 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn stabilizing reinforcement learning without Lyapunov functions
Paper and Code
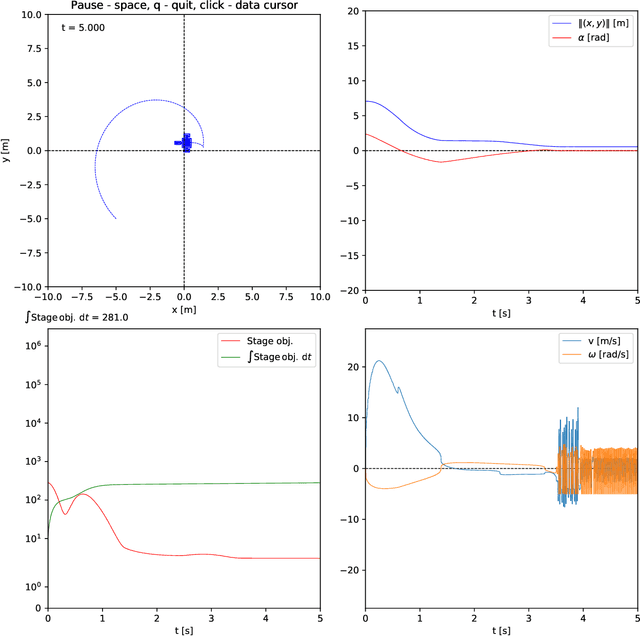
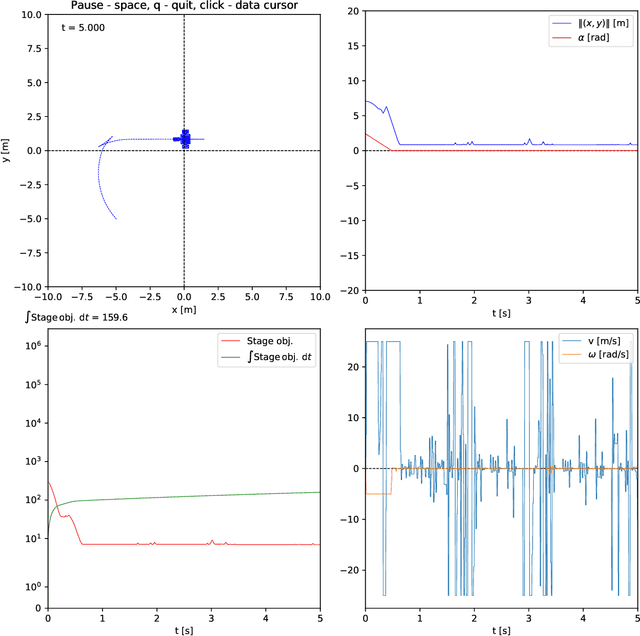
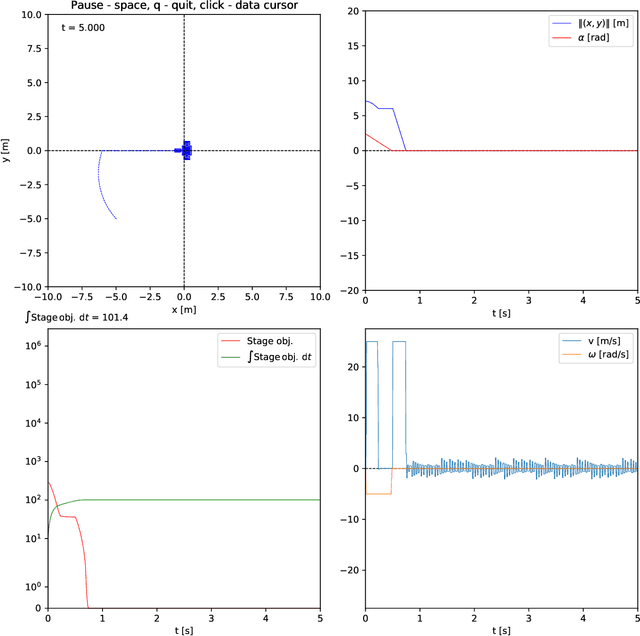

Reinforcement learning remains one of the major directions of the contemporary development of control engineering and machine learning. Nice intuition, flexible settings, ease of application are among the many perks of this methodology. From the standpoint of machine learning, the main strength of a reinforcement learning agent is its ability to ``capture" (learn) the optimal behavior in the given environment. Typically, the agent is built on neural networks and it is their approximation abilities that give rise to the above belief. From the standpoint of control engineering, however, reinforcement learning has serious deficiencies. The most significant one is the lack of stability guarantee of the agent-environment closed loop. A great deal of research was and is being made towards stabilizing reinforcement learning. Speaking of stability, the celebrated Lyapunov theory is the de facto tool. It is thus no wonder that so many techniques of stabilizing reinforcement learning rely on the Lyapunov theory in one way or another. In control theory, there is an intricate connection between a stabilizing controller and a Lyapunov function. Employing such a pair seems thus quite attractive to design stabilizing reinforcement learning. However, computation of a Lyapunov function is generally a cumbersome process. In this note, we show how to construct a stabilizing reinforcement learning agent that does not employ such a function at all. We only assume that a Lyapunov function exists, which is a natural thing to do if the given system (read: environment) is stabilizable, but we do not need to compute one.