 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable contrastive word mover's embedding
Paper and Code
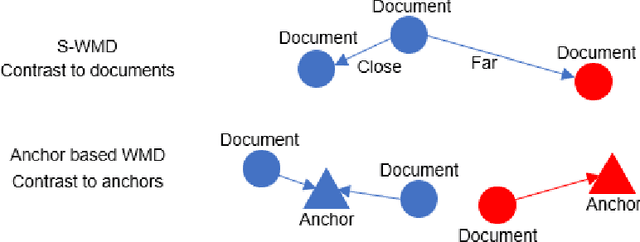
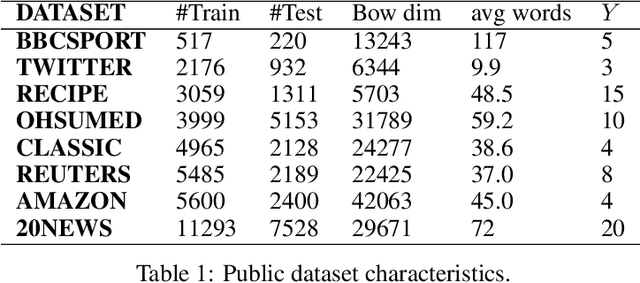

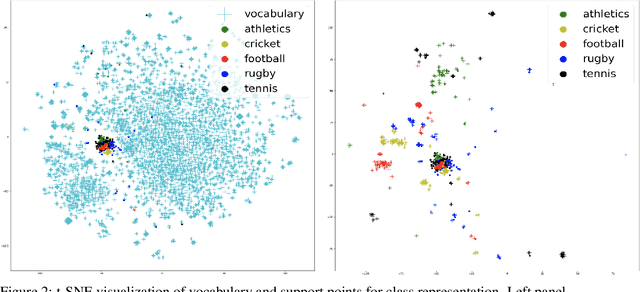
This paper shows that a popular approach to the supervised embedding of documents for classification, namely, contrastive Word Mover's Embedding, can be significantly enhanced by adding interpretability. This interpretability is achieved by incorporating a clustering promoting mechanism into the contrastive loss. On several public datasets, we show that our method improves significantly upon existing baselines while providing interpretation to the clusters via identifying a set of keywords that are the most representative of a particular class. Our approach was motivated in part by the need to develop Natural Language Processing (NLP) methods for the \textit{novel problem of assessing student work for scientific writing and thinking} - a problem that is central to the area of (educational) Learning Sciences (LS). In this context, we show that our approach leads to a meaningful assessment of the student work related to lab reports from a biology class and can help LS researchers gain insights into student understanding and assess evidence of scientific thought processes.