 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Thematic Annotation: extracting concepts out of documents
Dec 30, 2004
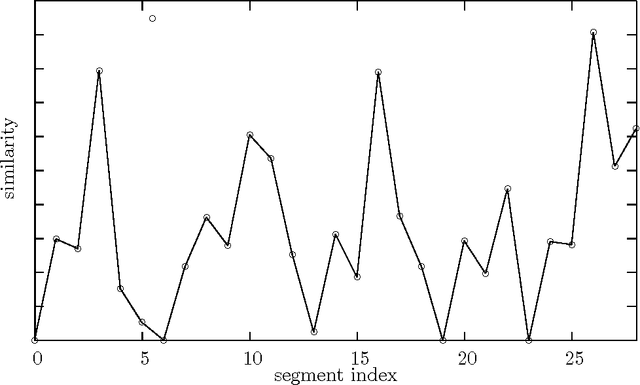
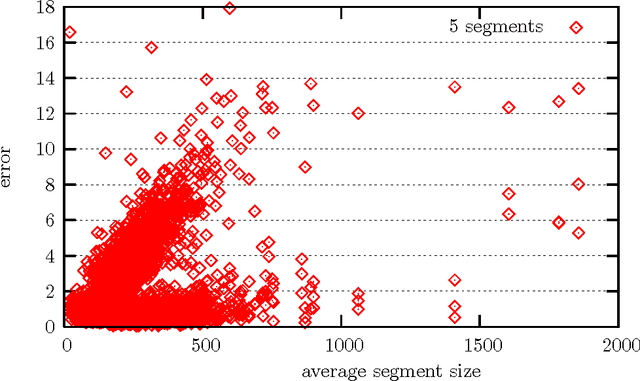
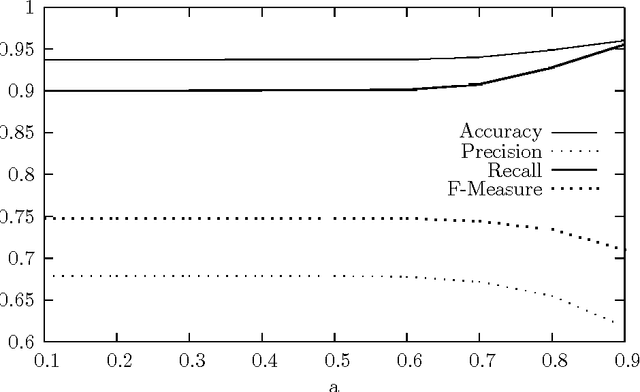
Contrarily to standard approaches to topic annotation, the technique used in this work does not centrally rely on some sort of -- possibly statistical -- keyword extraction. In fact, the proposed annotation algorithm uses a large scale semantic database -- the EDR Electronic Dictionary -- that provides a concept hierarchy based on hyponym and hypernym relations. This concept hierarchy is used to generate a synthetic representation of the document by aggregating the words present in topically homogeneous document segments into a set of concepts best preserving the document's content. This new extraction technique uses an unexplored approach to topic selection. Instead of using semantic similarity measures based on a semantic resource, the later is processed to extract the part of the conceptual hierarchy relevant to the document content. Then this conceptual hierarchy is searched to extract the most relevant set of concepts to represent the topics discussed in the document. Notice that this algorithm is able to extract generic concepts that are not directly present in the document.
State of the Art, Evaluation and Recommendations regarding "Document Processing and Visualization Techniques"
Dec 29, 2004


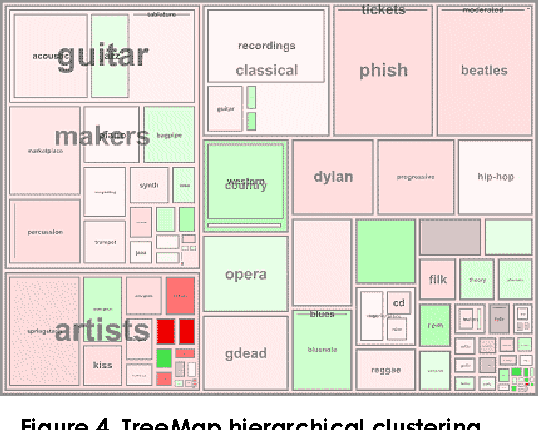
Several Networks of Excellence have been set up in the framework of the European FP5 research program. Among these Networks of Excellence, the NEMIS project focuses on the field of Text Mining. Within this field, document processing and visualization was identified as one of the key topics and the WG1 working group was created in the NEMIS project, to carry out a detailed survey of techniques associated with the text mining process and to identify the relevant research topics in related research areas. In this document we present the results of this comprehensive survey. The report includes a description of the current state-of-the-art and practice, a roadmap for follow-up research in the identified areas, and recommendations for anticipated technological development in the domain of text mining.
INSPIRE: Evaluation of a Smart-Home System for Infotainment Management and Device Control
Oct 25, 2004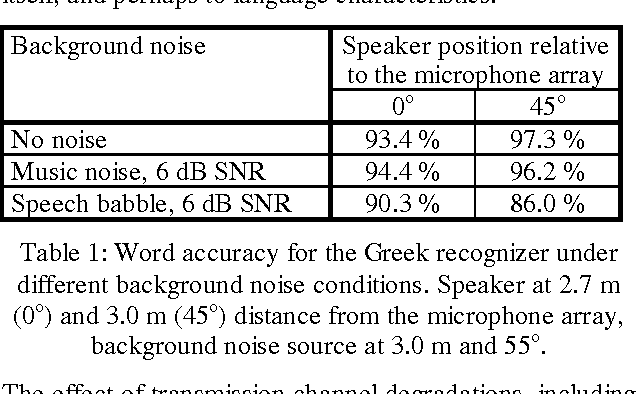
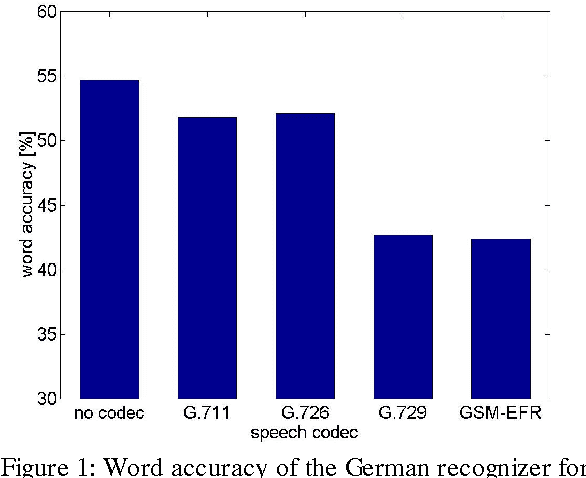
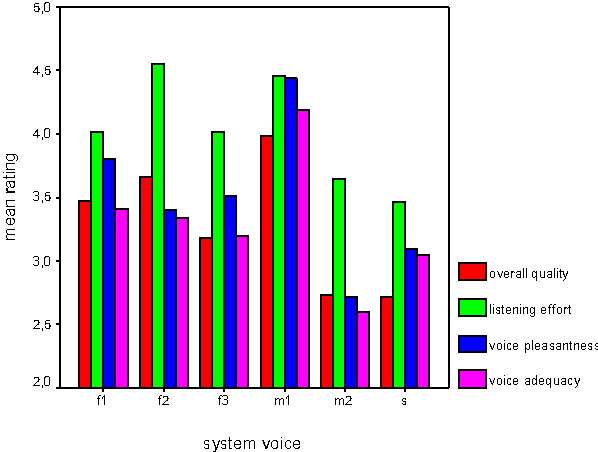
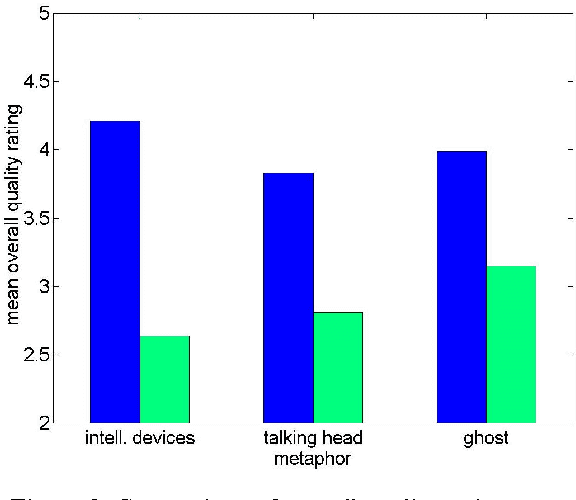
This paper gives an overview of the assessment and evaluation methods which have been used to determine the quality of the INSPIRE smart home system. The system allows different home appliances to be controlled via speech, and consists of speech and speaker recognition, speech understanding, dialogue management, and speech output components. The performance of these components is first assessed individually, and then the entire system is evaluated in an interaction experiment with test users. Initial results of the assessment and evaluation are given, in particular with respect to the transmission channel impact on speech and speaker recognition, and the assessment of speech output for different system metaphors.
* 4 pages
Automatic Keyword Extraction from Spoken Text. A Comparison of two Lexical Resources: the EDR and WordNet
Oct 25, 2004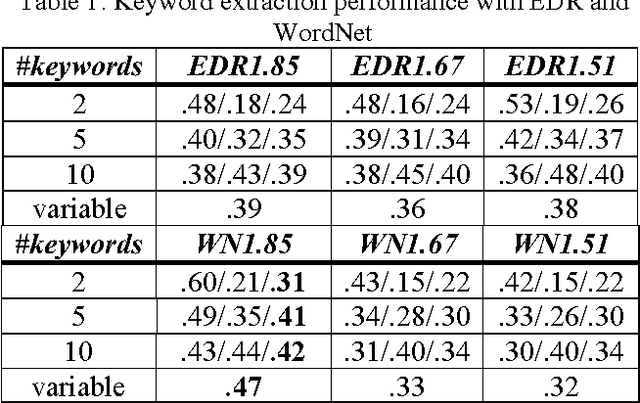
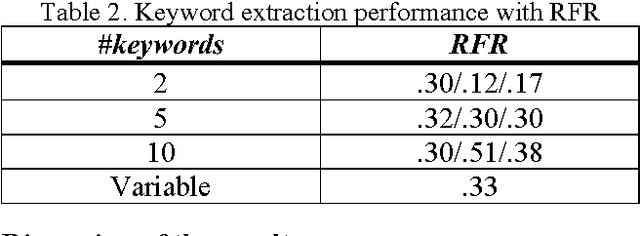
Lexical resources such as WordNet and the EDR electronic dictionary have been used in several NLP tasks. Probably, partly due to the fact that the EDR is not freely available, WordNet has been used far more often than the EDR. We have used both resources on the same task in order to make a comparison possible. The task is automatic assignment of keywords to multi-party dialogue episodes (i.e. thematically coherent stretches of spoken text). We show that the use of lexical resources in such a task results in slightly higher performances than the use of a purely statistically based method.
* 4 pages