 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Early Universe with Deep Learning
Sep 26, 2025Hydrogen is the most abundant element in our Universe. The first generation of stars and galaxies produced photons that ionized hydrogen gas, driving a cosmological event known as the Epoch of Reionization (EoR). The upcoming Square Kilometre Array Observatory (SKAO) will map the distribution of neutral hydrogen during this era, aiding in the study of the properties of these first-generation objects. Extracting astrophysical information will be challenging, as SKAO will produce a tremendous amount of data where the hydrogen signal will be contaminated with undesired foreground contamination and instrumental systematics. To address this, we develop the latest deep learning techniques to extract information from the 2D power spectra of the hydrogen signal expected from SKAO. We apply a series of neural network models to these measurements and quantify their ability to predict the history of cosmic hydrogen reionization, which is connected to the increasing number and efficiency of early photon sources. We show that the study of the early Universe benefits from modern deep learning technology. In particular, we demonstrate that dedicated machine learning algorithms can achieve more than a $0.95$ $R^2$ score on average in recovering the reionization history. This enables accurate and precise cosmological and astrophysical inference of structure formation in the early Universe.
* EPIA 2025 preprint version, 12 pages, 3 figures
Workload Prediction of Business Processes -- An Approach Based on Process Mining and Recurrent Neural Networks
Feb 14, 2020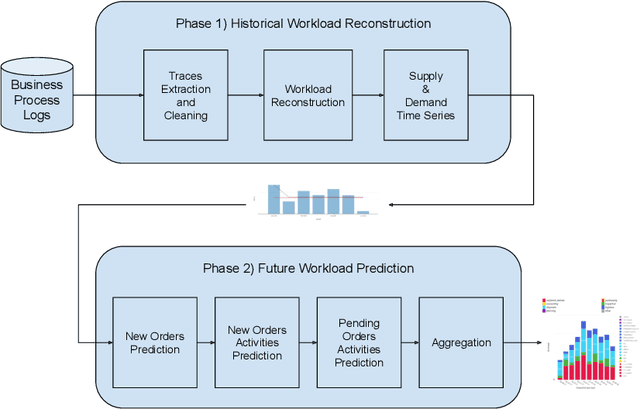
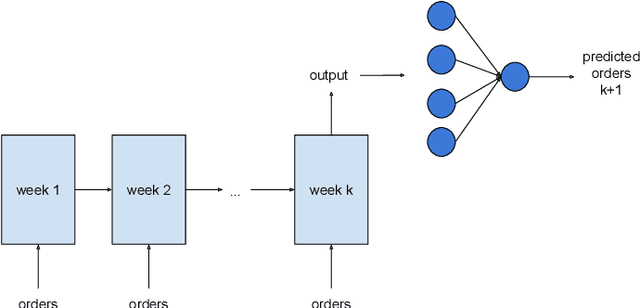
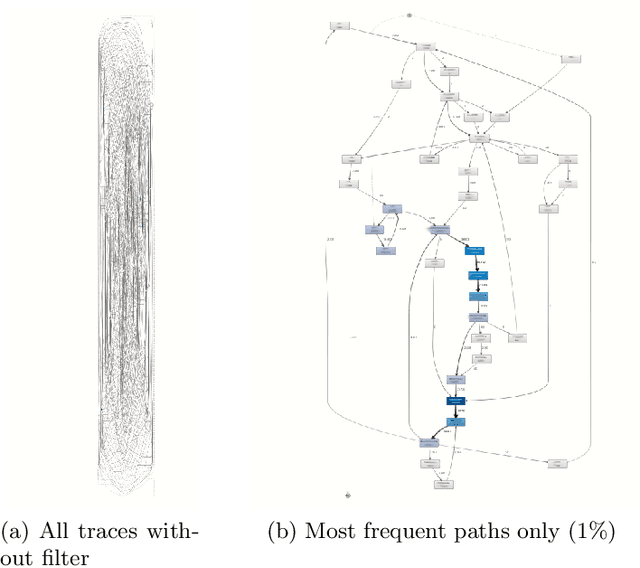

Recent advances in the interconnectedness and digitization of industrial machines, known as Industry 4.0, pave the way for new analytical techniques. Indeed, the availability and the richness of production-related data enables new data-driven methods. In this paper, we propose a process mining approach augmented with artificial intelligence that (1) reconstructs the historical workload of a company and (2) predicts the workload using neural networks. Our method relies on logs, representing the history of business processes related to manufacturing. These logs are used to quantify the supply and demand and are fed into a recurrent neural network model to predict customer orders. The corresponding activities to fulfill these orders are then sampled from history with a replay mechanism, based on criteria such as trace frequency and activities similarity. An evaluation and illustration of the method is performed on the administrative processes of Heraeus Materials SA. The workload prediction on a one-year test set achieves an MAPE score of 19% for a one-week forecast. The case study suggests a reasonable accuracy and confirms that a good understanding of the historical workload combined to articulated predictions are of great help for supporting management decisions and can decrease costs with better resources planning on a medium-term level.
Automatic Keyword Extraction from Spoken Text. A Comparison of two Lexical Resources: the EDR and WordNet
Oct 25, 2004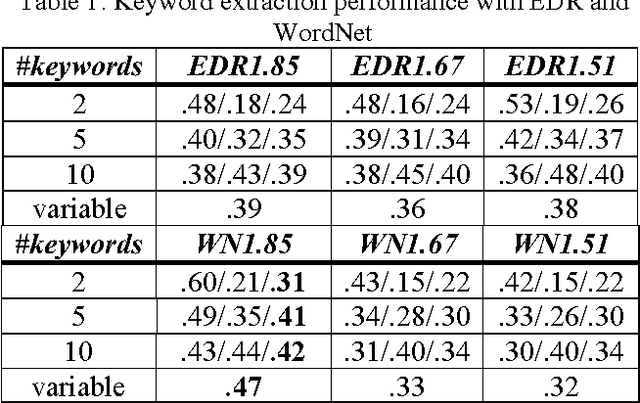
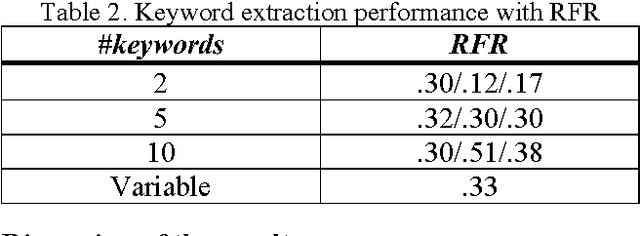
Lexical resources such as WordNet and the EDR electronic dictionary have been used in several NLP tasks. Probably, partly due to the fact that the EDR is not freely available, WordNet has been used far more often than the EDR. We have used both resources on the same task in order to make a comparison possible. The task is automatic assignment of keywords to multi-party dialogue episodes (i.e. thematically coherent stretches of spoken text). We show that the use of lexical resources in such a task results in slightly higher performances than the use of a purely statistically based method.
* 4 pages
An argumentative annotation schema for meeting discussions
Oct 25, 2004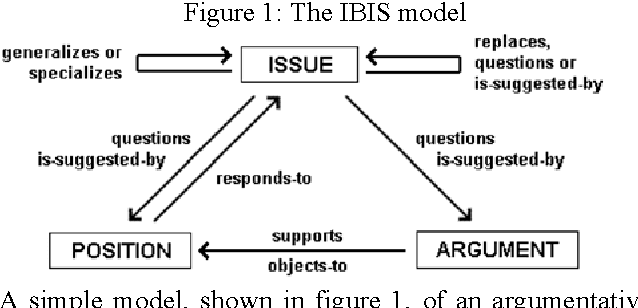
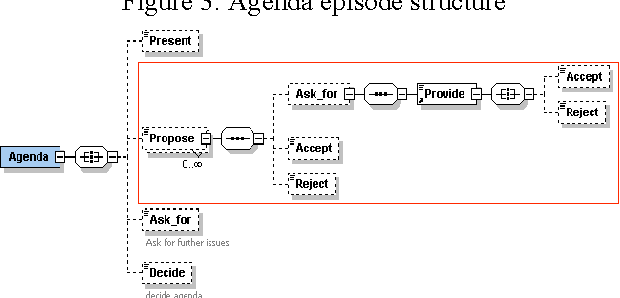
In this article, we are interested in the annotation of transcriptions of human-human dialogue taken from meeting records. We first propose a meeting content model where conversational acts are interpreted with respect to their argumentative force and their role in building the argumentative structure of the meeting discussion. Argumentation in dialogue describes the way participants take part in the discussion and argue their standpoints. Then, we propose an annotation scheme based on such an argumentative dialogue model as well as the evaluation of its adequacy. The obtained higher-level semantic annotations are exploited in the conceptual indexing of the information contained in meeting discussions.
* 4 pages
A knowledge-based approach to semi-automatic annotation of multimedia documents via user adaptation
Oct 23, 2004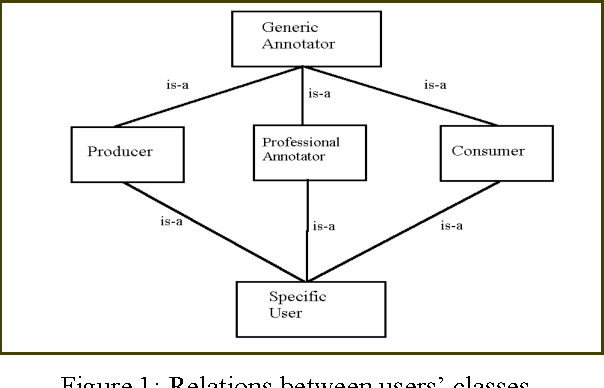
Current approaches to the annotation process focus on annotation schemas, languages for annotation, or are very application driven. In this paper it is proposed that a more flexible architecture for annotation requires a knowledge component to allow for flexible search and navigation of the annotated material. In particular, it is claimed that a general approach must take into account the needs, competencies, and goals of the producers, annotators, and consumers of the annotated material. We propose that a user-model based approach is, therefore, necessary.
* 4 pages