 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive MPC-based quadrupedal robot control under periodic disturbances
May 18, 2025Recent advancements in adaptive control for reference trajectory tracking enable quadrupedal robots to perform locomotion tasks under challenging conditions. There are methods enabling the estimation of the external disturbances in terms of forces and torques. However, a specific case of disturbances that are periodic was not explicitly tackled in application to quadrupeds. This work is devoted to the estimation of the periodic disturbances with a lightweight regressor using simplified robot dynamics and extracting the disturbance properties in terms of the magnitude and frequency. Experimental evidence suggests performance improvement over the baseline static disturbance compensation. All source files, including simulation setups, code, and calculation scripts, are available on GitHub at https://github.com/aidagroup/quad-periodic-mpc.
Multi-CALF: A Policy Combination Approach with Statistical Guarantees
May 18, 2025We introduce Multi-CALF, an algorithm that intelligently combines reinforcement learning policies based on their relative value improvements. Our approach integrates a standard RL policy with a theoretically-backed alternative policy, inheriting formal stability guarantees while often achieving better performance than either policy individually. We prove that our combined policy converges to a specified goal set with known probability and provide precise bounds on maximum deviation and convergence time. Empirical validation on control tasks demonstrates enhanced performance while maintaining stability guarantees.
A universal policy wrapper with guarantees
May 18, 2025We introduce a universal policy wrapper for reinforcement learning agents that ensures formal goal-reaching guarantees. In contrast to standard reinforcement learning algorithms that excel in performance but lack rigorous safety assurances, our wrapper selectively switches between a high-performing base policy -- derived from any existing RL method -- and a fallback policy with known convergence properties. Base policy's value function supervises this switching process, determining when the fallback policy should override the base policy to ensure the system remains on a stable path. The analysis proves that our wrapper inherits the fallback policy's goal-reaching guarantees while preserving or improving upon the performance of the base policy. Notably, it operates without needing additional system knowledge or online constrained optimization, making it readily deployable across diverse reinforcement learning architectures and tasks.
Quadrupedal Robot Skateboard Mounting via Reverse Curriculum Learning
May 10, 2025The aim of this work is to enable quadrupedal robots to mount skateboards using Reverse Curriculum Reinforcement Learning. Although prior work has demonstrated skateboarding for quadrupeds that are already positioned on the board, the initial mounting phase still poses a significant challenge. A goal-oriented methodology was adopted, beginning with the terminal phases of the task and progressively increasing the complexity of the problem definition to approximate the desired objective. The learning process was initiated with the skateboard rigidly fixed within the global coordinate frame and the robot positioned directly above it. Through gradual relaxation of these initial conditions, the learned policy demonstrated robustness to variations in skateboard position and orientation, ultimately exhibiting a successful transfer to scenarios involving a mobile skateboard. The code, trained models, and reproducible examples are available at the following link: https://github.com/dancher00/quadruped-skateboard-mounting
Towards a constructive framework for control theory
Jan 04, 2025This work presents a framework for control theory based on constructive analysis to account for discrepancy between mathematical results and their implementation in a computer, also referred to as computational uncertainty. In control engineering, the latter is usually either neglected or considered submerged into some other type of uncertainty, such as system noise, and addressed within robust control. However, even robust control methods may be compromised when the mathematical objects involved in the respective algorithms fail to exist in exact form and subsequently fail to satisfy the required properties. For instance, in general stabilization using a control Lyapunov function, computational uncertainty may distort stability certificates or even destabilize the system despite robustness of the stabilization routine with regards to system, actuator and measurement noise. In fact, battling numerical problems in practical implementation of controllers is common among control engineers. Such observations indicate that computational uncertainty should indeed be addressed explicitly in controller synthesis and system analysis. The major contribution here is a fairly general framework for proof techniques in analysis and synthesis of control systems based on constructive analysis which explicitly states that every computation be doable only up to a finite precision thus accounting for computational uncertainty. A series of previous works is overviewed, including constructive system stability and stabilization, approximate optimal controls, eigenvalue problems, Caratheodory trajectories, measurable selectors. Additionally, a new constructive version of the Danskin's theorem, which is crucial in adversarial defense, is presented.
* Published under: https://ieeexplore.ieee.org/document/9419858
Optimizing energy consumption for legged robot by adapting equilibrium position and stiffness of a parallel torsion spring
Nov 27, 2024This paper is dedicated to the development of a novel adaptive torsion spring mechanism for optimizing energy consumption in legged robots. By adjusting the equilibrium position and stiffness of the spring, the system improves energy efficiency during cyclic movements, such as walking and jumping. The adaptive compliance mechanism, consisting of a torsion spring combined with a worm gear driven by a servo actuator, compensates for motion-induced torque and reduces motor load. Simulation results demonstrate a significant reduction in power consumption, highlighting the effectiveness of this approach in enhancing robotic locomotion.
Critic as Lyapunov function (CALF): a model-free, stability-ensuring agent
Sep 15, 2024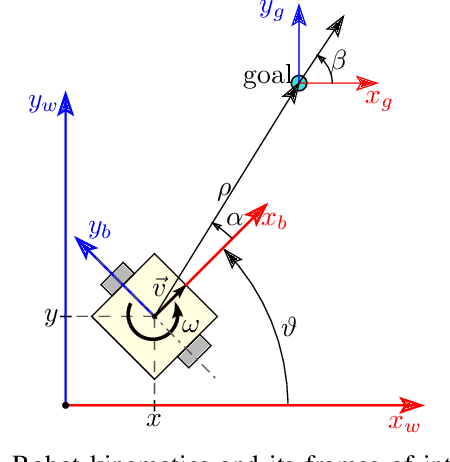
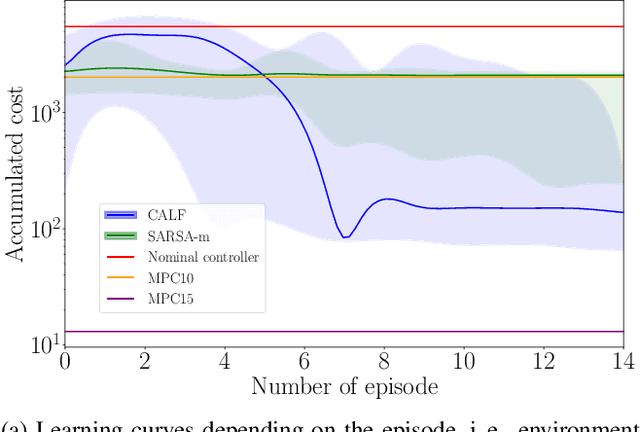
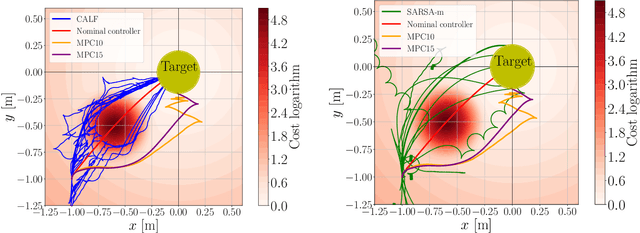
This work presents and showcases a novel reinforcement learning agent called Critic As Lyapunov Function (CALF) which is model-free and ensures online environment, in other words, dynamical system stabilization. Online means that in each learning episode, the said environment is stabilized. This, as demonstrated in a case study with a mobile robot simulator, greatly improves the overall learning performance. The base actor-critic scheme of CALF is analogous to SARSA. The latter did not show any success in reaching the target in our studies. However, a modified version thereof, called SARSA-m here, did succeed in some learning scenarios. Still, CALF greatly outperformed the said approach. CALF was also demonstrated to improve a nominal stabilizer provided to it. In summary, the presented agent may be considered a viable approach to fusing classical control with reinforcement learning. Its concurrent approaches are mostly either offline or model-based, like, for instance, those that fuse model-predictive control into the agent.
An approach to improve agent learning via guaranteeing goal reaching in all episodes
May 29, 2024Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
Combining model-predictive control and predictive reinforcement learning for stable quadrupedal robot locomotion
Jul 15, 2023



Stable gait generation is a crucial problem for legged robot locomotion as this impacts other critical performance factors such as, e.g. mobility over an uneven terrain and power consumption. Gait generation stability results from the efficient control of the interaction between the legged robot's body and the environment where it moves. Here, we study how this can be achieved by a combination of model-predictive and predictive reinforcement learning controllers. Model-predictive control (MPC) is a well-established method that does not utilize any online learning (except for some adaptive variations) as it provides a convenient interface for state constraints management. Reinforcement learning (RL), in contrast, relies on adaptation based on pure experience. In its bare-bone variants, RL is not always suitable for robots due to their high complexity and expensive simulation/experimentation. In this work, we combine both control methods to address the quadrupedal robot stable gate generation problem. The hybrid approach that we develop and apply uses a cost roll-out algorithm with a tail cost in the form of a Q-function modeled by a neural network; this allows to alleviate the computational complexity, which grows exponentially with the prediction horizon in a purely MPC approach. We demonstrate that our RL gait controller achieves stable locomotion at short horizons, where a nominal MP controller fails. Further, our controller is capable of live operation, meaning that it does not require previous training. Our results suggest that the hybridization of MPC with RL, as presented here, is beneficial to achieve a good balance between online control capabilities and computational complexity.
Experimental verification of an online traction parameter identification method
Mar 20, 2023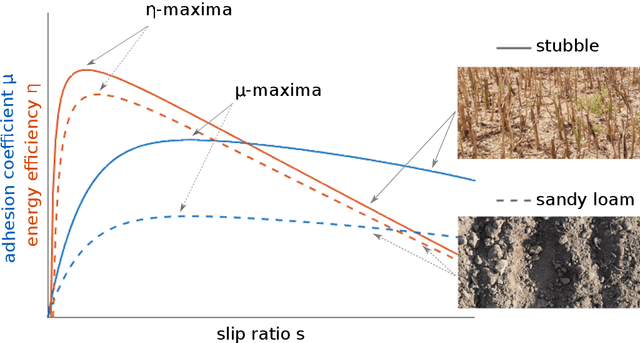

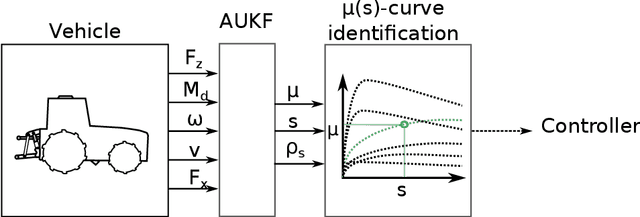
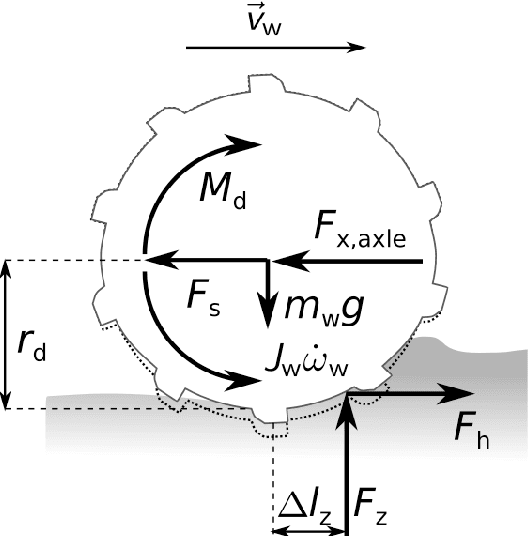
Traction parameters, that characterize the ground-wheel contact dynamics, are the central factor in the energy efficiency of vehicles. To optimize fuel consumption, reduce wear of tires, increase productivity etc., knowledge of current traction parameters is unavoidable. Unfortunately, these parameters are difficult to measure and require expensive force and torque sensors. An alternative way is to use system identification to determine them. In this work, we validate such a method in field experiments with a mobile robot. The method is based on an adaptive Kalman filter. We show how it estimates the traction parameters online, during the motion on the field, and compare them to their values determined via a 6-directional force-torque sensor installed for verification. Data of adhesion slip ratio curves is recorded and compared to curves from literature for additional validation of the method. The results can establish a foundation for a number of optimal traction methods.