 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Professional Radiologists' Expertise to Enhance LLMs' Evaluation for Radiology Reports
Feb 02, 2024
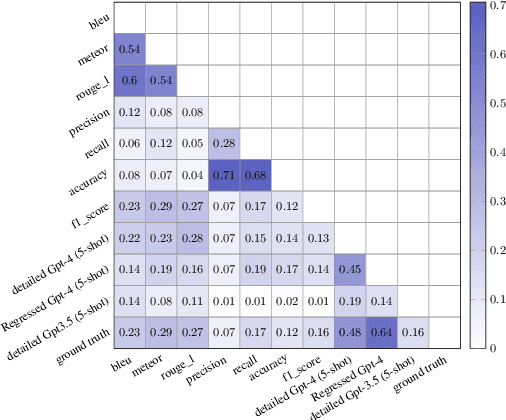

In radiology, Artificial Intelligence (AI) has significantly advanced report generation, but automatic evaluation of these AI-produced reports remains challenging. Current metrics, such as Conventional Natural Language Generation (NLG) and Clinical Efficacy (CE), often fall short in capturing the semantic intricacies of clinical contexts or overemphasize clinical details, undermining report clarity. To overcome these issues, our proposed method synergizes the expertise of professional radiologists with Large Language Models (LLMs), like GPT-3.5 and GPT-4 1. Utilizing In-Context Instruction Learning (ICIL) and Chain of Thought (CoT) reasoning, our approach aligns LLM evaluations with radiologist standards, enabling detailed comparisons between human and AI generated reports. This is further enhanced by a Regression model that aggregates sentence evaluation scores. Experimental results show that our "Detailed GPT-4 (5-shot)" model achieves a 0.48 score, outperforming the METEOR metric by 0.19, while our "Regressed GPT-4" model shows even greater alignment with expert evaluations, exceeding the best existing metric by a 0.35 margin. Moreover, the robustness of our explanations has been validated through a thorough iterative strategy. We plan to publicly release annotations from radiology experts, setting a new standard for accuracy in future assessments. This underscores the potential of our approach in enhancing the quality assessment of AI-driven medical reports.
Deep Network Interpolation for Accelerated Parallel MR Image Reconstruction
Jul 12, 2020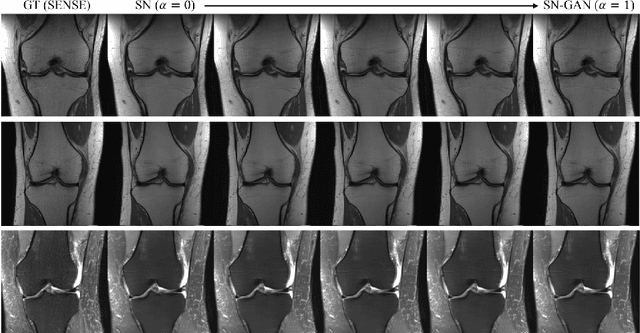
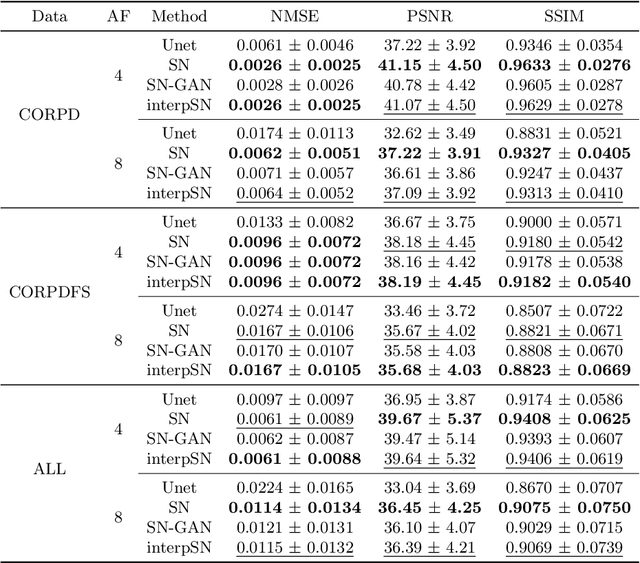
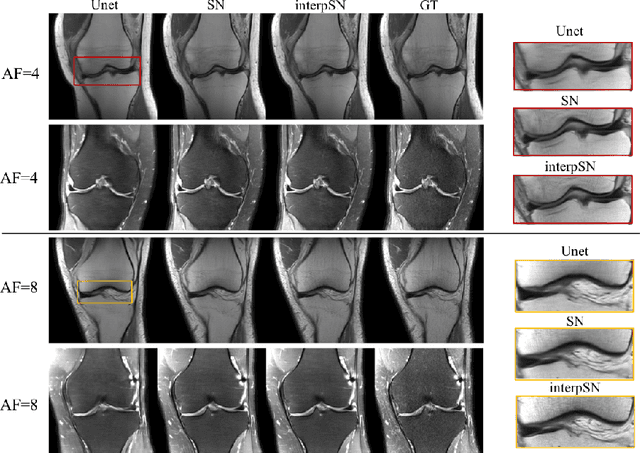
We present a deep network interpolation strategy for accelerated parallel MR image reconstruction. In particular, we examine the network interpolation in parameter space between a source model that is formulated in an unrolled scheme with L1 and SSIM losses and its counterpart that is trained with an adversarial loss. We show that by interpolating between the two different models of the same network structure, the new interpolated network can model a trade-off between perceptual quality and fidelity.
Learning to Read Chest X-Rays: Recurrent Neural Cascade Model for Automated Image Annotation
Mar 28, 2016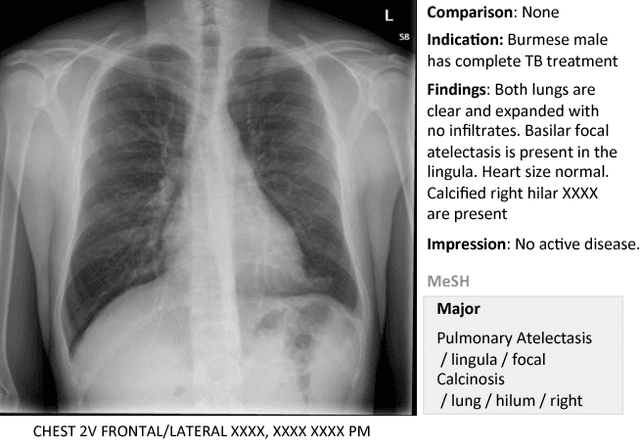
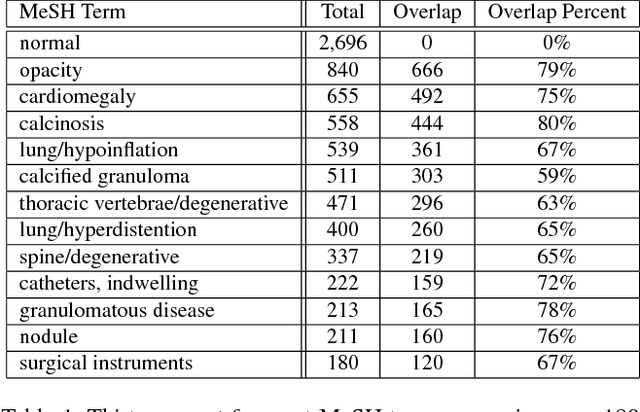
Despite the recent advances in automatically describing image contents, their applications have been mostly limited to image caption datasets containing natural images (e.g., Flickr 30k, MSCOCO). In this paper, we present a deep learning model to efficiently detect a disease from an image and annotate its contexts (e.g., location, severity and the affected organs). We employ a publicly available radiology dataset of chest x-rays and their reports, and use its image annotations to mine disease names to train convolutional neural networks (CNNs). In doing so, we adopt various regularization techniques to circumvent the large normal-vs-diseased cases bias. Recurrent neural networks (RNNs) are then trained to describe the contexts of a detected disease, based on the deep CNN features. Moreover, we introduce a novel approach to use the weights of the already trained pair of CNN/RNN on the domain-specific image/text dataset, to infer the joint image/text contexts for composite image labeling. Significantly improved image annotation results are demonstrated using the recurrent neural cascade model by taking the joint image/text contexts into account.