 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA stabilizing reinforcement learning approach for sampled systems with partially unknown models
Aug 31, 2022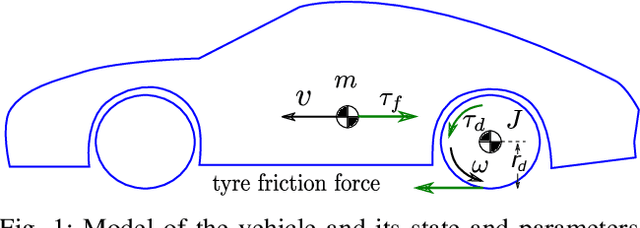
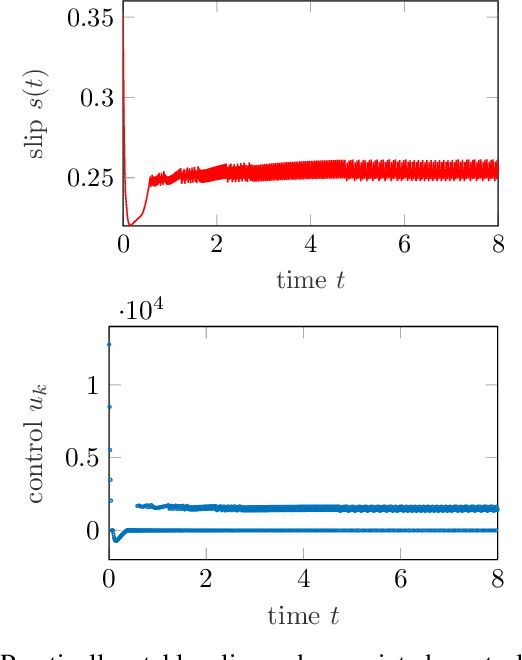
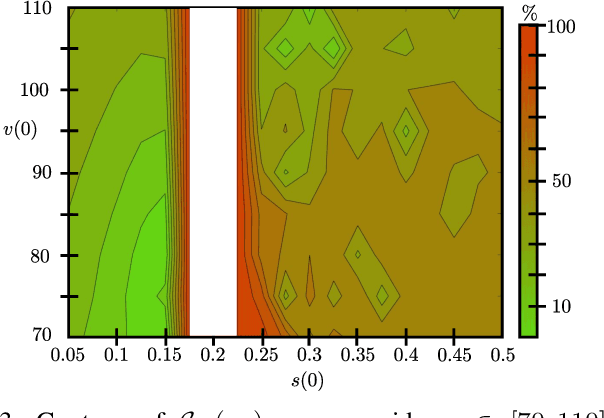
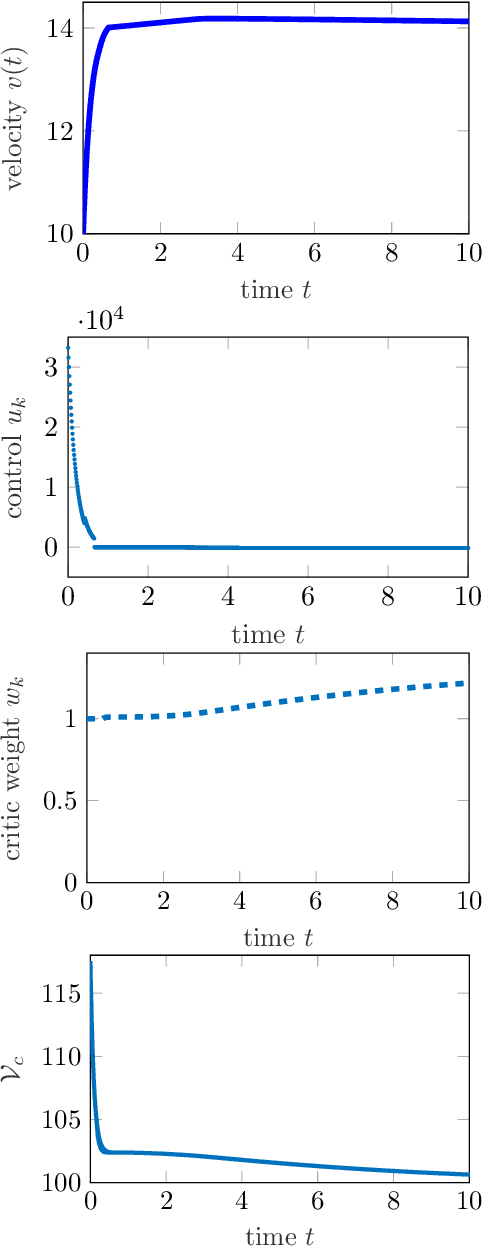
Reinforcement learning is commonly associated with training of reward-maximizing (or cost-minimizing) agents, in other words, controllers. It can be applied in model-free or model-based fashion, using a priori or online collected system data to train involved parametric architectures. In general, online reinforcement learning does not guarantee closed loop stability unless special measures are taken, for instance, through learning constraints or tailored training rules. Particularly promising are hybrids of reinforcement learning with "classical" control approaches. In this work, we suggest a method to guarantee practical stability of the system-controller closed loop in a purely online learning setting, i.e., without offline training. Moreover, we assume only partial knowledge of the system model. To achieve the claimed results, we employ techniques of classical adaptive control. The implementation of the overall control scheme is provided explicitly in a digital, sampled setting. That is, the controller receives the state of the system and computes the control action at discrete, specifically, equidistant moments in time. The method is tested in adaptive traction control and cruise control where it proved to significantly reduce the cost.