 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperQA: Retrieval-Augmented Generative Agent for Scientific Research
Dec 14, 2023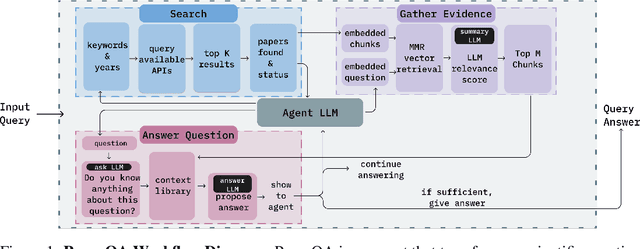



Large Language Models (LLMs) generalize well across language tasks, but suffer from hallucinations and uninterpretability, making it difficult to assess their accuracy without ground-truth. Retrieval-Augmented Generation (RAG) models have been proposed to reduce hallucinations and provide provenance for how an answer was generated. Applying such models to the scientific literature may enable large-scale, systematic processing of scientific knowledge. We present PaperQA, a RAG agent for answering questions over the scientific literature. PaperQA is an agent that performs information retrieval across full-text scientific articles, assesses the relevance of sources and passages, and uses RAG to provide answers. Viewing this agent as a question answering model, we find it exceeds performance of existing LLMs and LLM agents on current science QA benchmarks. To push the field closer to how humans perform research on scientific literature, we also introduce LitQA, a more complex benchmark that requires retrieval and synthesis of information from full-text scientific papers across the literature. Finally, we demonstrate PaperQA's matches expert human researchers on LitQA.
BioPlanner: Automatic Evaluation of LLMs on Protocol Planning in Biology
Oct 16, 2023



The ability to automatically generate accurate protocols for scientific experiments would represent a major step towards the automation of science. Large Language Models (LLMs) have impressive capabilities on a wide range of tasks, such as question answering and the generation of coherent text and code. However, LLMs can struggle with multi-step problems and long-term planning, which are crucial for designing scientific experiments. Moreover, evaluation of the accuracy of scientific protocols is challenging, because experiments can be described correctly in many different ways, require expert knowledge to evaluate, and cannot usually be executed automatically. Here we present an automatic evaluation framework for the task of planning experimental protocols, and we introduce BioProt: a dataset of biology protocols with corresponding pseudocode representations. To measure performance on generating scientific protocols, we use an LLM to convert a natural language protocol into pseudocode, and then evaluate an LLM's ability to reconstruct the pseudocode from a high-level description and a list of admissible pseudocode functions. We evaluate GPT-3 and GPT-4 on this task and explore their robustness. We externally validate the utility of pseudocode representations of text by generating accurate novel protocols using retrieved pseudocode, and we run a generated protocol successfully in our biological laboratory. Our framework is extensible to the evaluation and improvement of language model planning abilities in other areas of science or other areas that lack automatic evaluation.
COPER: Continuous Patient State Perceiver
Aug 05, 2022

In electronic health records (EHRs), irregular time-series (ITS) occur naturally due to patient health dynamics, reflected by irregular hospital visits, diseases/conditions and the necessity to measure different vitals signs at each visit etc. ITS present challenges in training machine learning algorithms which mostly are built on assumption of coherent fixed dimensional feature space. In this paper, we propose a novel COntinuous patient state PERceiver model, called COPER, to cope with ITS in EHRs. COPER uses Perceiver model and the concept of neural ordinary differential equations (ODEs) to learn the continuous time dynamics of patient state, i.e., continuity of input space and continuity of output space. The neural ODEs help COPER to generate regular time-series to feed to Perceiver model which has the capability to handle multi-modality large-scale inputs. To evaluate the performance of the proposed model, we use in-hospital mortality prediction task on MIMIC-III dataset and carefully design experiments to study irregularity. The results are compared with the baselines which prove the efficacy of the proposed model.
Deep Reinforcement Learning for Multi-class Imbalanced Training
May 24, 2022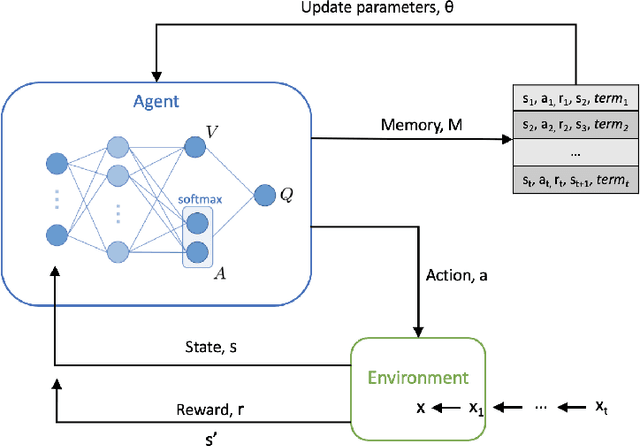


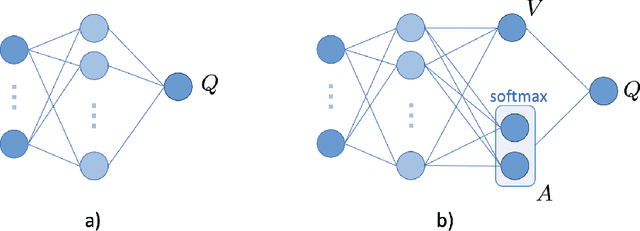
With the rapid growth of memory and computing power, datasets are becoming increasingly complex and imbalanced. This is especially severe in the context of clinical data, where there may be one rare event for many cases in the majority class. We introduce an imbalanced classification framework, based on reinforcement learning, for training extremely imbalanced data sets, and extend it for use in multi-class settings. We combine dueling and double deep Q-learning architectures, and formulate a custom reward function and episode-training procedure, specifically with the added capability of handling multi-class imbalanced training. Using real-world clinical case studies, we demonstrate that our proposed framework outperforms current state-of-the-art imbalanced learning methods, achieving more fair and balanced classification, while also significantly improving the prediction of minority classes.
Invariant Risk Minimisation for Cross-Organism Inference: Substituting Mouse Data for Human Data in Human Risk Factor Discovery
Nov 14, 2021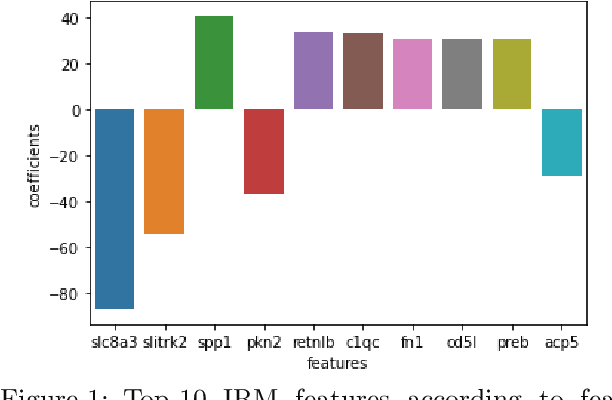
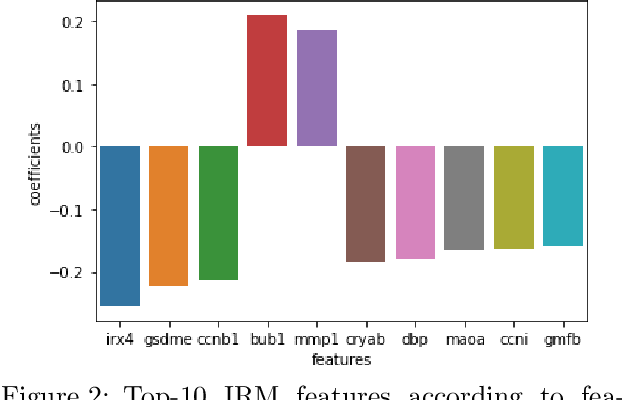
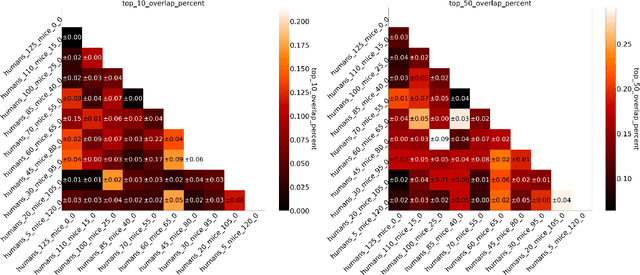
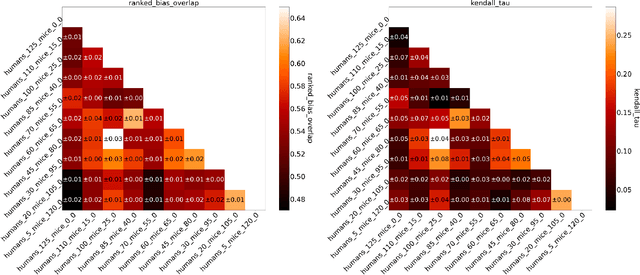
Human medical data can be challenging to obtain due to data privacy concerns, difficulties conducting certain types of experiments, or prohibitive associated costs. In many settings, data from animal models or in-vitro cell lines are available to help augment our understanding of human data. However, this data is known for having low etiological validity in comparison to human data. In this work, we augment small human medical datasets with in-vitro data and animal models. We use Invariant Risk Minimisation (IRM) to elucidate invariant features by considering cross-organism data as belonging to different data-generating environments. Our models identify genes of relevance to human cancer development. We observe a degree of consistency between varying the amounts of human and mouse data used, however, further work is required to obtain conclusive insights. As a secondary contribution, we enhance existing open source datasets and provide two uniformly processed, cross-organism, homologue gene-matched datasets to the community.