Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent assignment via state augmented reinforcement learning
Paper and Code
Jun 03, 2024
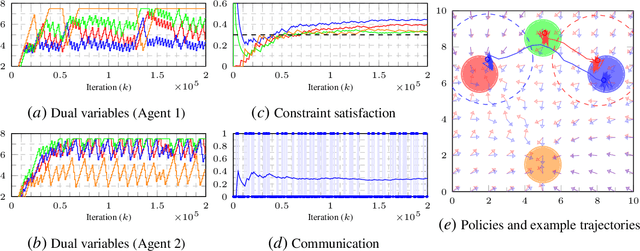
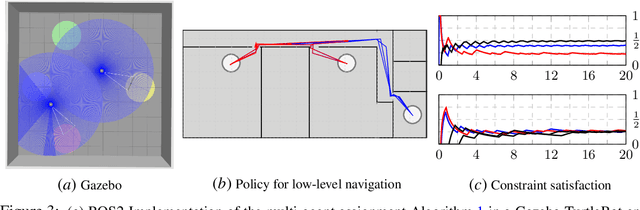
We address the conflicting requirements of a multi-agent assignment problem through constrained reinforcement learning, emphasizing the inadequacy of standard regularization techniques for this purpose. Instead, we recur to a state augmentation approach in which the oscillation of dual variables is exploited by agents to alternate between tasks. In addition, we coordinate the actions of the multiple agents acting on their local states through these multipliers, which are gossiped through a communication network, eliminating the need to access other agent states. By these means, we propose a distributed multi-agent assignment protocol with theoretical feasibility guarantees that we corroborate in a monitoring numerical experiment.
* Proceedings of Machine Learning Research vol 242 1 12, 2024. 6th
Annual Conference on Learning for Dynamics and Control * 12 pages, 3 figures, 6th Annual Conference on Learning for Dynamics
and Control
View paper on