 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
Delta Knowledge Distillation for Large Language Models
Sep 18, 2025Knowledge distillation (KD) is a widely adopted approach for compressing large neural networks by transferring knowledge from a large teacher model to a smaller student model. In the context of large language models, token level KD, typically minimizing the KL divergence between student output distribution and teacher output distribution, has shown strong empirical performance. However, prior work assumes student output distribution and teacher output distribution share the same optimal representation space, a premise that may not hold in many cases. To solve this problem, we propose Delta Knowledge Distillation (Delta-KD), a novel extension of token level KD that encourages the student to approximate an optimal representation space by explicitly preserving the distributional shift Delta introduced during the teacher's supervised finetuning (SFT). Empirical results on ROUGE metrics demonstrate that Delta KD substantially improves student performance while preserving more of the teacher's knowledge.
On neural and dimensional collapse in supervised and unsupervised contrastive learning with hard negative sampling
Nov 09, 2023

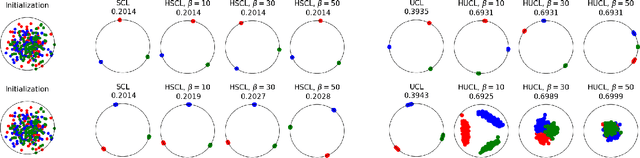
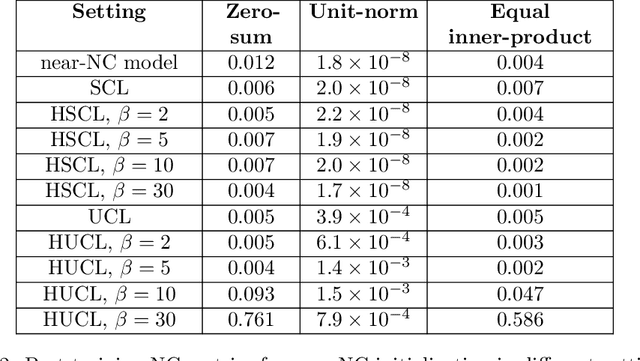
For a widely-studied data model and general loss and sample-hardening functions we prove that the Supervised Contrastive Learning (SCL), Hard-SCL (HSCL), and Unsupervised Contrastive Learning (UCL) risks are minimized by representations that exhibit Neural Collapse (NC), i.e., the class means form an Equianglular Tight Frame (ETF) and data from the same class are mapped to the same representation. We also prove that for any representation mapping, the HSCL and Hard-UCL (HUCL) risks are lower bounded by the corresponding SCL and UCL risks. Although the optimality of ETF is known for SCL, albeit only for InfoNCE loss, its optimality for HSCL and UCL under general loss and hardening functions is novel. Moreover, our proofs are much simpler, compact, and transparent. We empirically demonstrate, for the first time, that ADAM optimization of HSCL and HUCL risks with random initialization and suitable hardness levels can indeed converge to the NC geometry if we incorporate unit-ball or unit-sphere feature normalization. Without incorporating hard negatives or feature normalization, however, the representations learned via ADAM suffer from dimensional collapse (DC) and fail to attain the NC geometry.
Accuracy versus time frontiers of semi-supervised and self-supervised learning on medical images
Jul 18, 2023
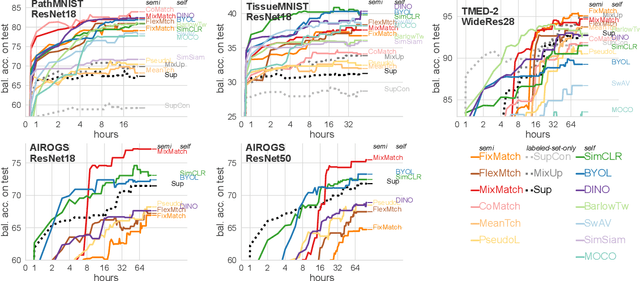
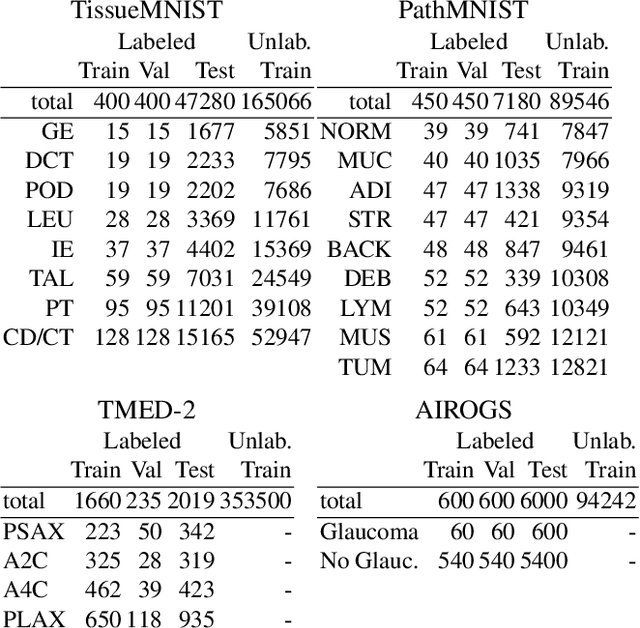
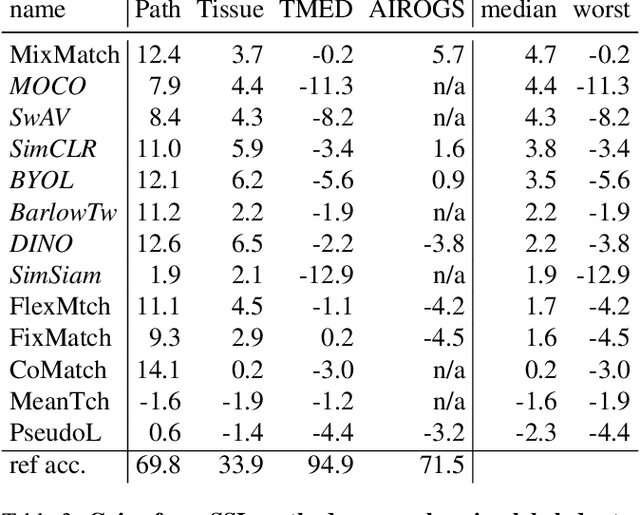
For many applications of classifiers to medical images, a trustworthy label for each image can be difficult or expensive to obtain. In contrast, images without labels are more readily available. Two major research directions both promise that additional unlabeled data can improve classifier performance: self-supervised learning pretrains useful representations on unlabeled data only, then fine-tunes a classifier on these representations via the labeled set; semi-supervised learning directly trains a classifier on labeled and unlabeled data simultaneously. Recent methods from both directions have claimed significant gains on non-medical tasks, but do not systematically assess medical images and mostly compare only to methods in the same direction. This study contributes a carefully-designed benchmark to help answer a practitioner's key question: given a small labeled dataset and a limited budget of hours to spend on training, what gains from additional unlabeled images are possible and which methods best achieve them? Unlike previous benchmarks, ours uses realistic-sized validation sets to select hyperparameters, assesses runtime-performance tradeoffs, and bridges two research fields. By comparing 6 semi-supervised methods and 5 self-supervised methods to strong labeled-only baselines on 3 medical datasets with 30-1000 labels per class, we offer insights to resource-constrained, results-focused practitioners: MixMatch, SimCLR, and BYOL represent strong choices that were not surpassed by more recent methods. After much effort selecting hyperparameters on one dataset, we publish settings that enable strong methods to perform well on new medical tasks within a few hours, with further search over dozens of hours delivering modest additional gains.
Measure Estimation in the Barycentric Coding Model
Jan 28, 2022

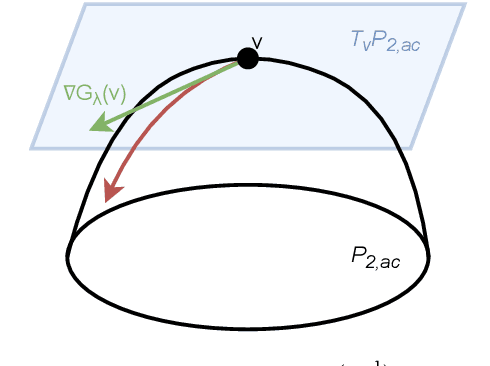
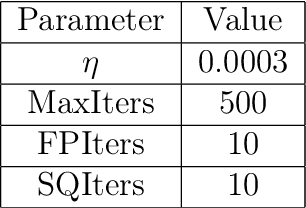
This paper considers the problem of measure estimation under the barycentric coding model (BCM), in which an unknown measure is assumed to belong to the set of Wasserstein-2 barycenters of a finite set of known measures. Estimating a measure under this model is equivalent to estimating the unknown barycenteric coordinates. We provide novel geometrical, statistical, and computational insights for measure estimation under the BCM, consisting of three main results. Our first main result leverages the Riemannian geometry of Wasserstein-2 space to provide a procedure for recovering the barycentric coordinates as the solution to a quadratic optimization problem assuming access to the true reference measures. The essential geometric insight is that the parameters of this quadratic problem are determined by inner products between the optimal displacement maps from the given measure to the reference measures defining the BCM. Our second main result then establishes an algorithm for solving for the coordinates in the BCM when all the measures are observed empirically via i.i.d. samples. We prove precise rates of convergence for this algorithm -- determined by the smoothness of the underlying measures and their dimensionality -- thereby guaranteeing its statistical consistency. Finally, we demonstrate the utility of the BCM and associated estimation procedures in three application areas: (i) covariance estimation for Gaussian measures; (ii) image processing; and (iii) natural language processing.
Hard Negative Sampling via Regularized Optimal Transport for Contrastive Representation Learning
Nov 04, 2021



We study the problem of designing hard negative sampling distributions for unsupervised contrastive representation learning. We analyze a novel min-max framework that seeks a representation which minimizes the maximum (worst-case) generalized contrastive learning loss over all couplings (joint distributions between positive and negative samples subject to marginal constraints) and prove that the resulting min-max optimum representation will be degenerate. This provides the first theoretical justification for incorporating additional regularization constraints on the couplings. We re-interpret the min-max problem through the lens of Optimal Transport theory and utilize regularized transport couplings to control the degree of hardness of negative examples. We demonstrate that the state-of-the-art hard negative sampling distributions that were recently proposed are a special case corresponding to entropic regularization of the coupling.
Interpretable contrastive word mover's embedding
Nov 01, 2021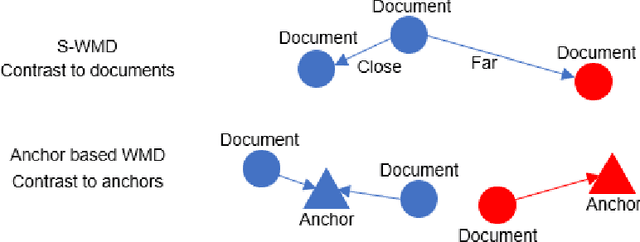
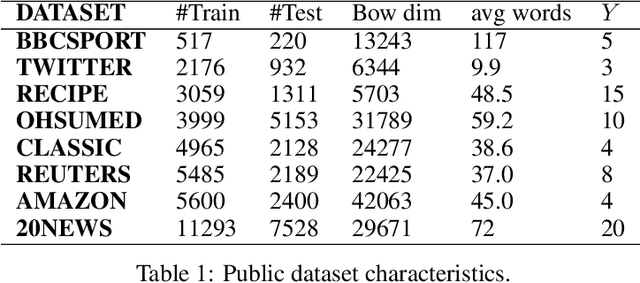

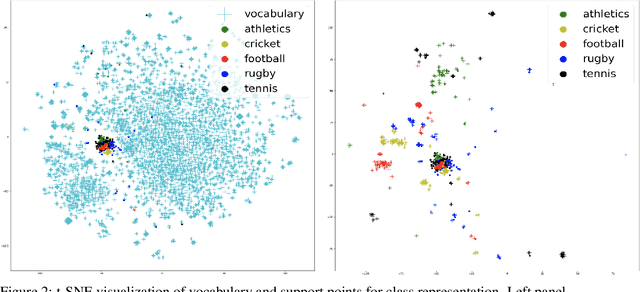
This paper shows that a popular approach to the supervised embedding of documents for classification, namely, contrastive Word Mover's Embedding, can be significantly enhanced by adding interpretability. This interpretability is achieved by incorporating a clustering promoting mechanism into the contrastive loss. On several public datasets, we show that our method improves significantly upon existing baselines while providing interpretation to the clusters via identifying a set of keywords that are the most representative of a particular class. Our approach was motivated in part by the need to develop Natural Language Processing (NLP) methods for the \textit{novel problem of assessing student work for scientific writing and thinking} - a problem that is central to the area of (educational) Learning Sciences (LS). In this context, we show that our approach leads to a meaningful assessment of the student work related to lab reports from a biology class and can help LS researchers gain insights into student understanding and assess evidence of scientific thought processes.
Automatic coding of students' writing via Contrastive Representation Learning in the Wasserstein space
Dec 01, 2020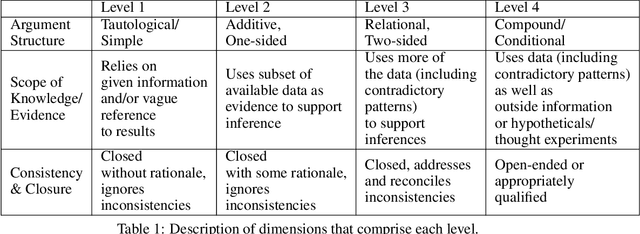

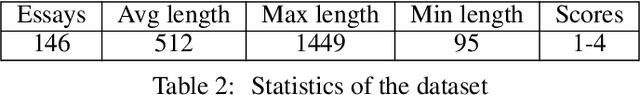
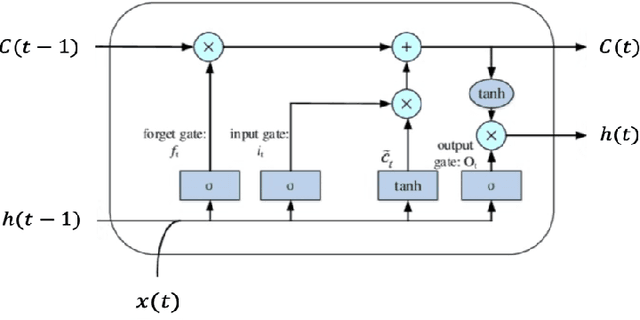
Qualitative analysis of verbal data is of central importance in the learning sciences. It is labor-intensive and time-consuming, however, which limits the amount of data researchers can include in studies. This work is a step towards building a statistical machine learning (ML) method for achieving an automated support for qualitative analyses of students' writing, here specifically in score laboratory reports in introductory biology for sophistication of argumentation and reasoning. We start with a set of lab reports from an undergraduate biology course, scored by a four-level scheme that considers the complexity of argument structure, the scope of evidence, and the care and nuance of conclusions. Using this set of labeled data, we show that a popular natural language modeling processing pipeline, namely vector representation of words, a.k.a word embeddings, followed by Long Short Term Memory (LSTM) model for capturing language generation as a state-space model, is able to quantitatively capture the scoring, with a high Quadratic Weighted Kappa (QWK) prediction score, when trained in via a novel contrastive learning set-up. We show that the ML algorithm approached the inter-rater reliability of human analysis. Ultimately, we conclude, that machine learning (ML) for natural language processing (NLP) holds promise for assisting learning sciences researchers in conducting qualitative studies at much larger scales than is currently possible.