 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable contrastive word mover's embedding
Nov 01, 2021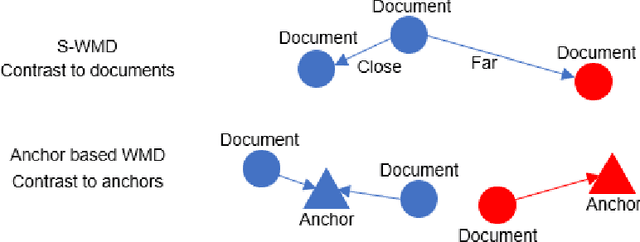

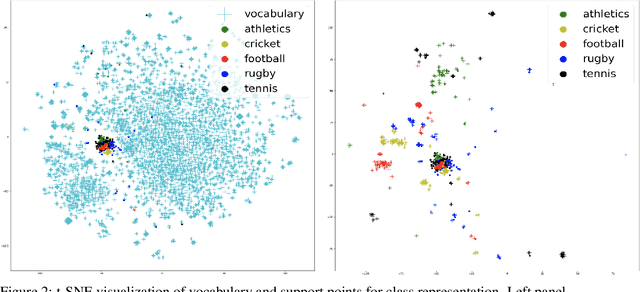
This paper shows that a popular approach to the supervised embedding of documents for classification, namely, contrastive Word Mover's Embedding, can be significantly enhanced by adding interpretability. This interpretability is achieved by incorporating a clustering promoting mechanism into the contrastive loss. On several public datasets, we show that our method improves significantly upon existing baselines while providing interpretation to the clusters via identifying a set of keywords that are the most representative of a particular class. Our approach was motivated in part by the need to develop Natural Language Processing (NLP) methods for the \textit{novel problem of assessing student work for scientific writing and thinking} - a problem that is central to the area of (educational) Learning Sciences (LS). In this context, we show that our approach leads to a meaningful assessment of the student work related to lab reports from a biology class and can help LS researchers gain insights into student understanding and assess evidence of scientific thought processes.
Automatic coding of students' writing via Contrastive Representation Learning in the Wasserstein space
Dec 01, 2020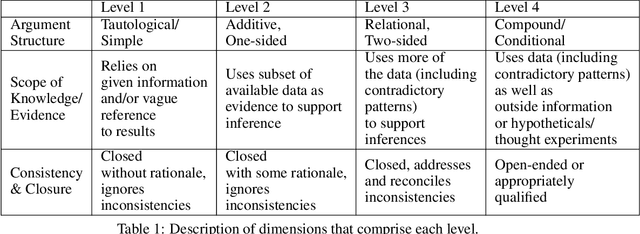

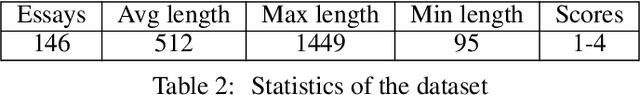
Qualitative analysis of verbal data is of central importance in the learning sciences. It is labor-intensive and time-consuming, however, which limits the amount of data researchers can include in studies. This work is a step towards building a statistical machine learning (ML) method for achieving an automated support for qualitative analyses of students' writing, here specifically in score laboratory reports in introductory biology for sophistication of argumentation and reasoning. We start with a set of lab reports from an undergraduate biology course, scored by a four-level scheme that considers the complexity of argument structure, the scope of evidence, and the care and nuance of conclusions. Using this set of labeled data, we show that a popular natural language modeling processing pipeline, namely vector representation of words, a.k.a word embeddings, followed by Long Short Term Memory (LSTM) model for capturing language generation as a state-space model, is able to quantitatively capture the scoring, with a high Quadratic Weighted Kappa (QWK) prediction score, when trained in via a novel contrastive learning set-up. We show that the ML algorithm approached the inter-rater reliability of human analysis. Ultimately, we conclude, that machine learning (ML) for natural language processing (NLP) holds promise for assisting learning sciences researchers in conducting qualitative studies at much larger scales than is currently possible.