., homogeneous benign cells from healthy individuals), our approach increases the contribution of anomalous instances. We show that our strategy outperforms standard MIL classification algorithms and provides a meaningful explanation behind its decisions. Moreover, it can denote anomalous instances of rare blood diseases that are not seen during the training phase.
GANs for Medical Image Analysis
Sep 13, 2018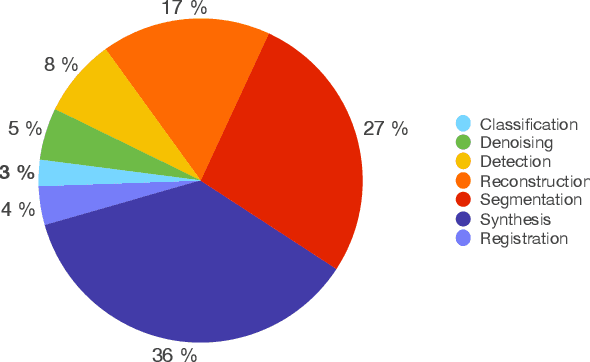
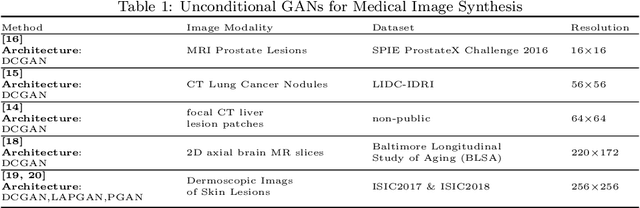
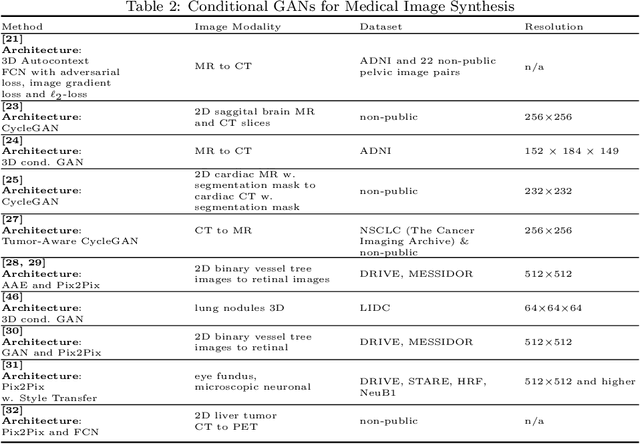
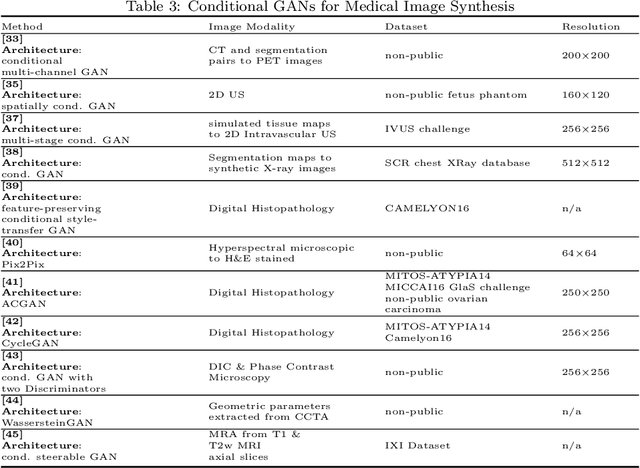
Generative Adversarial Networks (GANs) and their extensions have carved open many exciting ways to tackle well known and challenging medical image analysis problems such as medical image denoising, reconstruction, segmentation, data simulation, detection or classification. Furthermore, their ability to synthesize images at unprecedented levels of realism also gives hope that the chronic scarcity of labeled data in the medical field can be resolved with the help of these generative models. In this review paper, a broad overview of recent literature on GANs for medical applications is given, the shortcomings and opportunities of the proposed methods are thoroughly discussed and potential future work is elaborated. A total of 63 papers published until end of July 2018 are reviewed. For quick access, the papers and important details such as the underlying method, datasets and performance are summarized in tables.