 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKRNet: Towards Efficient Knowledge Replay
May 23, 2022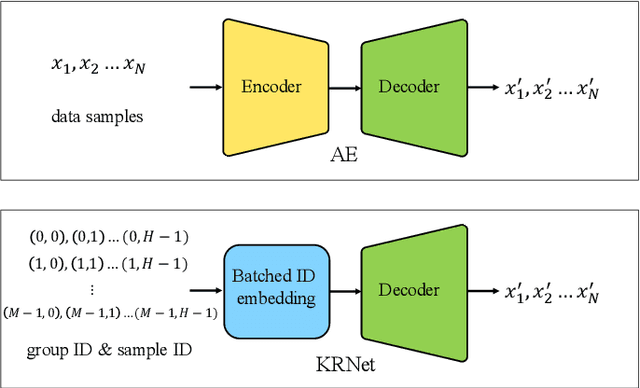
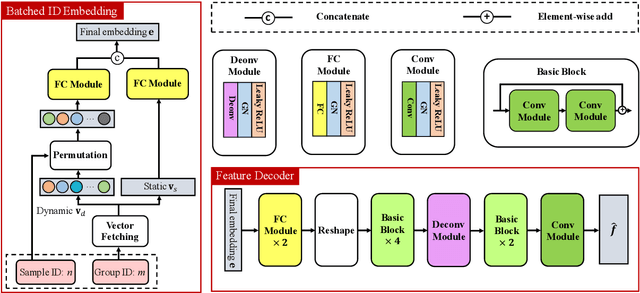

The knowledge replay technique has been widely used in many tasks such as continual learning and continuous domain adaptation. The key lies in how to effectively encode the knowledge extracted from previous data and replay them during current training procedure. A simple yet effective model to achieve knowledge replay is autoencoder. However, the number of stored latent codes in autoencoder increases linearly with the scale of data and the trained encoder is redundant for the replaying stage. In this paper, we propose a novel and efficient knowledge recording network (KRNet) which directly maps an arbitrary sample identity number to the corresponding datum. Compared with autoencoder, our KRNet requires significantly ($400\times$) less storage cost for the latent codes and can be trained without the encoder sub-network. Extensive experiments validate the efficiency of KRNet, and as a showcase, it is successfully applied in the task of continual learning.
Self-distilled Knowledge Delegator for Exemplar-free Class Incremental Learning
May 23, 2022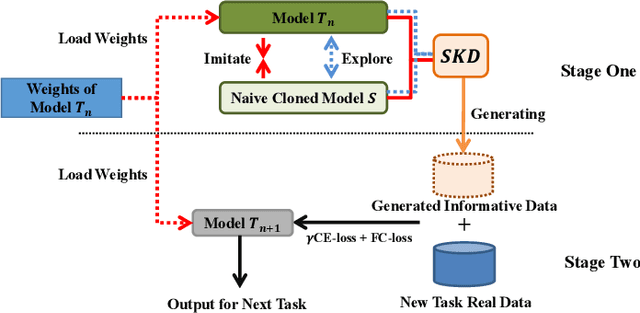
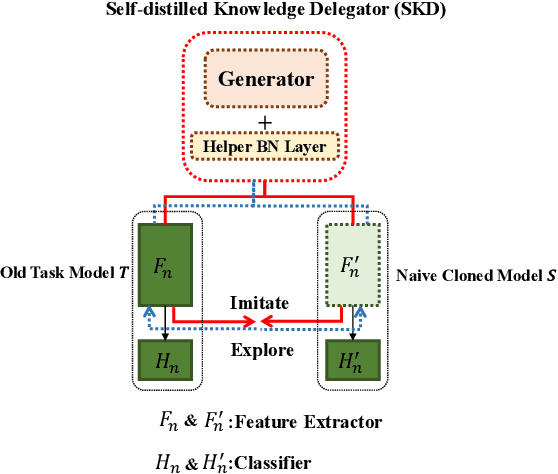
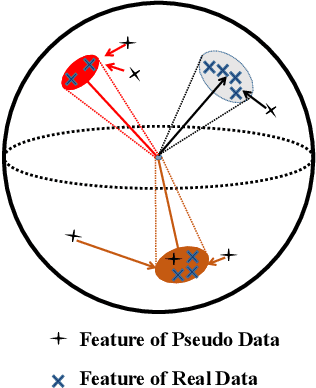
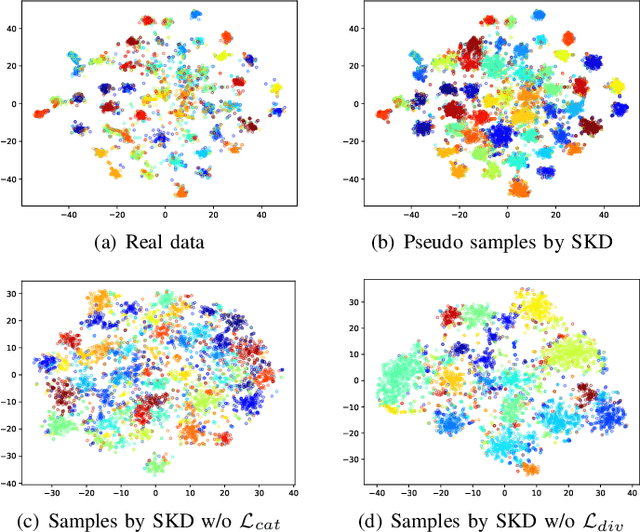
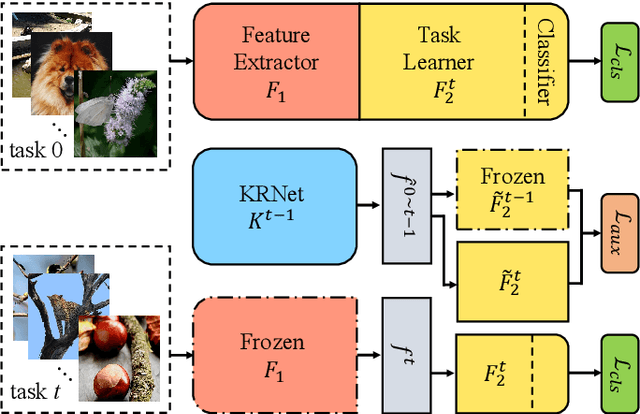
Exemplar-free incremental learning is extremely challenging due to inaccessibility of data from old tasks. In this paper, we attempt to exploit the knowledge encoded in a previously trained classification model to handle the catastrophic forgetting problem in continual learning. Specifically, we introduce a so-called knowledge delegator, which is capable of transferring knowledge from the trained model to a randomly re-initialized new model by generating informative samples. Given the previous model only, the delegator is effectively learned using a self-distillation mechanism in a data-free manner. The knowledge extracted by the delegator is then utilized to maintain the performance of the model on old tasks in incremental learning. This simple incremental learning framework surpasses existing exemplar-free methods by a large margin on four widely used class incremental benchmarks, namely CIFAR-100, ImageNet-Subset, Caltech-101 and Flowers-102. Notably, we achieve comparable performance to some exemplar-based methods without accessing any exemplars.
Topology-aware Convolutional Neural Network for Efficient Skeleton-based Action Recognition
Dec 09, 2021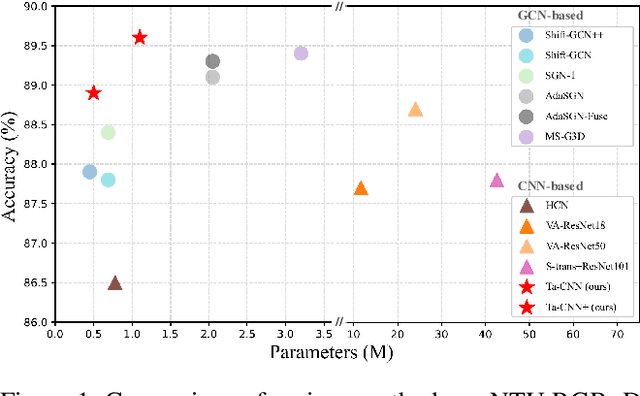
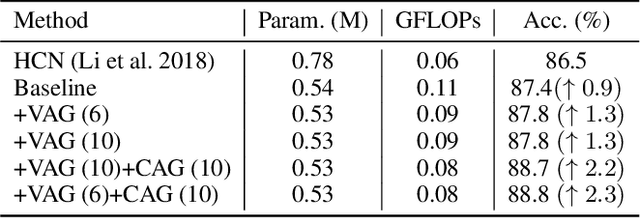

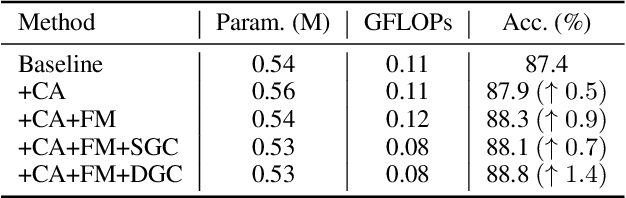
In the context of skeleton-based action recognition, graph convolutional networks (GCNs) have been rapidly developed, whereas convolutional neural networks (CNNs) have received less attention. One reason is that CNNs are considered poor in modeling the irregular skeleton topology. To alleviate this limitation, we propose a pure CNN architecture named Topology-aware CNN (Ta-CNN) in this paper. In particular, we develop a novel cross-channel feature augmentation module, which is a combo of map-attend-group-map operations. By applying the module to the coordinate level and the joint level subsequently, the topology feature is effectively enhanced. Notably, we theoretically prove that graph convolution is a special case of normal convolution when the joint dimension is treated as channels. This confirms that the topology modeling power of GCNs can also be implemented by using a CNN. Moreover, we creatively design a SkeletonMix strategy which mixes two persons in a unique manner and further boosts the performance. Extensive experiments are conducted on four widely used datasets, i.e. N-UCLA, SBU, NTU RGB+D and NTU RGB+D 120 to verify the effectiveness of Ta-CNN. We surpass existing CNN-based methods significantly. Compared with leading GCN-based methods, we achieve comparable performance with much less complexity in terms of the required GFLOPs and parameters.
Divide-and-Assemble: Learning Block-wise Memory for Unsupervised Anomaly Detection
Jul 28, 2021

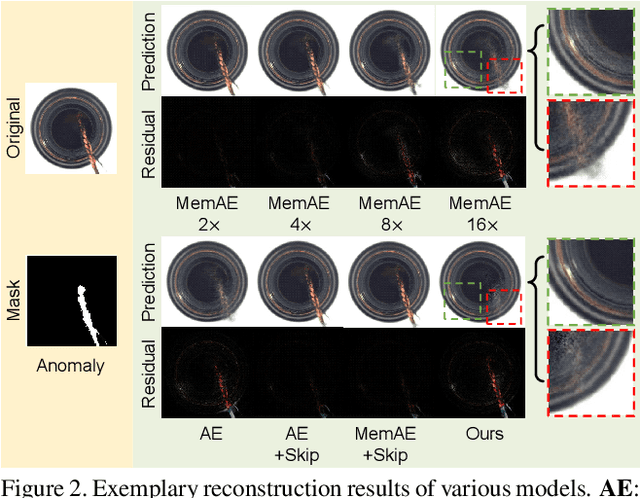

Reconstruction-based methods play an important role in unsupervised anomaly detection in images. Ideally, we expect a perfect reconstruction for normal samples and poor reconstruction for abnormal samples. Since the generalizability of deep neural networks is difficult to control, existing models such as autoencoder do not work well. In this work, we interpret the reconstruction of an image as a divide-and-assemble procedure. Surprisingly, by varying the granularity of division on feature maps, we are able to modulate the reconstruction capability of the model for both normal and abnormal samples. That is, finer granularity leads to better reconstruction, while coarser granularity leads to poorer reconstruction. With proper granularity, the gap between the reconstruction error of normal and abnormal samples can be maximized. The divide-and-assemble framework is implemented by embedding a novel multi-scale block-wise memory module into an autoencoder network. Besides, we introduce adversarial learning and explore the semantic latent representation of the discriminator, which improves the detection of subtle anomaly. We achieve state-of-the-art performance on the challenging MVTec AD dataset. Remarkably, we improve the vanilla autoencoder model by 10.1% in terms of the AUROC score.
Modulating Localization and Classification for Harmonized Object Detection
Mar 25, 2021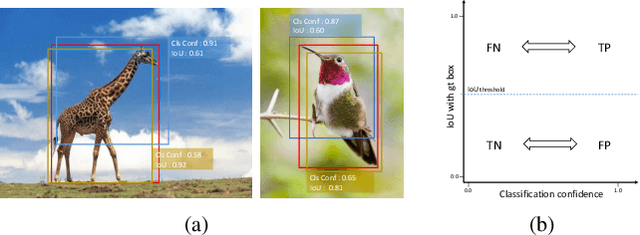



Object detection involves two sub-tasks, i.e. localizing objects in an image and classifying them into various categories. For existing CNN-based detectors, we notice the widespread divergence between localization and classification, which leads to degradation in performance. In this work, we propose a mutual learning framework to modulate the two tasks. In particular, the two tasks are forced to learn from each other with a novel mutual labeling strategy. Besides, we introduce a simple yet effective IoU rescoring scheme, which further reduces the divergence. Moreover, we define a Spearman rank correlation-based metric to quantify the divergence, which correlates well with the detection performance. The proposed approach is general-purpose and can be easily injected into existing detectors such as FCOS and RetinaNet. We achieve a significant performance gain over the baseline detectors on the COCO dataset.
Dynamic GCN: Context-enriched Topology Learning for Skeleton-based Action Recognition
Jul 29, 2020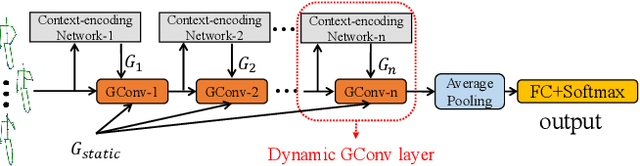

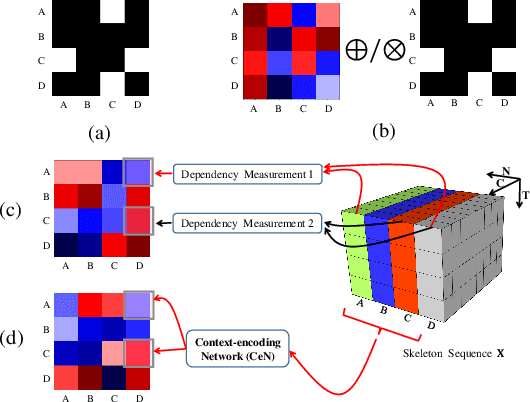
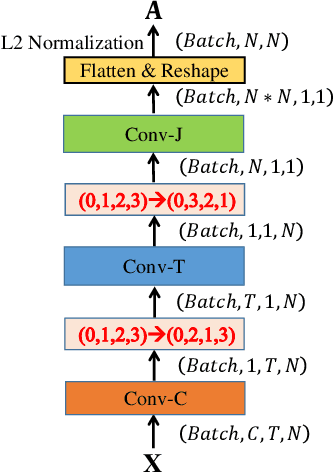
Graph Convolutional Networks (GCNs) have attracted increasing interests for the task of skeleton-based action recognition. The key lies in the design of the graph structure, which encodes skeleton topology information. In this paper, we propose Dynamic GCN, in which a novel convolutional neural network named Contextencoding Network (CeN) is introduced to learn skeleton topology automatically. In particular, when learning the dependency between two joints, contextual features from the rest joints are incorporated in a global manner. CeN is extremely lightweight yet effective, and can be embedded into a graph convolutional layer. By stacking multiple CeN-enabled graph convolutional layers, we build Dynamic GCN. Notably, as a merit of CeN, dynamic graph topologies are constructed for different input samples as well as graph convolutional layers of various depths. Besides, three alternative context modeling architectures are well explored, which may serve as a guideline for future research on graph topology learning. CeN brings only ~7% extra FLOPs for the baseline model, and Dynamic GCN achieves better performance with $2\times$~$4\times$ fewer FLOPs than existing methods. By further combining static physical body connections and motion modalities, we achieve state-of-the-art performance on three large-scale benchmarks, namely NTU-RGB+D, NTU-RGB+D 120 and Skeleton-Kinetics.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020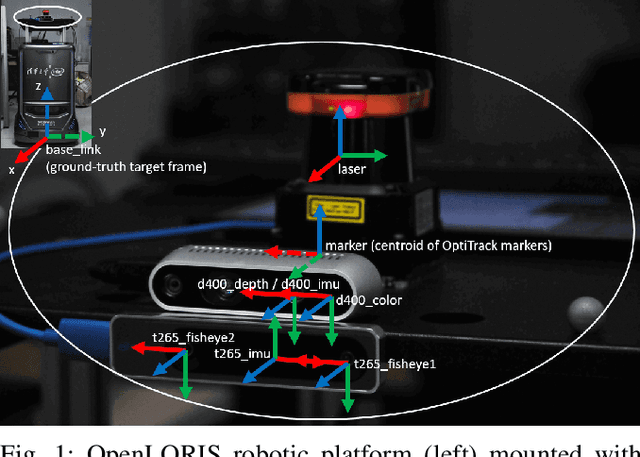
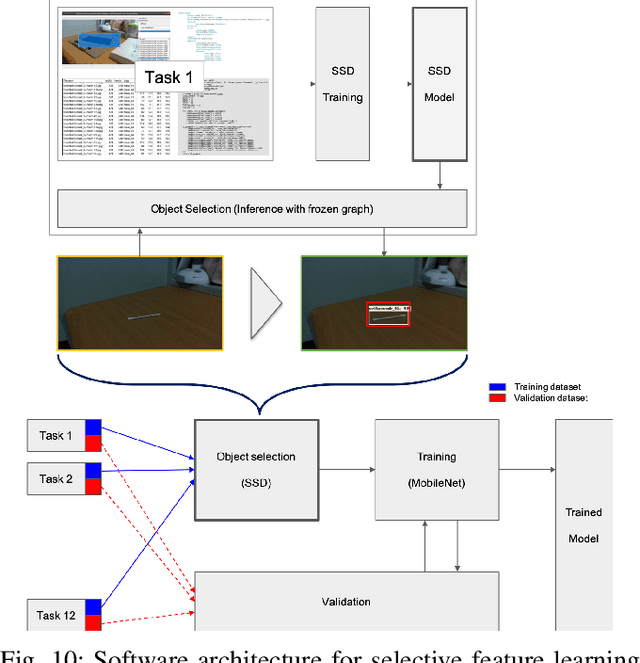
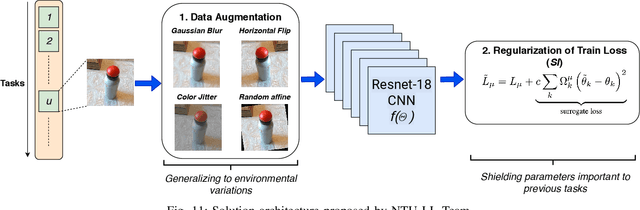

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
Collaborative Spatio-temporal Feature Learning for Video Action Recognition
Mar 04, 2019



Spatio-temporal feature learning is of central importance for action recognition in videos. Existing deep neural network models either learn spatial and temporal features independently (C2D) or jointly with unconstrained parameters (C3D). In this paper, we propose a novel neural operation which encodes spatio-temporal features collaboratively by imposing a weight-sharing constraint on the learnable parameters. In particular, we perform 2D convolution along three orthogonal views of volumetric video data,which learns spatial appearance and temporal motion cues respectively. By sharing the convolution kernels of different views, spatial and temporal features are collaboratively learned and thus benefit from each other. The complementary features are subsequently fused by a weighted summation whose coefficients are learned end-to-end. Our approach achieves state-of-the-art performance on large-scale benchmarks and won the 1st place in the Moments in Time Challenge 2018. Moreover, based on the learned coefficients of different views, we are able to quantify the contributions of spatial and temporal features. This analysis sheds light on interpretability of the model and may also guide the future design of algorithm for video recognition.
Learning Incremental Triplet Margin for Person Re-identification
Dec 17, 2018

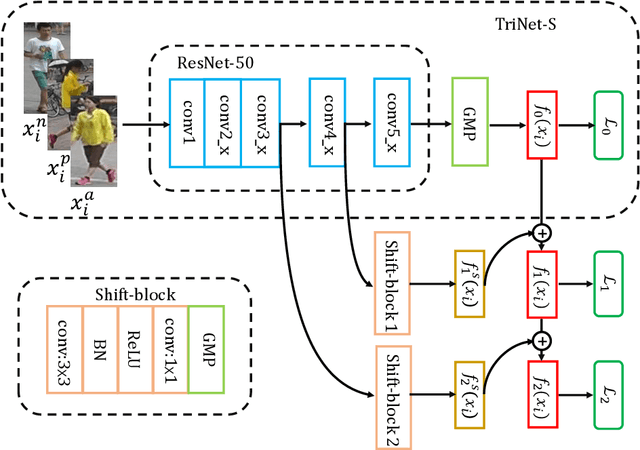

Person re-identification (ReID) aims to match people across multiple non-overlapping video cameras deployed at different locations. To address this challenging problem, many metric learning approaches have been proposed, among which triplet loss is one of the state-of-the-arts. In this work, we explore the margin between positive and negative pairs of triplets and prove that large margin is beneficial. In particular, we propose a novel multi-stage training strategy which learns incremental triplet margin and improves triplet loss effectively. Multiple levels of feature maps are exploited to make the learned features more discriminative. Besides, we introduce global hard identity searching method to sample hard identities when generating a training batch. Extensive experiments on Market-1501, CUHK03, and DukeMTMCreID show that our approach yields a performance boost and outperforms most existing state-of-the-art methods.
Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation
Apr 17, 2018


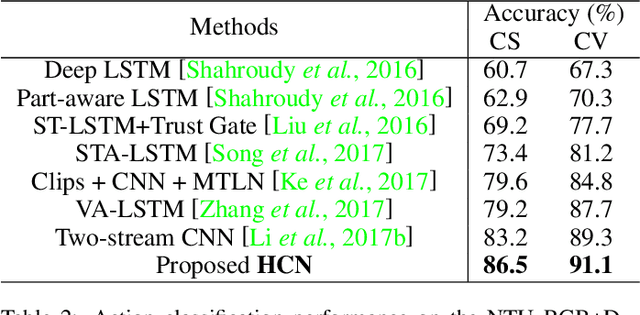
Skeleton-based human action recognition has recently drawn increasing attentions with the availability of large-scale skeleton datasets. The most crucial factors for this task lie in two aspects: the intra-frame representation for joint co-occurrences and the inter-frame representation for skeletons' temporal evolutions. In this paper we propose an end-to-end convolutional co-occurrence feature learning framework. The co-occurrence features are learned with a hierarchical methodology, in which different levels of contextual information are aggregated gradually. Firstly point-level information of each joint is encoded independently. Then they are assembled into semantic representation in both spatial and temporal domains. Specifically, we introduce a global spatial aggregation scheme, which is able to learn superior joint co-occurrence features over local aggregation. Besides, raw skeleton coordinates as well as their temporal difference are integrated with a two-stream paradigm. Experiments show that our approach consistently outperforms other state-of-the-arts on action recognition and detection benchmarks like NTU RGB+D, SBU Kinect Interaction and PKU-MMD.