 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy versus time frontiers of semi-supervised and self-supervised learning on medical images
Paper and Code

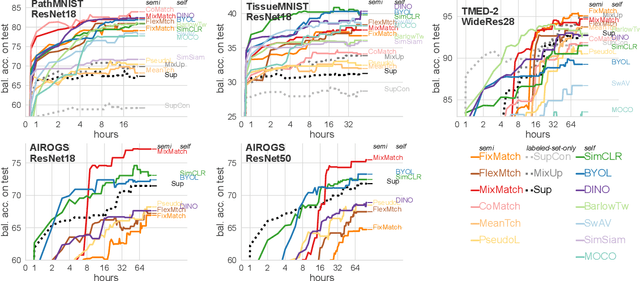
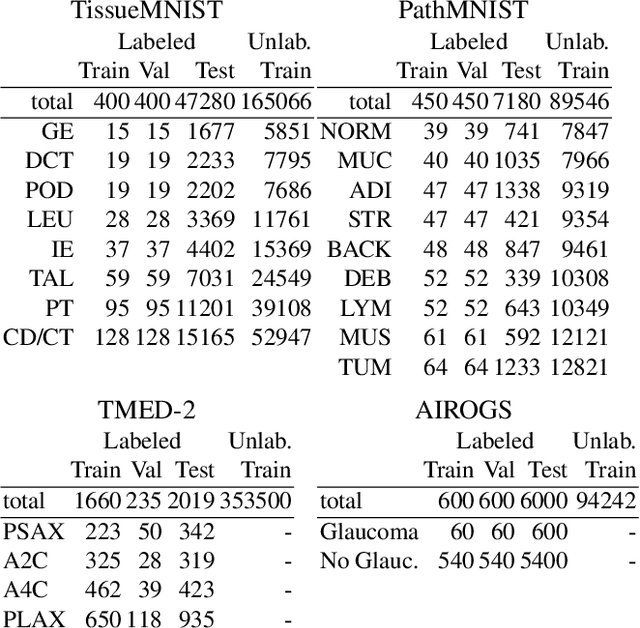
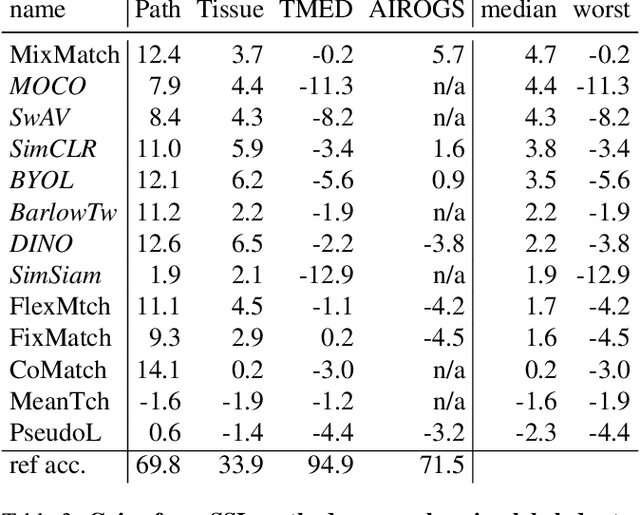
For many applications of classifiers to medical images, a trustworthy label for each image can be difficult or expensive to obtain. In contrast, images without labels are more readily available. Two major research directions both promise that additional unlabeled data can improve classifier performance: self-supervised learning pretrains useful representations on unlabeled data only, then fine-tunes a classifier on these representations via the labeled set; semi-supervised learning directly trains a classifier on labeled and unlabeled data simultaneously. Recent methods from both directions have claimed significant gains on non-medical tasks, but do not systematically assess medical images and mostly compare only to methods in the same direction. This study contributes a carefully-designed benchmark to help answer a practitioner's key question: given a small labeled dataset and a limited budget of hours to spend on training, what gains from additional unlabeled images are possible and which methods best achieve them? Unlike previous benchmarks, ours uses realistic-sized validation sets to select hyperparameters, assesses runtime-performance tradeoffs, and bridges two research fields. By comparing 6 semi-supervised methods and 5 self-supervised methods to strong labeled-only baselines on 3 medical datasets with 30-1000 labels per class, we offer insights to resource-constrained, results-focused practitioners: MixMatch, SimCLR, and BYOL represent strong choices that were not surpassed by more recent methods. After much effort selecting hyperparameters on one dataset, we publish settings that enable strong methods to perform well on new medical tasks within a few hours, with further search over dozens of hours delivering modest additional gains.