 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact-Robust Posture Optimization for Aerial Manipulation
Feb 14, 2026We present a novel method for optimizing the posture of kinematically redundant torque-controlled robots to improve robustness during impacts. A rigid impact model is used as the basis for a configuration-dependent metric that quantifies the variation between pre- and post-impact velocities. By finding configurations (postures) that minimize the aforementioned metric, spikes in the robot's state and input commands can be significantly reduced during impacts, improving safety and robustness. The problem of identifying impact-robust postures is posed as a min-max optimization of the aforementioned metric. To overcome the real-time intractability of the problem, we reformulate it as a gradient-based motion task that iteratively guides the robot towards configurations that minimize the proposed metric. This task is embedded within a task-space inverse dynamics (TSID) whole-body controller, enabling seamless integration with other control objectives. The method is applied to a kinematically redundant aerial manipulator performing repeated point contact tasks. We test our method inside a realistic physics simulator and compare it with the nominal TSID. Our method leads to a reduction (up to 51% w.r.t. standard TSID) of post-impact spikes in the robot's configuration and successfully avoids actuator saturation. Moreover, we demonstrate the importance of kinematic redundancy for impact robustness using additional numerical simulations on a quadruped and a humanoid robot, resulting in up to 45% reduction of post-impact spikes in the robot's state w.r.t. nominal TSID.
Neural Style Transfer with Twin-Delayed DDPG for Shared Control of Robotic Manipulators
Feb 01, 2024
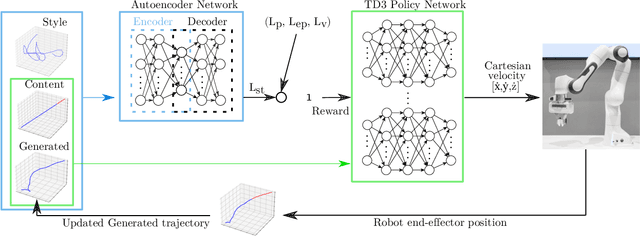
Neural Style Transfer (NST) refers to a class of algorithms able to manipulate an element, most often images, to adopt the appearance or style of another one. Each element is defined as a combination of Content and Style: the Content can be conceptually defined as the what and the Style as the how of said element. In this context, we propose a custom NST framework for transferring a set of styles to the motion of a robotic manipulator, e.g., the same robotic task can be carried out in an angry, happy, calm, or sad way. An autoencoder architecture extracts and defines the Content and the Style of the target robot motions. A Twin Delayed Deep Deterministic Policy Gradient (TD3) network generates the robot control policy using the loss defined by the autoencoder. The proposed Neural Policy Style Transfer TD3 (NPST3) alters the robot motion by introducing the trained style. Such an approach can be implemented either offline, for carrying out autonomous robot motions in dynamic environments, or online, for adapting at runtime the style of a teleoperated robot. The considered styles can be learned online from human demonstrations. We carried out an evaluation with human subjects enrolling 73 volunteers, asking them to recognize the style behind some representative robotic motions. Results show a good recognition rate, proving that it is possible to convey different styles to a robot using this approach.
On the Stability of Gated Graph Neural Networks
May 30, 2023
In this paper, we aim to find the conditions for input-state stability (ISS) and incremental input-state stability ($\delta$ISS) of Gated Graph Neural Networks (GGNNs). We show that this recurrent version of Graph Neural Networks (GNNs) can be expressed as a dynamical distributed system and, as a consequence, can be analysed using model-based techniques to assess its stability and robustness properties. Then, the stability criteria found can be exploited as constraints during the training process to enforce the internal stability of the neural network. Two distributed control examples, flocking and multi-robot motion control, show that using these conditions increases the performance and robustness of the gated GNNs.
COP: Control & Observability-aware Planning
Mar 14, 2022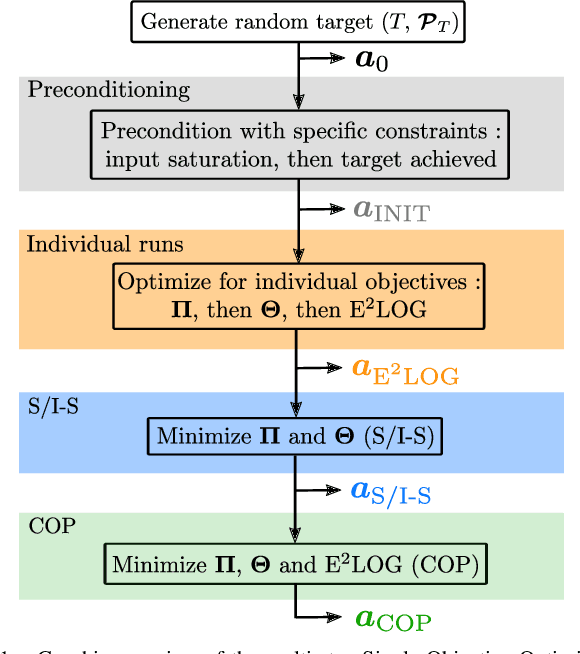
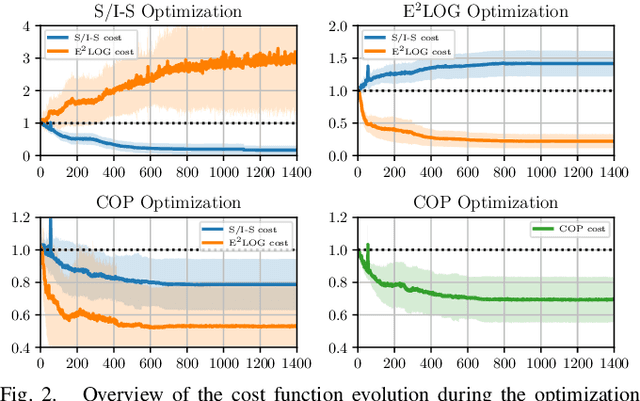
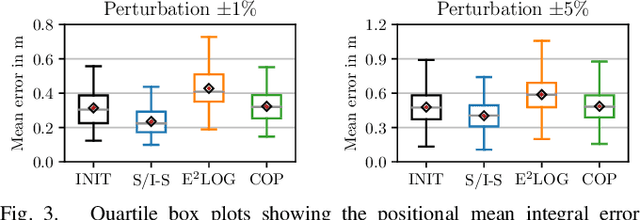
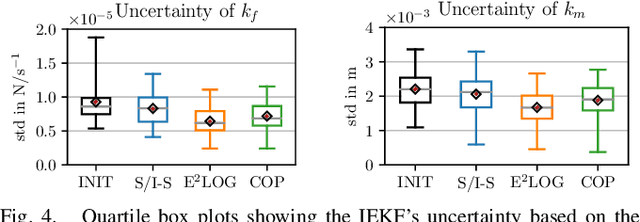
In this research, we aim to answer the question: How to combine Closed-Loop State and Input Sensitivity-based with Observability-aware trajectory planning? These possibly opposite optimization objectives can be used to improve trajectory control tracking and, at the same time, estimation performance. Our proposed novel Control & Observability-aware Planning (COP) framework is the first that uses these possibly opposing objectives in a Single-Objective Optimization Problem (SOOP) based on the Augmented Weighted Tchebycheff method to perform the balancing of them and generation of B\'ezier curve-based trajectories. Statistically relevant simulations for a 3D quadrotor unmanned aerial vehicle (UAV) case study produce results that support our claims and show the negative correlation between both objectives. We were able to reduce the positional mean integral error norm as well as the estimation uncertainty with the same trajectory to comparable levels of the trajectories optimized with individual objectives.
Human-in-the-loop optimisation: mixed initiative grasping for optimally facilitating post-grasp manipulative actions
Jul 25, 2017
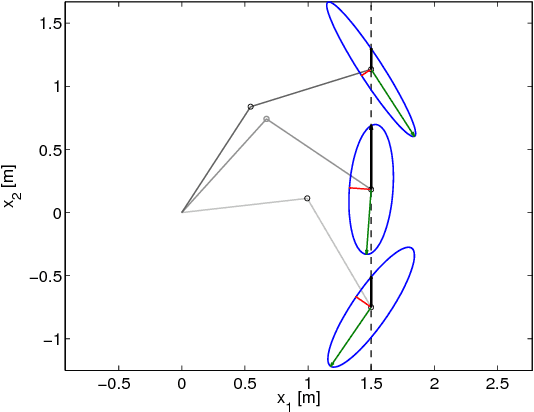
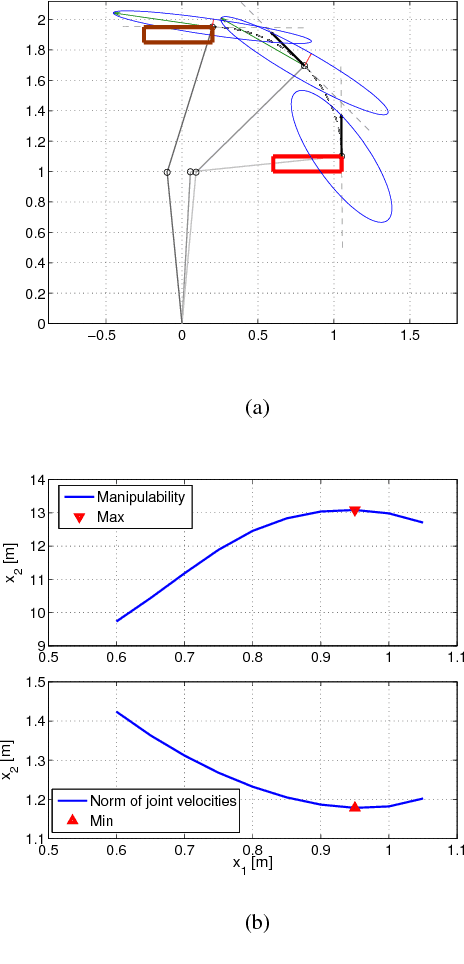
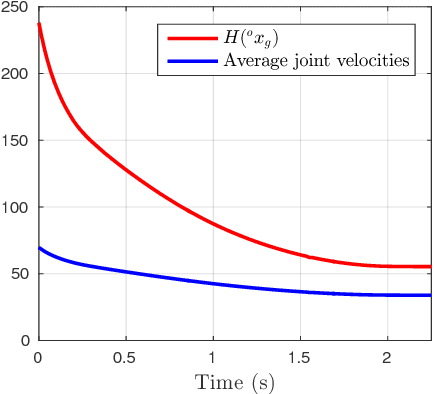
This paper addresses the problem of mixed initiative, shared control for master-slave grasping and manipulation. We propose a novel system, in which an autonomous agent assists a human in teleoperating a remote slave arm/gripper, using a haptic master device. Our system is designed to exploit the human operator's expertise in selecting stable grasps (still an open research topic in autonomous robotics). Meanwhile, a-priori knowledge of: i) the slave robot kinematics, and ii) the desired post-grasp manipulative trajectory, are fed to an autonomous agent which transmits force cues to the human, to encourage maximally manipulable grasp pose selections. Specifically, the autonomous agent provides force cues to the human, during the reach-to-grasp phase, which encourage the human to select grasp poses which maximise manipulation capability during the post-grasp object manipulation phase. We introduce a task-relevant velocity manipulability cost function (TOV), which is used to identify the maximum kinematic capability of a manipulator during post-grasp motions, and feed this back as force cues to the human during the pre-grasp phase. We show that grasps which minimise TOV result in significantly reduced control effort of the manipulator, compared to other feasible grasps. We demonstrate the effectiveness of our approach by experiments with both real and simulated robots.
Decentralized Simultaneous Multi-target Exploration using a Connected Network of Multiple Robots
Mar 16, 2017
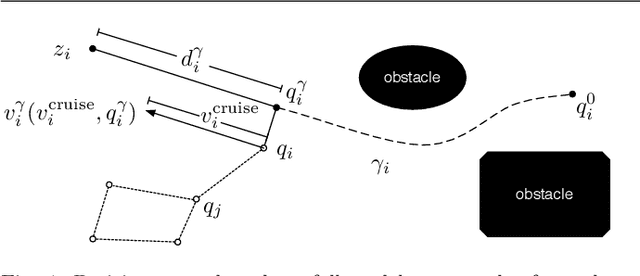
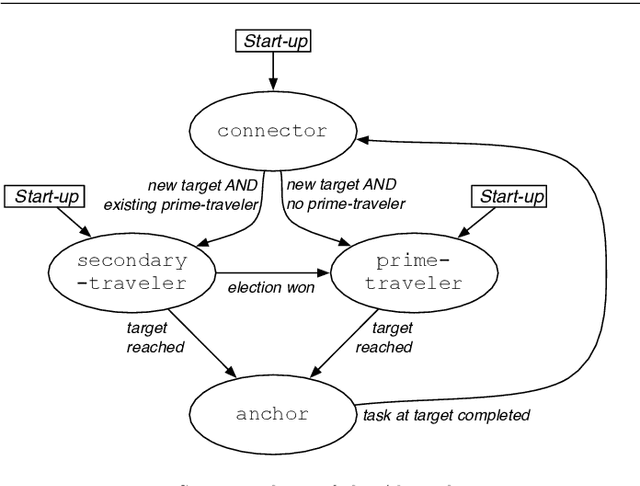
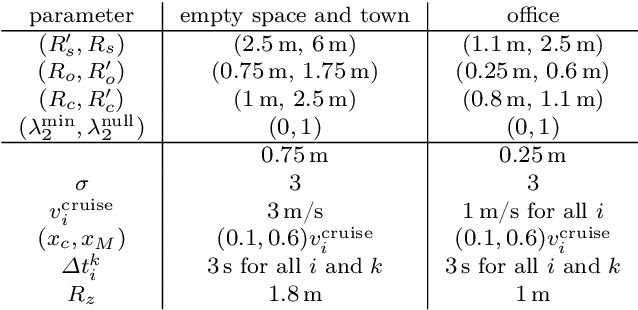
This paper presents a novel decentralized control strategy for a multi-robot system that enables parallel multi-target exploration while ensuring a time-varying connected topology in cluttered 3D environments. Flexible continuous connectivity is guaranteed by building upon a recent connectivity maintenance method, in which limited range, line-of-sight visibility, and collision avoidance are taken into account at the same time. Completeness of the decentralized multi-target exploration algorithm is guaranteed by dynamically assigning the robots with different motion behaviors during the exploration task. One major group is subject to a suitable downscaling of the main traveling force based on the traveling efficiency of the current leader and the direction alignment between traveling and connectivity force. This supports the leader in always reaching its current target and, on a larger time horizon, that the whole team realizes the overall task in finite time. Extensive Monte~Carlo simulations with a group of several quadrotor UAVs show the scalability and effectiveness of the proposed method and experiments validate its practicability.
Decentralized Rigidity Maintenance Control with Range Measurements for Multi-Robot Systems
Sep 04, 2014
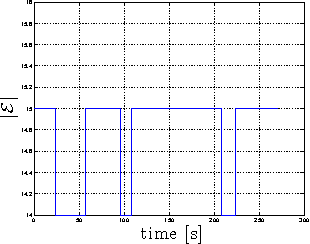
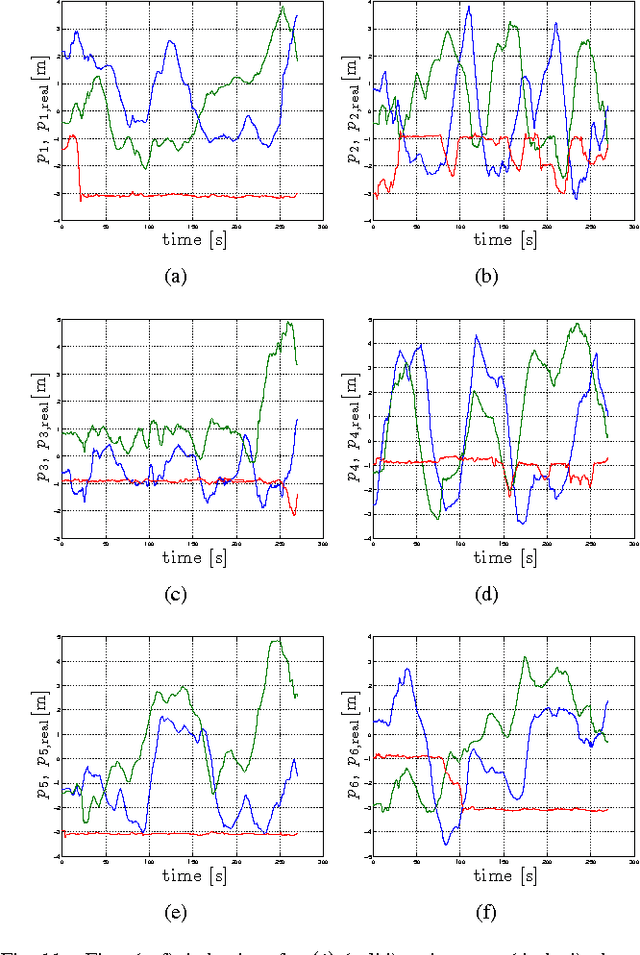
This work proposes a fully decentralized strategy for maintaining the formation rigidity of a multi-robot system using only range measurements, while still allowing the graph topology to change freely over time. In this direction, a first contribution of this work is an extension of rigidity theory to weighted frameworks and the rigidity eigenvalue, which when positive ensures the infinitesimal rigidity of the framework. We then propose a distributed algorithm for estimating a common relative position reference frame amongst a team of robots with only range measurements in addition to one agent endowed with the capability of measuring the bearing to two other agents. This first estimation step is embedded into a subsequent distributed algorithm for estimating the rigidity eigenvalue associated with the weighted framework. The estimate of the rigidity eigenvalue is finally used to generate a local control action for each agent that both maintains the rigidity property and enforces additional con- straints such as collision avoidance and sensing/communication range limits and occlusions. As an additional feature of our approach, the communication and sensing links among the robots are also left free to change over time while preserving rigidity of the whole framework. The proposed scheme is then experimentally validated with a robotic testbed consisting of 6 quadrotor UAVs operating in a cluttered environment.