 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Learning from Scarce Data via Multi-Task Constrained Optimization
Nov 17, 2025A learning task, understood as the problem of fitting a parametric model from supervised data, fundamentally requires the dataset to be large enough to be representative of the underlying distribution of the source. When data is limited, the learned models fail generalize to cases not seen during training. This paper introduces a multi-task \emph{cross-learning} framework to overcome data scarcity by jointly estimating \emph{deterministic} parameters across multiple, related tasks. We formulate this joint estimation as a constrained optimization problem, where the constraints dictate the resulting similarity between the parameters of the different models, allowing the estimated parameters to differ across tasks while still combining information from multiple data sources. This framework enables knowledge transfer from tasks with abundant data to those with scarce data, leading to more accurate and reliable parameter estimates, providing a solution for scenarios where parameter inference from limited data is critical. We provide theoretical guarantees in a controlled framework with Gaussian data, and show the efficiency of our cross-learning method in applications with real data including image classification and propagation of infectious diseases.
Multi-agent assignment via state augmented reinforcement learning
Jun 03, 2024
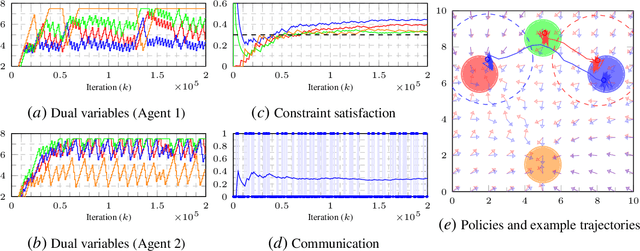
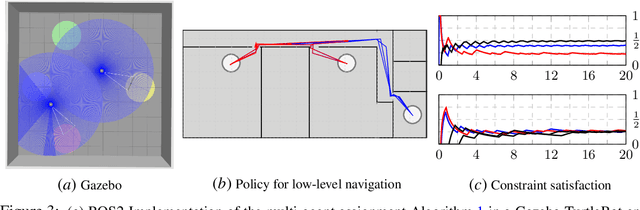
We address the conflicting requirements of a multi-agent assignment problem through constrained reinforcement learning, emphasizing the inadequacy of standard regularization techniques for this purpose. Instead, we recur to a state augmentation approach in which the oscillation of dual variables is exploited by agents to alternate between tasks. In addition, we coordinate the actions of the multiple agents acting on their local states through these multipliers, which are gossiped through a communication network, eliminating the need to access other agent states. By these means, we propose a distributed multi-agent assignment protocol with theoretical feasibility guarantees that we corroborate in a monitoring numerical experiment.
* 12 pages, 3 figures, 6th Annual Conference on Learning for Dynamics and Control
A Networked Multi-Agent System for Mobile Wireless Infrastructure on Demand
Jun 14, 2023



Despite the prevalence of wireless connectivity in urban areas around the globe, there remain numerous and diverse situations where connectivity is insufficient or unavailable. To address this, we introduce mobile wireless infrastructure on demand, a system of UAVs that can be rapidly deployed to establish an ad-hoc wireless network. This network has the capability of reconfiguring itself dynamically to satisfy and maintain the required quality of communication. The system optimizes the positions of the UAVs and the routing of data flows throughout the network to achieve this quality of service (QoS). By these means, task agents using the network simply request a desired QoS, and the system adapts accordingly while allowing them to move freely. We have validated this system both in simulation and in real-world experiments. The results demonstrate that our system effectively offers mobile wireless infrastructure on demand, extending the operational range of task agents and supporting complex mobility patterns, all while ensuring connectivity and being resilient to agent failures.
Mission-Aware Value of Information Censoring for Distributed Filtering
Nov 20, 2022In this paper, we study the problem of distributed estimation with an emphasis on communication-efficiency. The proposed algorithm is based on a windowed maximum a posteriori (MAP) estimation problem, wherein each agent in the network locally computes a Kalman-like filter estimate that approximates the centralized MAP solution. Information sharing among agents is restricted to their neighbors only, with guarantees on overall estimate consistency provided via logarithmic opinion pooling. The problem is efficiently distributed using the alternating direction method of multipliers (ADMM), whose overall communication usage is further reduced by a value of information (VoI) censoring mechanism, wherein agents only transmit their primal-dual iterates when deemed valuable to do so. The proposed censoring mechanism is mission-aware, enabling a globally efficient use of communication resources while guaranteeing possibly different local estimation requirements. To illustrate the validity of the approach we perform simulations in a target tracking scenario.
Multi-task Bias-Variance Trade-off Through Functional Constraints
Oct 27, 2022


Multi-task learning aims to acquire a set of functions, either regressors or classifiers, that perform well for diverse tasks. At its core, the idea behind multi-task learning is to exploit the intrinsic similarity across data sources to aid in the learning process for each individual domain. In this paper we draw intuition from the two extreme learning scenarios -- a single function for all tasks, and a task-specific function that ignores the other tasks dependencies -- to propose a bias-variance trade-off. To control the relationship between the variance (given by the number of i.i.d. samples), and the bias (coming from data from other task), we introduce a constrained learning formulation that enforces domain specific solutions to be close to a central function. This problem is solved in the dual domain, for which we propose a stochastic primal-dual algorithm. Experimental results for a multi-domain classification problem with real data show that the proposed procedure outperforms both the task specific, as well as the single classifiers.
Distributed Filtering with Value of Information Censoring
Apr 01, 2022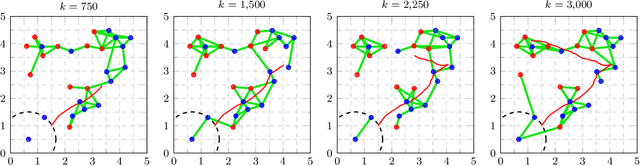
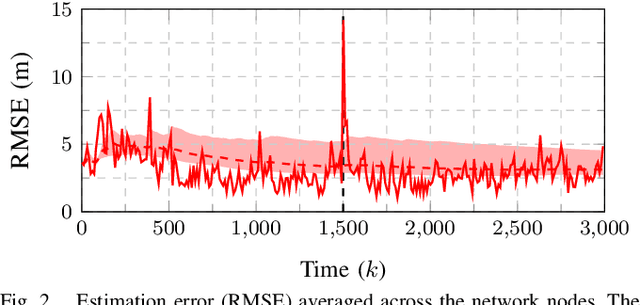

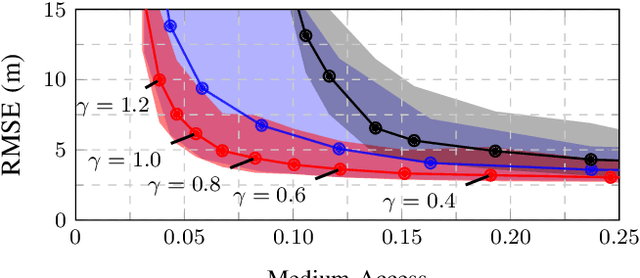
This work presents a distributed estimation algorithm that efficiently uses the available communication resources. The approach is based on Bayesian filtering that is distributed across a network by using the logarithmic opinion pool operator. Communication efficiency is achieved by having only agents with high Value of Information (VoI) share their estimates, and the algorithm provides a tunable trade-off between communication resources and estimation error. Under linear-Gaussian models the algorithm takes the form of a censored distributed Information filter, which guarantees the consistency of agent estimates. Importantly, consistent estimates are shown to play a crucial role in enabling the large reductions in communication usage provided by the VoI censoring approach. We verify the performance of the proposed method via complex simulations in a dynamic network topology and by experimental validation over a real ad-hoc wireless communication network. The results show the validity of using the proposed method to drastically reduce the communication costs of distributed estimation tasks.
Distributed Riemannian Optimization with Lazy Communication for Collaborative Geometric Estimation
Mar 02, 2022
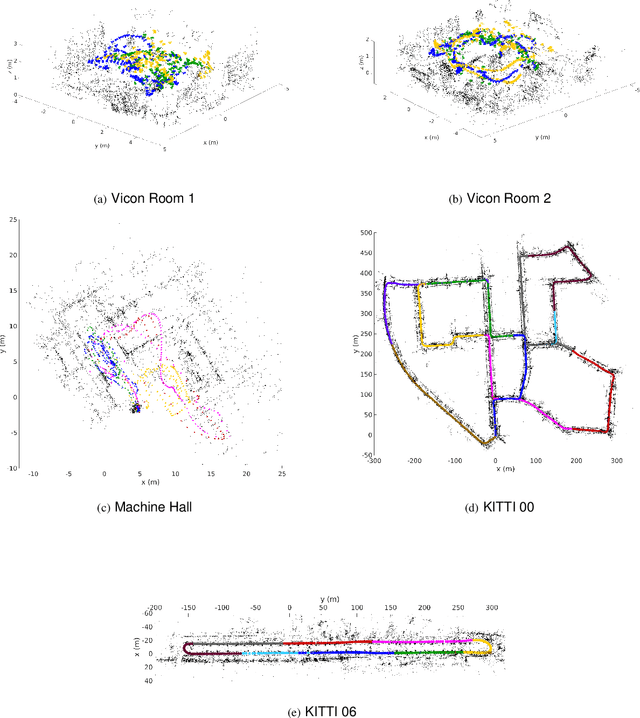


We present the first distributed optimization algorithm with lazy communication for collaborative geometric estimation, the backbone of modern collaborative simultaneous localization and mapping (SLAM) and structure-from-motion (SfM) applications. Our method allows agents to cooperatively reconstruct a shared geometric model on a central server by fusing individual observations, but without the need to transmit potentially sensitive information about the agents themselves (such as their locations). Furthermore, to alleviate the burden of communication during iterative optimization, we design a set of communication triggering conditions that enable agents to selectively upload local information that are useful to global optimization. Our approach thus achieves significant communication reduction with minimal impact on optimization performance. As our main theoretical contribution, we prove that our method converges to first-order critical points with a sublinear convergence rate. Numerical evaluations on bundle adjustment problems from collaborative SLAM and SfM datasets show that our method performs competitively against existing distributed techniques, while achieving up to 78% total communication reduction.
Constrained Learning with Non-Convex Losses
Mar 08, 2021

Though learning has become a core technology of modern information processing, there is now ample evidence that it can lead to biased, unsafe, and prejudiced solutions. The need to impose requirements on learning is therefore paramount, especially as it reaches critical applications in social, industrial, and medical domains. However, the non-convexity of most modern learning problems is only exacerbated by the introduction of constraints. Whereas good unconstrained solutions can often be learned using empirical risk minimization (ERM), even obtaining a model that satisfies statistical constraints can be challenging, all the more so a good one. In this paper, we overcome this issue by learning in the empirical dual domain, where constrained statistical learning problems become unconstrained, finite dimensional, and deterministic. We analyze the generalization properties of this approach by bounding the empirical duality gap, i.e., the difference between our approximate, tractable solution and the solution of the original (non-convex)~statistical problem, and provide a practical constrained learning algorithm. These results establish a constrained counterpart of classical learning theory and enable the explicit use of constraints in learning. We illustrate this algorithm and theory in rate-constrained learning applications.
Towards Safe Continuing Task Reinforcement Learning
Feb 24, 2021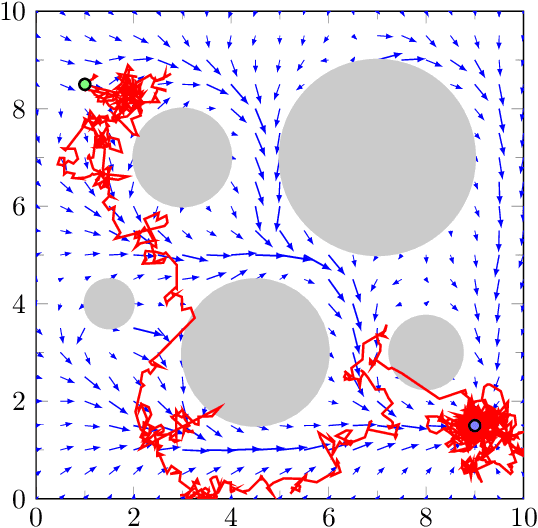

Safety is a critical feature of controller design for physical systems. When designing control policies, several approaches to guarantee this aspect of autonomy have been proposed, such as robust controllers or control barrier functions. However, these solutions strongly rely on the model of the system being available to the designer. As a parallel development, reinforcement learning provides model-agnostic control solutions but in general, it lacks the theoretical guarantees required for safety. Recent advances show that under mild conditions, control policies can be learned via reinforcement learning, which can be guaranteed to be safe by imposing these requirements as constraints of an optimization problem. However, to transfer from learning safety to learning safely, there are two hurdles that need to be overcome: (i) it has to be possible to learn the policy without having to re-initialize the system; and (ii) the rollouts of the system need to be in themselves safe. In this paper, we tackle the first issue, proposing an algorithm capable of operating in the continuing task setting without the need of restarts. We evaluate our approach in a numerical example, which shows the capabilities of the proposed approach in learning safe policies via safe exploration.
State Augmented Constrained Reinforcement Learning: Overcoming the Limitations of Learning with Rewards
Feb 23, 2021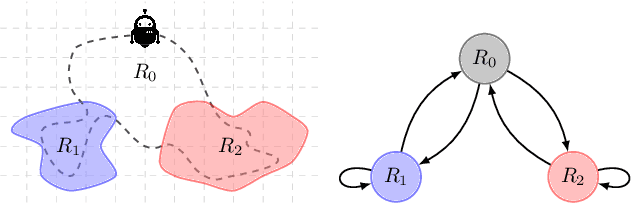



Constrained reinforcement learning involves multiple rewards that must individually accumulate to given thresholds. In this class of problems, we show a simple example in which the desired optimal policy cannot be induced by any linear combination of rewards. Hence, there exist constrained reinforcement learning problems for which neither regularized nor classical primal-dual methods yield optimal policies. This work addresses this shortcoming by augmenting the state with Lagrange multipliers and reinterpreting primal-dual methods as the portion of the dynamics that drives the multipliers evolution. This approach provides a systematic state augmentation procedure that is guaranteed to solve reinforcement learning problems with constraints. Thus, while primal-dual methods can fail at finding optimal policies, running the dual dynamics while executing the augmented policy yields an algorithm that provably samples actions from the optimal policy.