 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper Task-Specificity Improves Joint Entity and Relation Extraction
Paper and Code
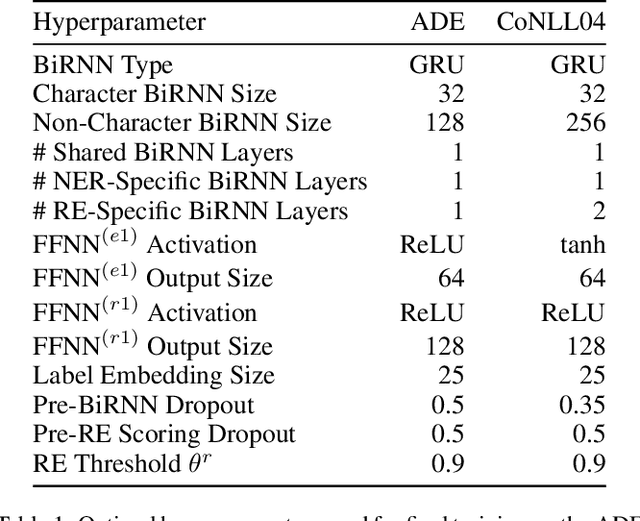
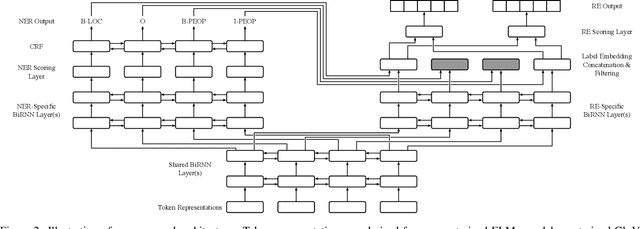
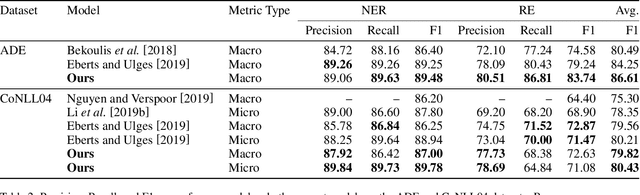
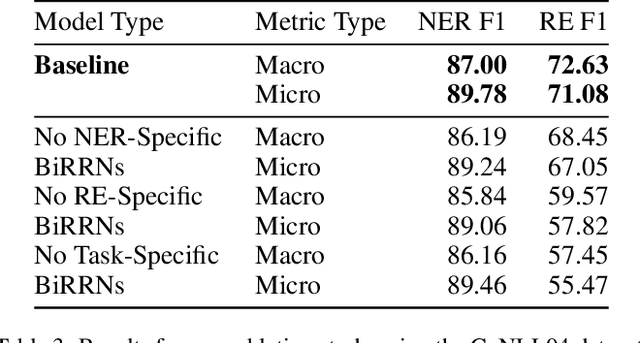
Multi-task learning (MTL) is an effective method for learning related tasks, but designing MTL models necessitates deciding which and how many parameters should be task-specific, as opposed to shared between tasks. We investigate this issue for the problem of jointly learning named entity recognition (NER) and relation extraction (RE) and propose a novel neural architecture that allows for deeper task-specificity than does prior work. In particular, we introduce additional task-specific bidirectional RNN layers for both the NER and RE tasks and tune the number of shared and task-specific layers separately for different datasets. We achieve state-of-the-art (SOTA) results for both tasks on the ADE dataset; on the CoNLL04 dataset, we achieve SOTA results on the NER task and competitive results on the RE task while using an order of magnitude fewer trainable parameters than the current SOTA architecture. An ablation study confirms the importance of the additional task-specific layers for achieving these results. Our work suggests that previous solutions to joint NER and RE undervalue task-specificity and demonstrates the importance of correctly balancing the number of shared and task-specific parameters for MTL approaches in general.