 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM networks provide efficient cyanobacterial blooms forecasting even with incomplete spatio-temporal data
Oct 09, 2024



Cyanobacteria are the most frequent dominant species of algal blooms in inland waters, threatening ecosystem function and water quality, especially when toxin-producing strains predominate. Enhanced by anthropogenic activities and global warming, cyanobacterial blooms are expected to increase in frequency and global distribution. Early warning systems (EWS) for cyanobacterial blooms development allow timely implementation of management measures, reducing the risks associated to these blooms. In this paper, we propose an effective EWS for cyanobacterial bloom forecasting, which uses 6 years of incomplete high-frequency spatio-temporal data from multiparametric probes, including phycocyanin (PC) fluorescence as a proxy for cyanobacteria. A probe agnostic and replicable method is proposed to pre-process the data and to generate time series specific for cyanobacterial bloom forecasting. Using these pre-processed data, six different non-site/species-specific predictive models were compared including the autoregressive and multivariate versions of Linear Regression, Random Forest, and Long-Term Short-Term (LSTM) neural networks. Results were analyzed for seven forecasting time horizons ranging from 4 to 28 days evaluated with a hybrid system that combined regression metrics (MSE, R2, MAPE) for PC values, classification metrics (Accuracy, F1, Kappa) for a proposed alarm level of 10 ug PC/L, and a forecasting-specific metric to measure prediction improvement over the displaced signal (skill). The multivariate version of LSTM showed the best and most consistent results across all forecasting horizons and metrics, achieving accuracies of up to 90% in predicting the proposed PC alarm level. Additionally, positive skill values indicated its outstanding effectiveness to forecast cyanobacterial blooms from 16 to 28 days in advance.
Neural Policy Style Transfer
Feb 01, 2024



Style Transfer has been proposed in a number of fields: fine arts, natural language processing, and fixed trajectories. We scale this concept up to control policies within a Deep Reinforcement Learning infrastructure. Each network is trained to maximize the expected reward, which typically encodes the goal of an action, and can be described as the content. The expressive power of deep neural networks enables encoding a secondary task, which can be described as the style. The Neural Policy Style Transfer (NPST) algorithm is proposed to transfer the style of one policy to another, while maintaining the content of the latter. Different policies are defined via Deep Q-Network architectures. These models are trained using demonstrations through Inverse Reinforcement Learning. Two different sets of user demonstrations are performed, one for content and other for style. Different styles are encoded as defined by user demonstrations. The generated policy is the result of feeding a content policy and a style policy to the NPST algorithm. Experiments are performed in a catch-ball game inspired by the Deep Reinforcement Learning classical Atari games; and a real-world painting scenario with a full-sized humanoid robot, based on previous works of the authors. The implementation of three different Q-Network architectures (Shallow, Deep and Deep Recurrent Q-Network) to encode the policies within the NPST framework is proposed and the results obtained in the experiments with each of these architectures compared.
Transferring human emotions to robot motions using Neural Policy Style Transfer
Feb 01, 2024

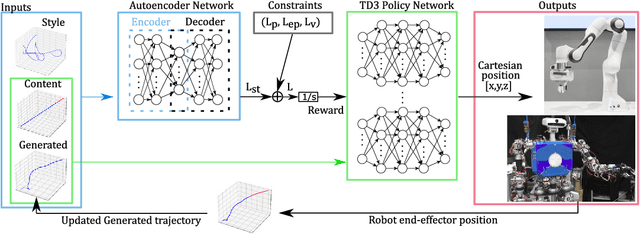
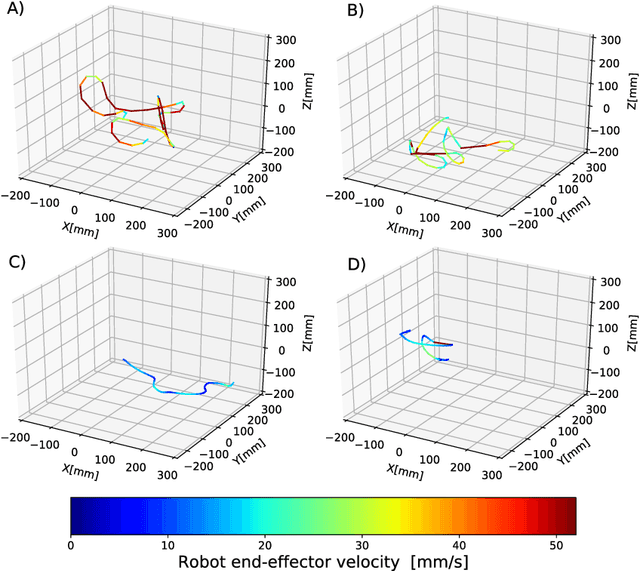
Neural Style Transfer (NST) was originally proposed to use feature extraction capabilities of Neural Networks as a way to perform Style Transfer with images. Pre-trained image classification architectures were selected for feature extraction, leading to new images showing the same content as the original but with a different style. In robotics, Style Transfer can be employed to transfer human motion styles to robot motions. The challenge lies in the lack of pre-trained classification architectures for robot motions that could be used for feature extraction. Neural Policy Style Transfer TD3 (NPST3) is proposed for the transfer of human motion styles to robot motions. This framework allows the same robot motion to be executed in different human-centered motion styles, such as in an angry, happy, calm, or sad fashion. The Twin Delayed Deep Deterministic Policy Gradient (TD3) network is introduced for the generation of control policies. An autoencoder network is in charge of feature extraction for the Style Transfer step. The Style Transfer step can be performed both offline and online: offline for the autonomous executions of human-style robot motions, and online for adapting at runtime the style of e.g., a teleoperated robot. The framework is tested using two different robotic platforms: a robotic manipulator designed for telemanipulation tasks, and a humanoid robot designed for social interaction. The proposed approach was evaluated for both platforms, performing a total of 147 questionnaires asking human subjects to recognize the human motion style transferred to the robot motion for a predefined set of actions.
Neural Style Transfer with Twin-Delayed DDPG for Shared Control of Robotic Manipulators
Feb 01, 2024
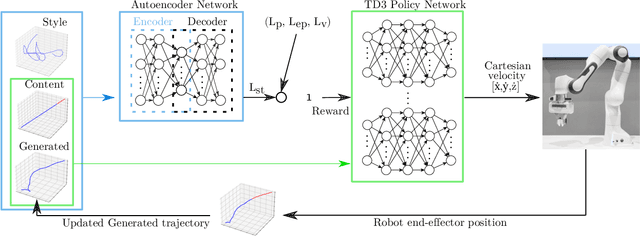
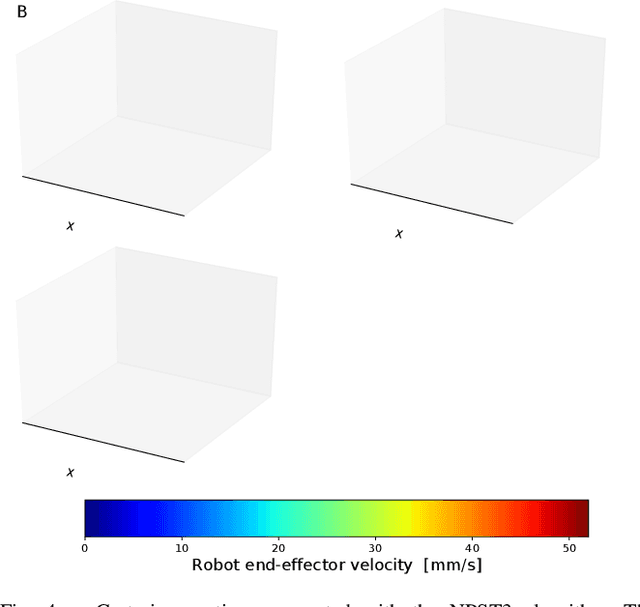
Neural Style Transfer (NST) refers to a class of algorithms able to manipulate an element, most often images, to adopt the appearance or style of another one. Each element is defined as a combination of Content and Style: the Content can be conceptually defined as the what and the Style as the how of said element. In this context, we propose a custom NST framework for transferring a set of styles to the motion of a robotic manipulator, e.g., the same robotic task can be carried out in an angry, happy, calm, or sad way. An autoencoder architecture extracts and defines the Content and the Style of the target robot motions. A Twin Delayed Deep Deterministic Policy Gradient (TD3) network generates the robot control policy using the loss defined by the autoencoder. The proposed Neural Policy Style Transfer TD3 (NPST3) alters the robot motion by introducing the trained style. Such an approach can be implemented either offline, for carrying out autonomous robot motions in dynamic environments, or online, for adapting at runtime the style of a teleoperated robot. The considered styles can be learned online from human demonstrations. We carried out an evaluation with human subjects enrolling 73 volunteers, asking them to recognize the style behind some representative robotic motions. Results show a good recognition rate, proving that it is possible to convey different styles to a robot using this approach.
Real Evaluations Tractability using Continuous Goal-Directed Actions in Smart City Applications
Feb 01, 2024One of the most important challenges of Smart City Applications is to adapt the system to interact with non-expert users. Robot imitation frameworks aim to simplify and reduce times of robot programming by allowing users to program directly through demonstrations. In classical frameworks, actions are modeled using joint or Cartesian space trajectories. Other features, such as visual ones, are not always well represented with these pure geometrical approaches. Continuous Goal-Directed Actions (CGDA) is an alternative to these methods, as it encodes actions as changes of any feature that can be extracted from the environment. As a consequence of this, the robot joint trajectories for execution must be fully computed to comply with this feature-agnostic encoding. This is achieved using Evolutionary Algorithms (EA), which usually requires too many evaluations to perform this evolution step in the actual robot. Current strategies involve performing evaluations in a simulation, transferring the final joint trajectory to the actual robot. Smart City applications involve working in highly dynamic and complex environments, where having a precise model is not always achievable. Our goal is to study the tractability of performing these evaluations directly in a real-world scenario. Two different approaches to reduce the number of evaluations using EA, are proposed and compared. In the first approach, Particle Swarm Optimization (PSO)-based methods have been studied and compared within CGDA: naive PSO, Fitness Inheritance PSO (FI-PSO), and Adaptive Fuzzy Fitness Granulation with PSO (AFFG-PSO). The second approach studied the introduction of geometrical and velocity constraints within CGDA. The effects of both approaches were analyzed and compared in the wax and paint actions, two CGDA commonly studied use cases. Results from this paper depict an important reduction in the number of evaluations.
Deep Robot Sketching: An application of Deep Q-Learning Networks for human-like sketching
Feb 01, 2024The current success of Reinforcement Learning algorithms for its performance in complex environments has inspired many recent theoretical approaches to cognitive science. Artistic environments are studied within the cognitive science community as rich, natural, multi-sensory, multi-cultural environments. In this work, we propose the introduction of Reinforcement Learning for improving the control of artistic robot applications. Deep Q-learning Neural Networks (DQN) is one of the most successful algorithms for the implementation of Reinforcement Learning in robotics. DQN methods generate complex control policies for the execution of complex robot applications in a wide set of environments. Current art painting robot applications use simple control laws that limits the adaptability of the frameworks to a set of simple environments. In this work, the introduction of DQN within an art painting robot application is proposed. The goal is to study how the introduction of a complex control policy impacts the performance of a basic art painting robot application. The main expected contribution of this work is to serve as a first baseline for future works introducing DQN methods for complex art painting robot frameworks. Experiments consist of real world executions of human drawn sketches using the DQN generated policy and TEO, the humanoid robot. Results are compared in terms of similarity and obtained reward with respect to the reference inputs
Quick, Stat!: A Statistical Analysis of the Quick, Draw! Dataset
Jul 15, 2019
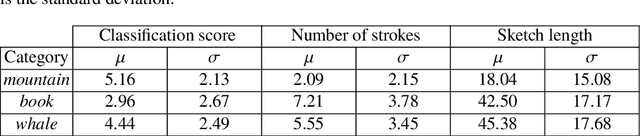


The Quick, Draw! Dataset is a Google dataset with a collection of 50 million drawings, divided in 345 categories, collected from the users of the game Quick, Draw!. In contrast with most of the existing image datasets, in the Quick, Draw! Dataset, drawings are stored as time series of pencil positions instead of a bitmap matrix composed by pixels. This aspect makes this dataset the largest doodle dataset available at the time. The Quick, Draw! Dataset is presented as a great opportunity to researchers for developing and studying machine learning techniques. Due to the size of this dataset and the nature of its source, there is a scarce of information about the quality of the drawings contained. In this paper, a statistical analysis of three of the classes contained in the Quick, Draw! Dataset is depicted: mountain, book and whale. The goal is to give to the reader a first impression of the data collected in this dataset. For the analysis of the quality of the drawings, a Classification Neural Network was trained to obtain a classification score. Using this classification score and the parameters provided by the dataset, a statistical analysis of the quality and nature of the drawings contained in this dataset is provided.
Robot Imitation through Vision, Kinesthetic and Force Features with Online Adaptation to Changing Environments
Oct 30, 2018

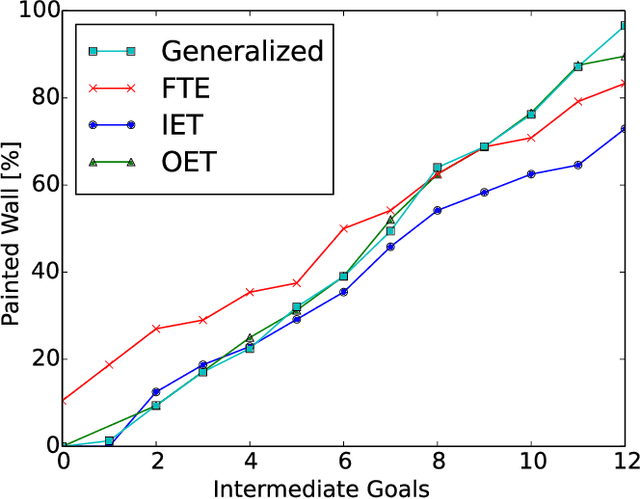

Continuous Goal-Directed Actions (CGDA) is a robot imitation framework that encodes actions as the changes they produce on the environment. While it presents numerous advantages with respect to other robot imitation frameworks in terms of generalization and portability, final robot joint trajectories for the execution of actions are not necessarily encoded within the model. This is studied as an optimization problem, and the solution is computed through evolutionary algorithms in simulated environments. Evolutionary algorithms require a large number of evaluations, which had made the use of these algorithms in real world applications very challenging. This paper presents online evolutionary strategies, as a change of paradigm within CGDA execution. Online evolutionary strategies shift and merge motor execution into the planning loop. A concrete online evolutionary strategy, Online Evolved Trajectories (OET), is presented. OET drastically reduces computational times between motor executions, and enables working in real world dynamic environments and/or with human collaboration. Its performance has been measured against Full Trajectory Evolution (FTE) and Incrementally Evolved Trajectories (IET), obtaining the best overall results. Experimental evaluations are performed on the TEO full-sized humanoid robot with "paint" and "iron" actions that together involve vision, kinesthetic and force features.
Robotic Ironing with 3D Perception and Force/Torque Feedback in Household Environments
Jun 16, 2017

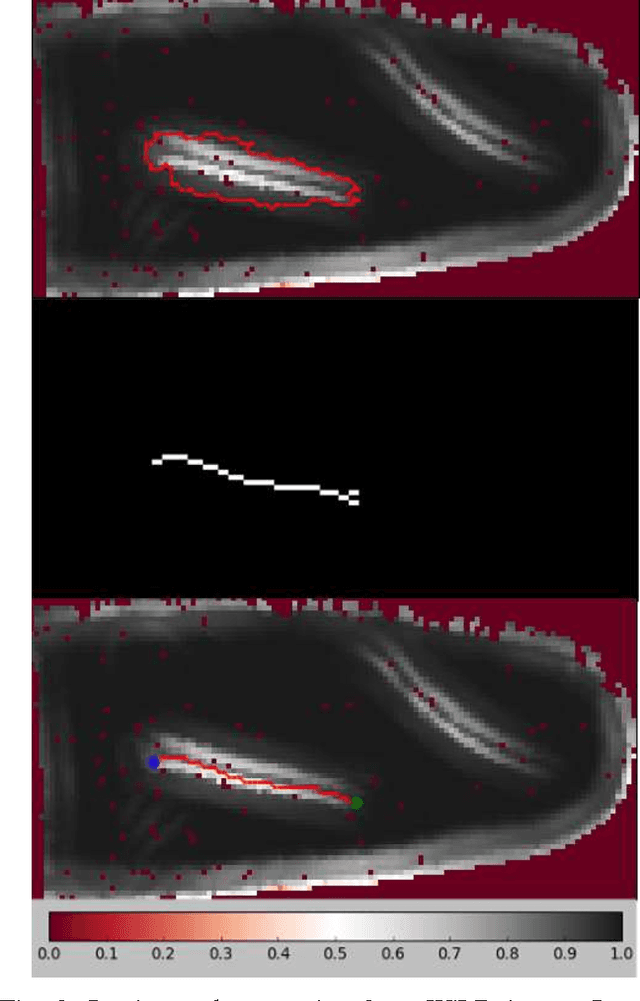
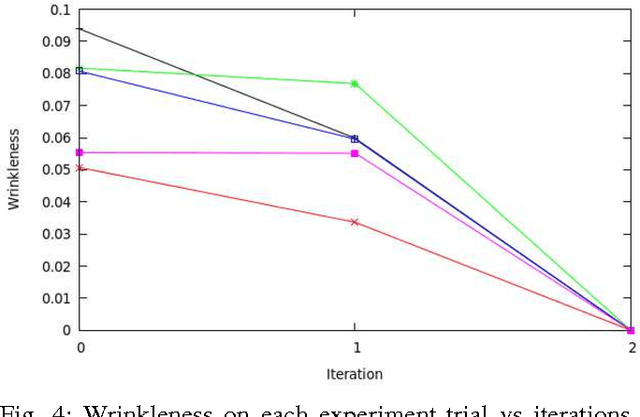
As robotic systems become more popular in household environments, the complexity of required tasks also increases. In this work we focus on a domestic chore deemed dull by a majority of the population, the task of ironing. The presented algorithm improves on the limited number of previous works by joining 3D perception with force/torque sensing, with emphasis on finding a practical solution with a feasible implementation in a domestic setting. Our algorithm obtains a point cloud representation of the working environment. From this point cloud, the garment is segmented and a custom Wrinkleness Local Descriptor (WiLD) is computed to determine the location of the present wrinkles. Using this descriptor, the most suitable ironing path is computed and, based on it, the manipulation algorithm performs the force-controlled ironing operation. Experiments have been performed with a humanoid robot platform, proving that our algorithm is able to detect successfully wrinkles present in garments and iteratively reduce the wrinkleness using an unmodified iron.