 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images
Paper and Code
Dec 20, 2023

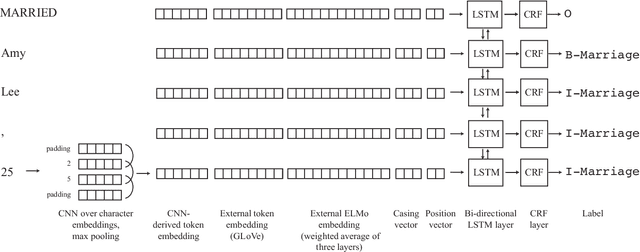

Text segmentation, the task of dividing a document into sections, is often a prerequisite for performing additional natural language processing tasks. Existing text segmentation methods have typically been developed and tested using clean, narrative-style text with segments containing distinct topics. Here we consider a challenging text segmentation task: dividing newspaper marriage announcement lists into units of one announcement each. In many cases the information is not structured into sentences, and adjacent segments are not topically distinct from each other. In addition, the text of the announcements, which is derived from images of historical newspapers via optical character recognition, contains many typographical errors. As a result, these announcements are not amenable to segmentation with existing techniques. We present a novel deep learning-based model for segmenting such text and show that it significantly outperforms an existing state-of-the-art method on our task.