 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Segmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images
Dec 20, 2023

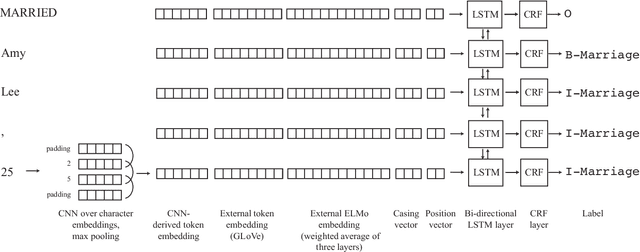

Text segmentation, the task of dividing a document into sections, is often a prerequisite for performing additional natural language processing tasks. Existing text segmentation methods have typically been developed and tested using clean, narrative-style text with segments containing distinct topics. Here we consider a challenging text segmentation task: dividing newspaper marriage announcement lists into units of one announcement each. In many cases the information is not structured into sentences, and adjacent segments are not topically distinct from each other. In addition, the text of the announcements, which is derived from images of historical newspapers via optical character recognition, contains many typographical errors. As a result, these announcements are not amenable to segmentation with existing techniques. We present a novel deep learning-based model for segmenting such text and show that it significantly outperforms an existing state-of-the-art method on our task.
* 8 pages, 4 figures
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Deeper Task-Specificity Improves Joint Entity and Relation Extraction
Feb 15, 2020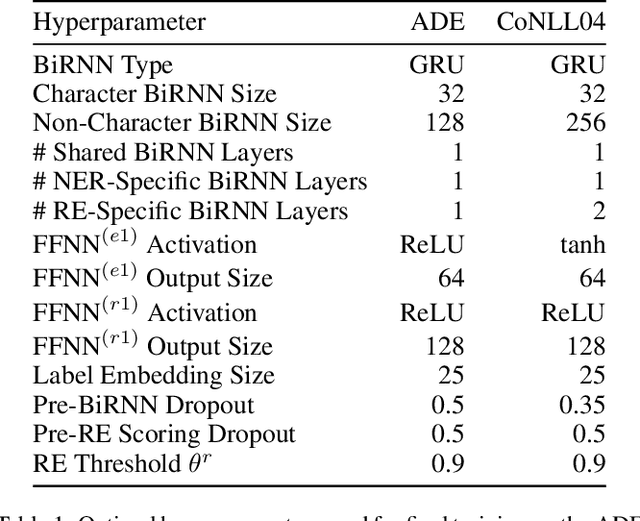
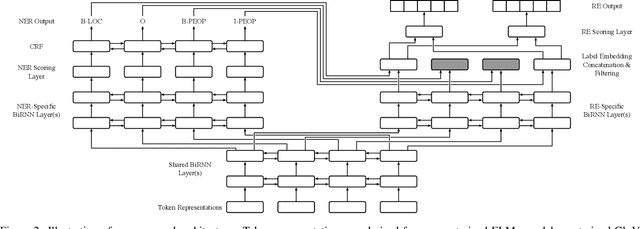
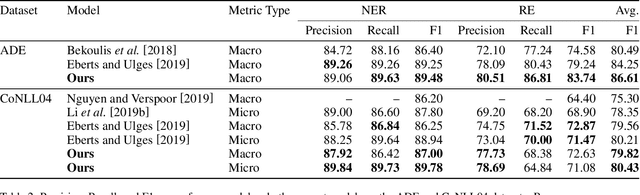
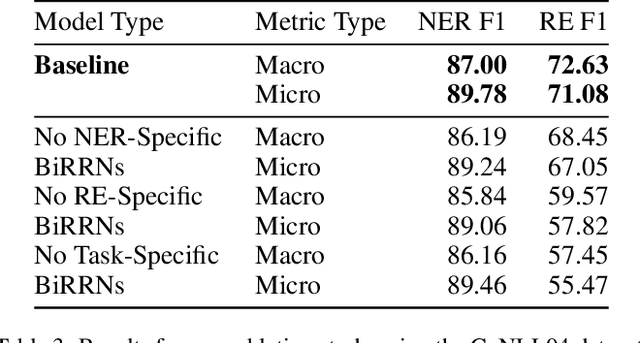
Multi-task learning (MTL) is an effective method for learning related tasks, but designing MTL models necessitates deciding which and how many parameters should be task-specific, as opposed to shared between tasks. We investigate this issue for the problem of jointly learning named entity recognition (NER) and relation extraction (RE) and propose a novel neural architecture that allows for deeper task-specificity than does prior work. In particular, we introduce additional task-specific bidirectional RNN layers for both the NER and RE tasks and tune the number of shared and task-specific layers separately for different datasets. We achieve state-of-the-art (SOTA) results for both tasks on the ADE dataset; on the CoNLL04 dataset, we achieve SOTA results on the NER task and competitive results on the RE task while using an order of magnitude fewer trainable parameters than the current SOTA architecture. An ablation study confirms the importance of the additional task-specific layers for achieving these results. Our work suggests that previous solutions to joint NER and RE undervalue task-specificity and demonstrates the importance of correctly balancing the number of shared and task-specific parameters for MTL approaches in general.