 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic as Lyapunov function (CALF): a model-free, stability-ensuring agent
Sep 15, 2024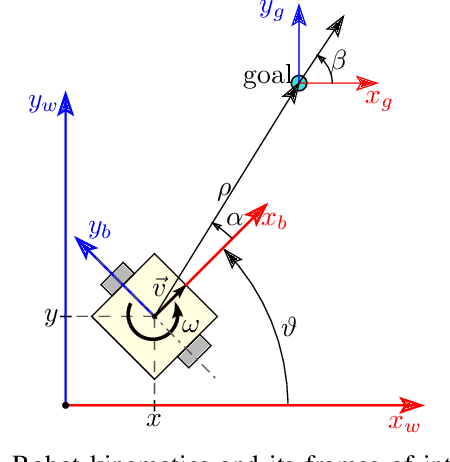
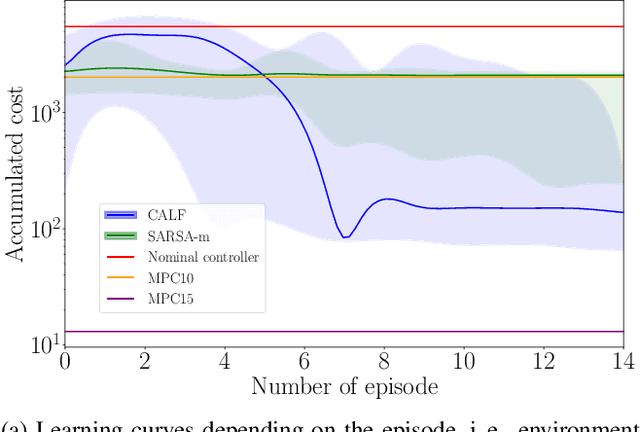
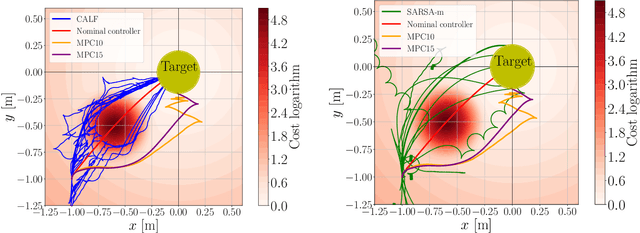
This work presents and showcases a novel reinforcement learning agent called Critic As Lyapunov Function (CALF) which is model-free and ensures online environment, in other words, dynamical system stabilization. Online means that in each learning episode, the said environment is stabilized. This, as demonstrated in a case study with a mobile robot simulator, greatly improves the overall learning performance. The base actor-critic scheme of CALF is analogous to SARSA. The latter did not show any success in reaching the target in our studies. However, a modified version thereof, called SARSA-m here, did succeed in some learning scenarios. Still, CALF greatly outperformed the said approach. CALF was also demonstrated to improve a nominal stabilizer provided to it. In summary, the presented agent may be considered a viable approach to fusing classical control with reinforcement learning. Its concurrent approaches are mostly either offline or model-based, like, for instance, those that fuse model-predictive control into the agent.
A generalized stacked reinforcement learning method for sampled systems
Aug 23, 2021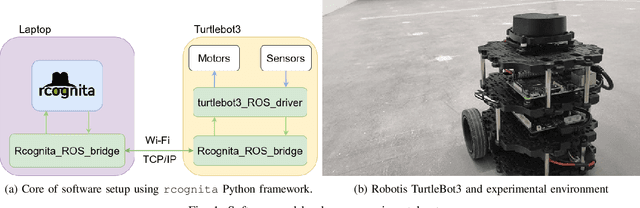

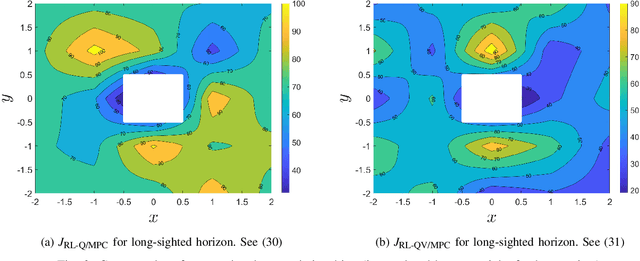
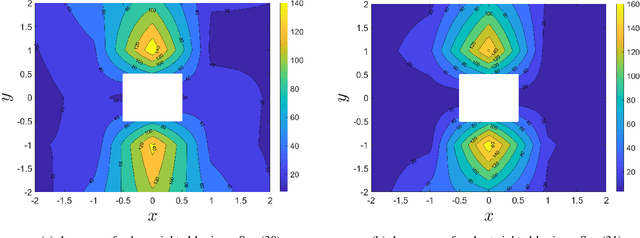
A common setting of reinforcement learning (RL) is a Markov decision process (MDP) in which the environment is a stochastic discrete-time dynamical system. Whereas MDPs are suitable in such applications as video-games or puzzles, physical systems are time-continuous. Continuous methods of RL are known, but they have their limitations, such as, e.g., collapse of Q-learning. A general variant of RL is of digital format, where updates of the value and policy are performed at discrete moments in time. The agent-environment loop then amounts to a sampled system, whereby sample-and-hold is a specific case. In this paper, we propose and benchmark two RL methods suitable for sampled systems. Specifically, we hybridize model-predictive control (MPC) with critics learning the Q- and value function. Optimality is analyzed and performance comparison is done in an experimental case study with a mobile robot.
An experimental study of two predictive reinforcement learning methods and comparison with model-predictive control
Aug 23, 2021
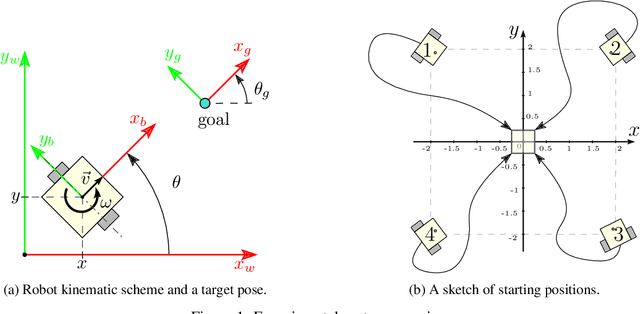
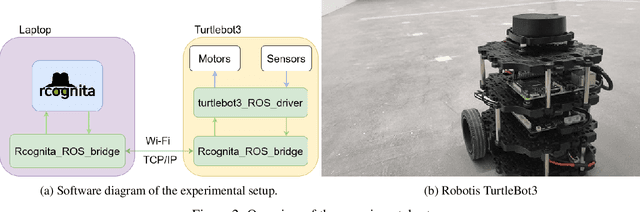
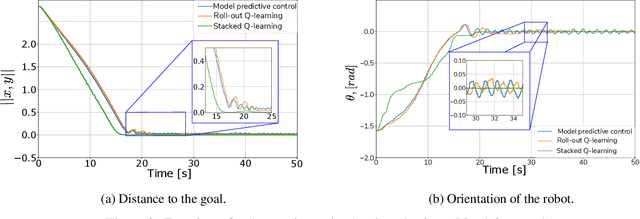
Reinforcement learning (RL) has been successfully used in various simulations and computer games. Industry-related applications, such as autonomous mobile robot motion control, are somewhat challenging for RL up to date though. This paper presents an experimental evaluation of predictive RL controllers for optimal mobile robot motion control. As a baseline for comparison, model-predictive control (MPC) is used. Two RL methods are tested: a roll-out Q-learning, which may be considered as MPC with terminal cost being a Q-function approximation, and a so-called stacked Q-learning, which in turn is like MPC with the running cost substituted for a Q-function approximation. The experimental foundation is a mobile robot with a differential drive (Robotis Turtlebot3). Experimental results showed that both RL methods beat the baseline in terms of the accumulated cost, whereas the stacked variant performed best. Provided the series of previous works on stacked Q-learning, this particular study supports the idea that MPC with a running cost adaptation inspired by Q-learning possesses potential of performance boost while retaining the nice properties of MPC.